本教程会带领大家项目制学习,由浅入深,逐渐进阶。从竞赛通用流程与跑通最简的Baseline,到深入各个竞赛环节,精读Baseline与进阶实践技巧的学习。
千里之行,始于足下,从这里,开启你的 AI 学习之旅吧!
—— Datawhale贡献者团队
用户新增预测挑战赛:
https://challenge.xfyun.cn/topic/info?type=subscriber-addition-prediction&ch=ymfk4uU
举办方:科大讯飞
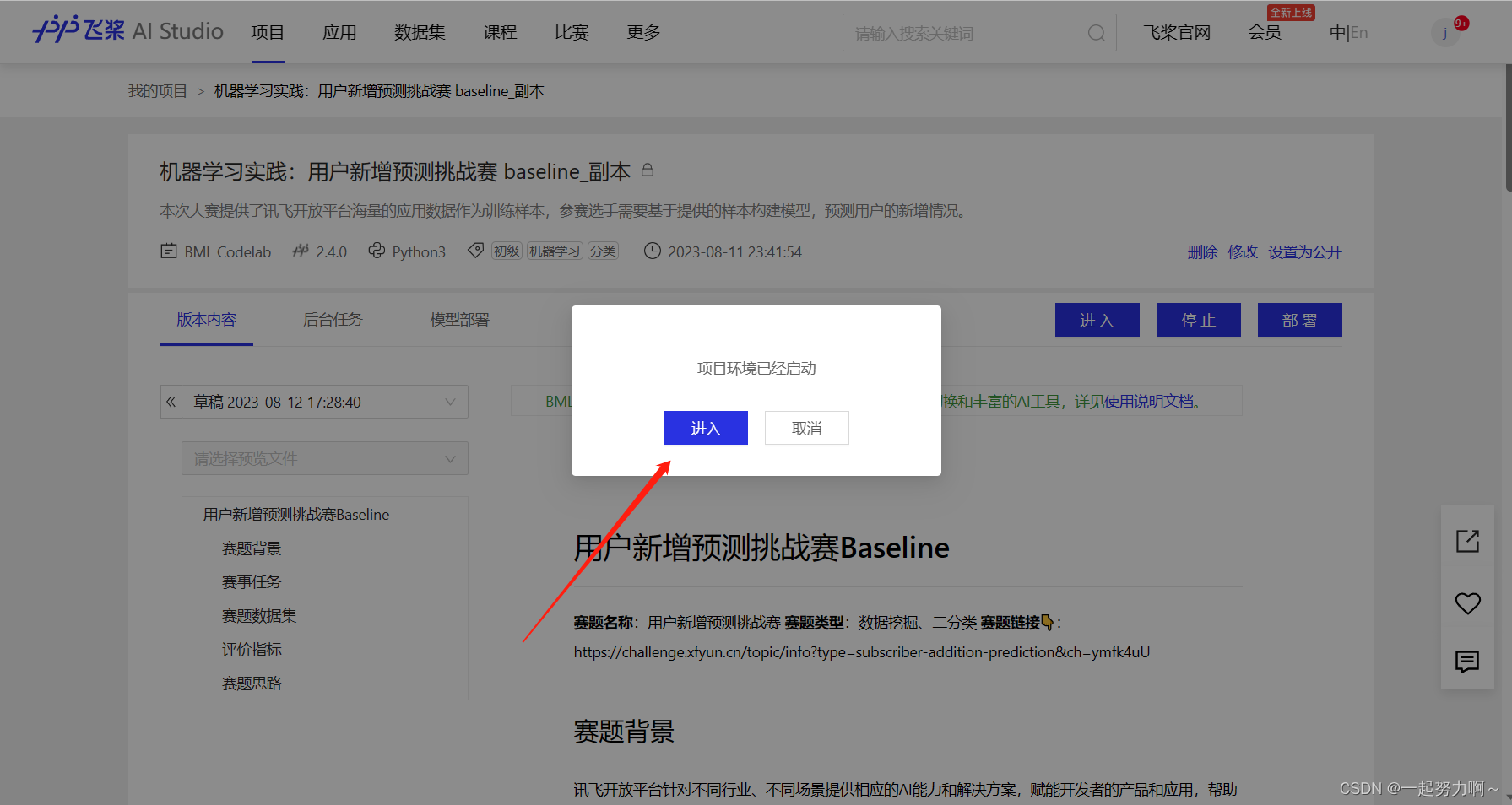
# 导入库
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier#决策树模型
# 读取训练集和测试集文件
train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv')
test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv')
# 提取udmap特征,人工进行onehot
#定义udmap_onethot()函数:该函数用于对udmap特征进行人工的one-hot编码。首先创建一个长度为9的全零向量v,然后根据输入的d的值进行判断,如果值为'unknown',则直接返回全零向量。如果值不为'unknown',则通过eval()函数将字符串转换成字典对象d,然后遍历数字1到9,检查字典中是否包含键名为'key1'、'key2'、...、'key9'的元素,如果存在,则将对应的值赋给向量v的相应位置(索引为i-1),最后返回得到的向量v。
def udmap_onethot(d):
v = np.zeros(9)
if d == 'unknown':
return v
d = eval(d)
for i in range(1, 10):
if 'key' + str(i) in d:
v[i-1] = d['key' + str(i)]
return v
#对udmap特征进行one-hot编码:通过apply()方法将udmap_onethot()函数应用到train_data['udmap']和test_data['udmap']上,将返回的数组垂直堆叠成DataFrame对象train_udmap_df和test_udmap_df,然后为这两个DataFrame设置列名。
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 编码udmap是否为空
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
# udmap特征和原始数据拼接
#通过使用.concat()函数将train_udmap_df和test_udmap_df与原始数据集train_data和test_data进行列拼接。
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 提取eid的频次特征
# 使用value_counts()函数统计train_data['eid']中每个元素的出现次数,并通过map()函数将结果映射到对应的train_data['eid_freq']和test_data['eid_freq']中。
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
# 提取eid的标签特征
# 使用groupby()函数根据eid对train_data进行分组,然后计算每个分组中target列的均值,并通过map()函数将结果映射到对应的train_data['eid_mean']和test_data['eid_mean']中。
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 提取时间戳
# 将train_data['common_ts']和test_data['common_ts']的数值类型转换为时间戳类型,指定时间单位为毫秒。然后使用.dt.hour将时间戳转换为小时数,并将结果存储在train_data['common_ts_hour']和test_data['common_ts_hour']中。
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
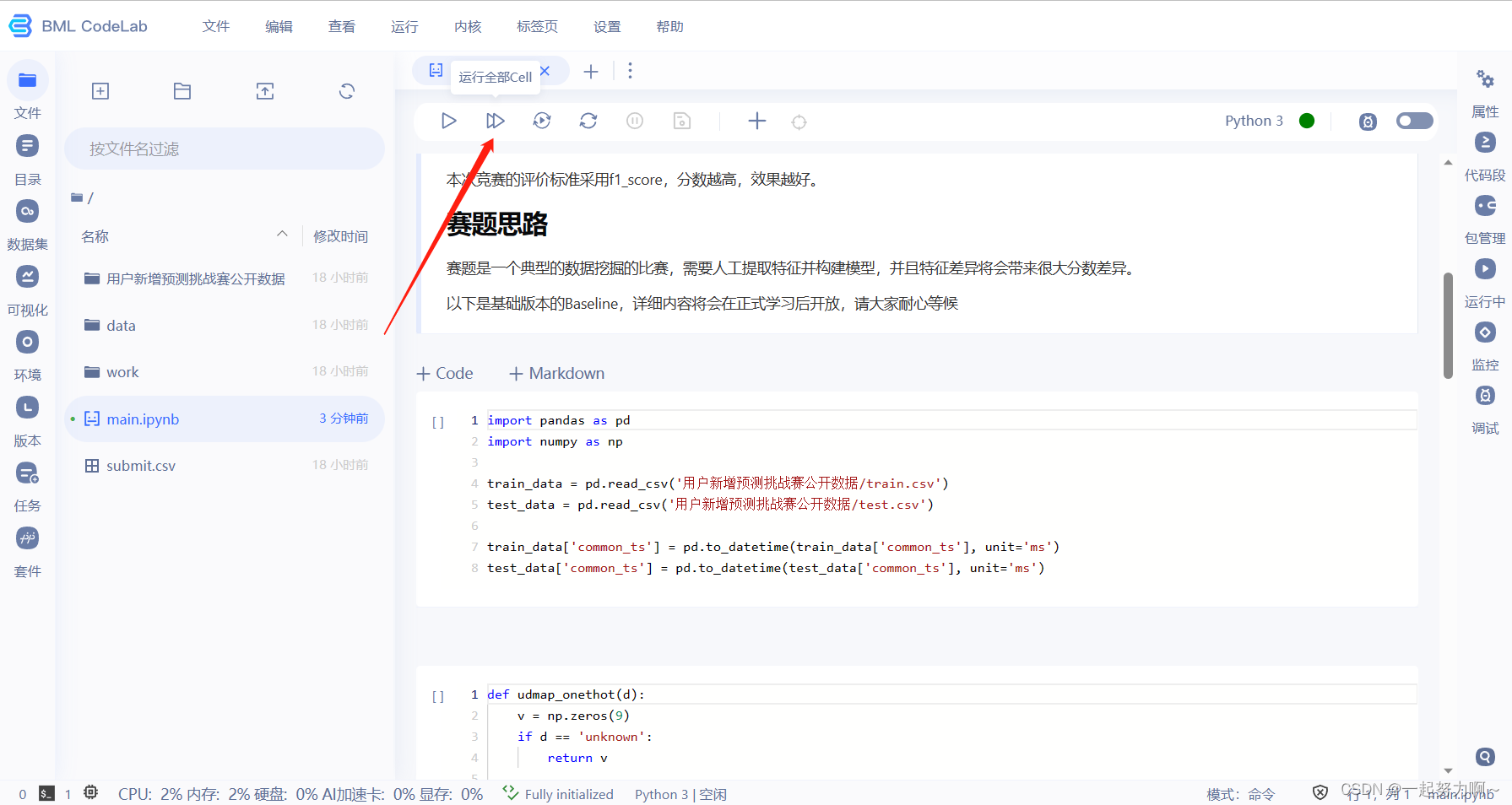
# 加载决策树模型进行训练
# 创建一个DecisionTreeClassifier分类器对象clf,使用fit()方法将训练集的特征列(去除不需要的列)与目标列作为输入进行模型训练。
clf = DecisionTreeClassifier()
clf.fit(
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
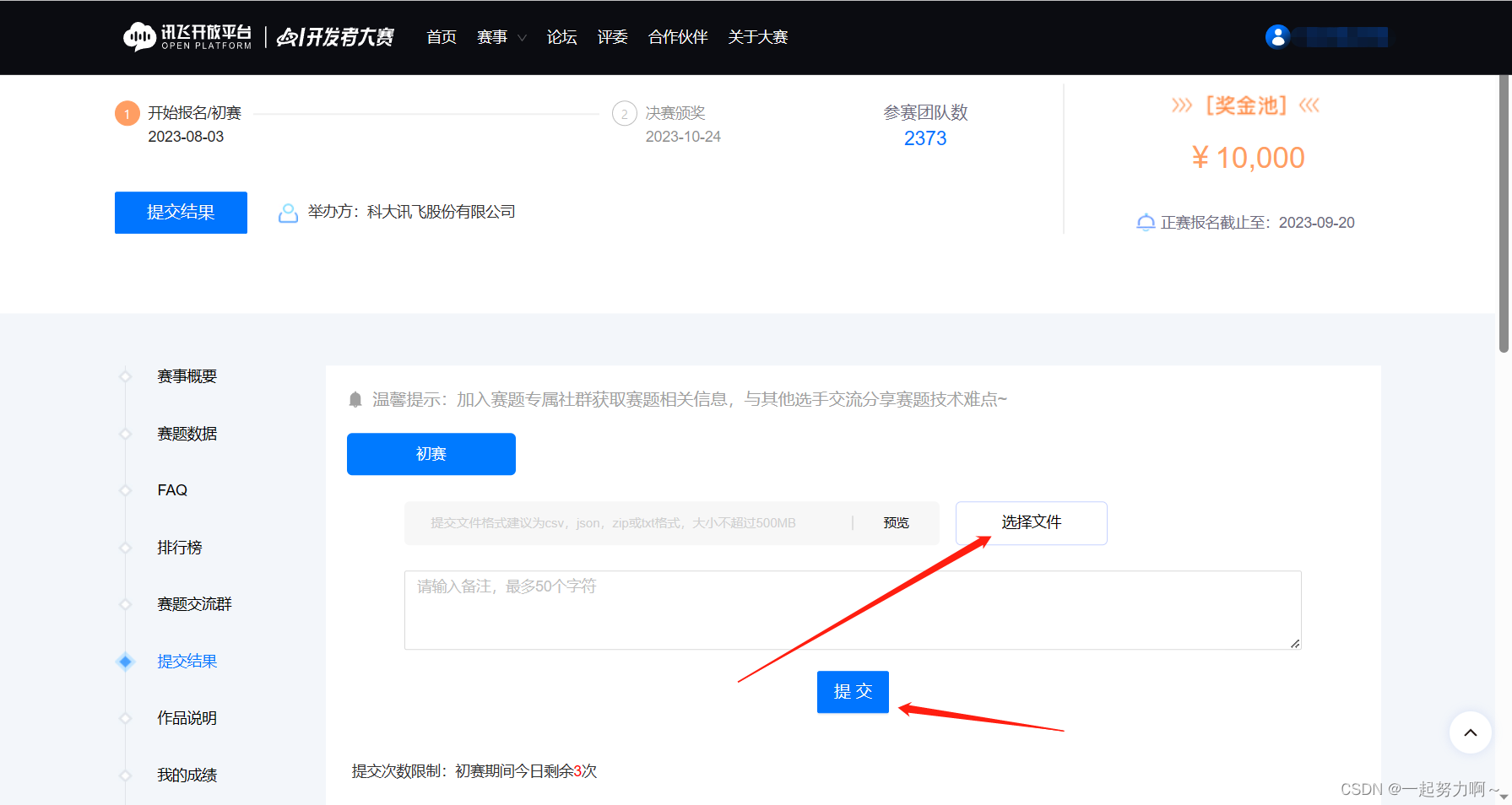
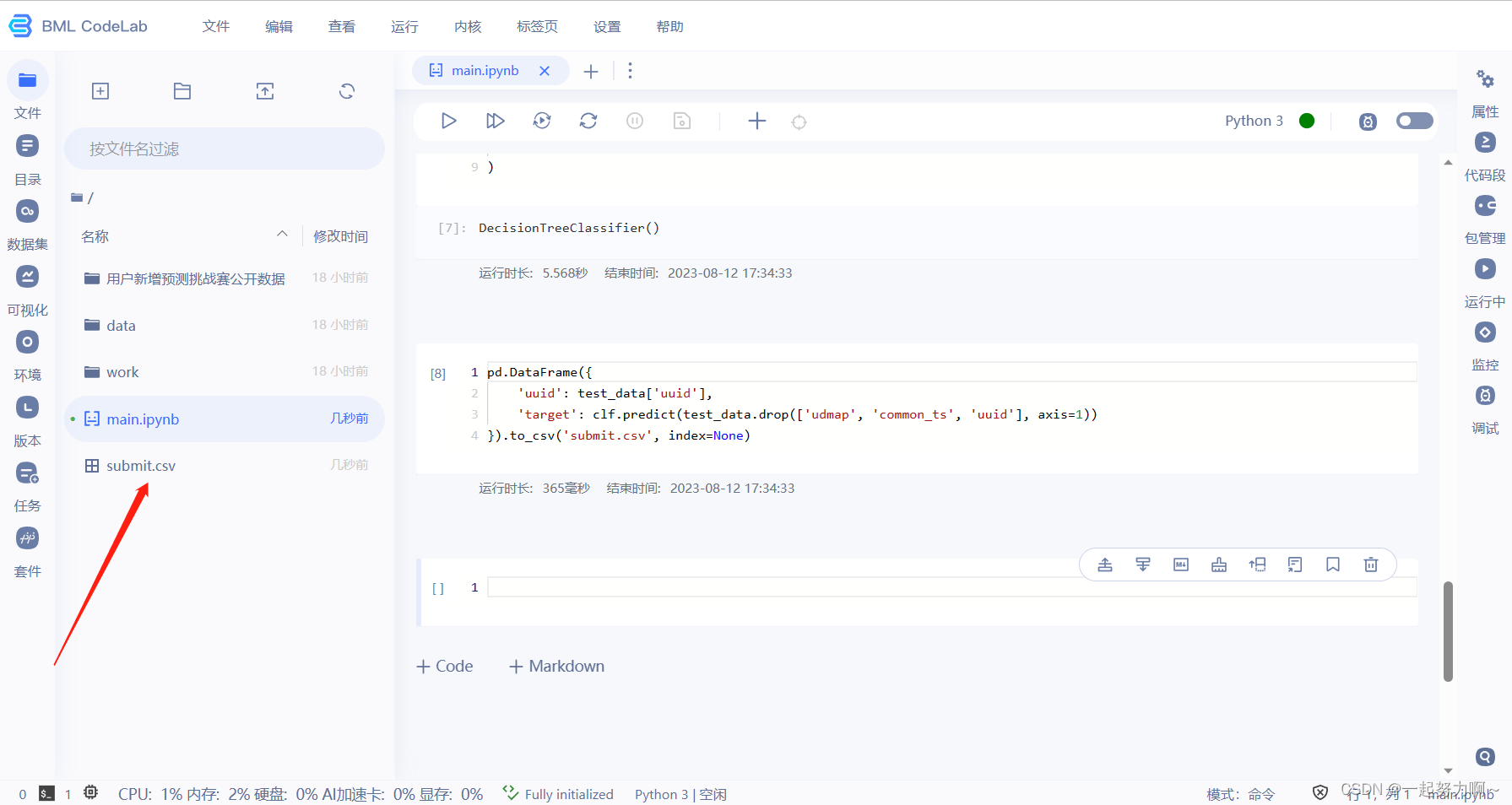
# 对测试集进行预测,将submit.csv在比赛页面提交
# 使用已训练好的分类器clf对测试集的特征列(去除不需要的列)进行预测,并生成包含预测结果的DataFrame对象。最后将预测结果保存为CSV文件submit.csv,并包括uuid和target两列。
pd.DataFrame({
'uuid': test_data['uuid'],
'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1))
}).to_csv('submit.csv', index=None)
其中使用的fit方法是scikit-learn库中训练模型的一个方法,他首先要求我们有一个模型,这里使用的是决策树模型。而fit方法是线性回归拟合,我们的目标是选择出可以使得建模误差的平方和能够最小的模型参数,即使得损失函数最小。
在解决onehot编码的分析之前,首先先解决为什么要使用独热编码的问题:显然,这里的数据离散特征的取值之间没有大小的意义,可以采用独热编码;如果离散特征的取值有大小的意义,我们则可以采用连续数值的一一映射。
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征(如成绩这个特征有好,中,差变成one-hot就是100, 010, 001)。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
这样做的好处主要有:
解决了分类器不好处理属性数据的问题
在一定程度上也起到了扩充特征的作用。
Q&A
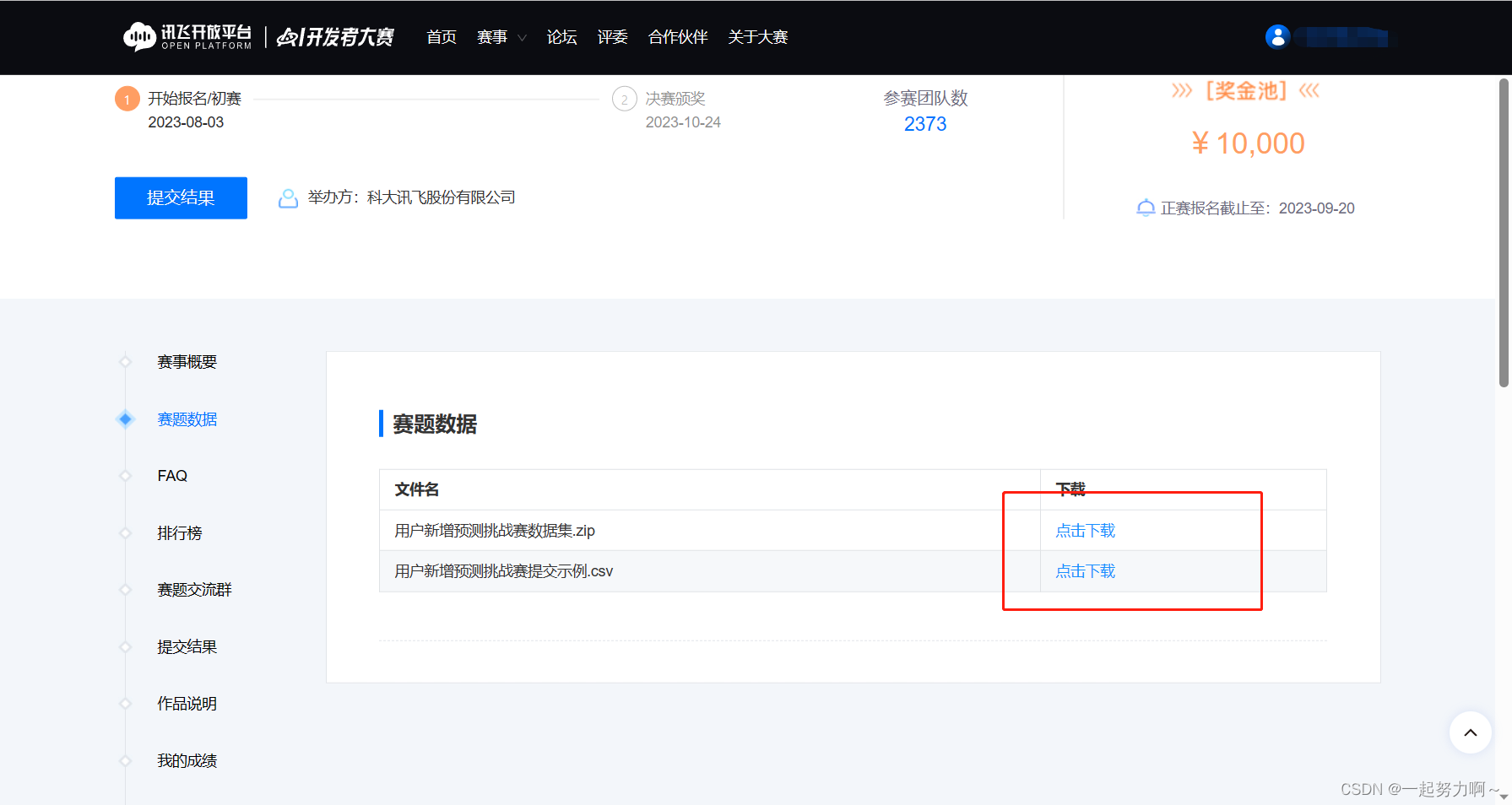
- 如果将submit.csv提交到讯飞比赛页面,会有多少的分数?
- 我提交了的成绩是0.62686
- 代码中如何对udmp进行了人工的onehot?
- 代码中通过自定义的udmap_onethot()函数对udmap进行了人工的one-hot编码。以下是udmap_onethot()函数的具体实现步骤:
1、创建长度为9的全零向量v,用于存储编码后的结果。
2、判断输入的d的值是否为’unknown’,如果是,则直接返回全零向量v。
3、如果d的值不是’unknown’,则将字符串形式的字典对象转换成实际的字典对象,可以使用eval()函数来实现这一转换。
4、遍历数字1到9(代表one-hot编码的9个类别),检查字典对象d中是否包含键名为’key1’、‘key2’、…、‘key9’的元素。
5、对于每个数字i,如果字典对象d中存在键名为’key’+str(i)的元素,则将该元素的值赋给向量v的第i-1个位置(索引为i-1)。
6、最后返回编码后得到的向量v。
通过调用udmap_onethot()函数,并将其应用到训练集和测试集的udmap列上,可以得到经过人工one-hot编码后的特征矩阵。
datawhale一位大佬的baseline讲解可以看看哦
baseline视频讲解
决策树介绍
什么是决策树模型?
决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
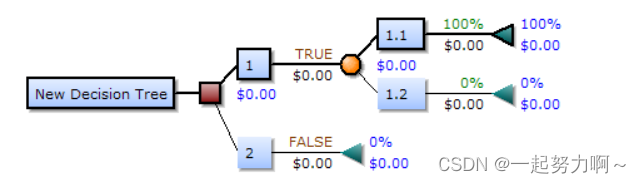
决策树的组成
根节点:第一个选择点
非叶子节点和分支:中间过程
叶子节点:最终的决策结果
决策树算法包括下面三种:

信息熵和信息增益:
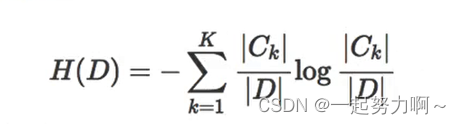
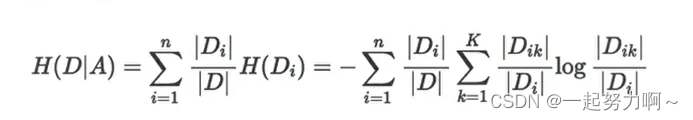
所谓的信息增益是指特征A对训练数据集D的信息增益g(D,A)定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:
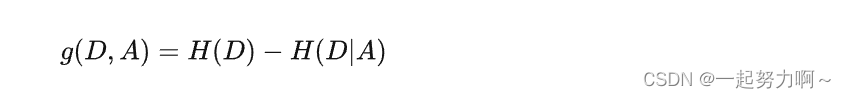
所以决策树的生成主要分以下两步,这两步通常通过学习已经知道分类结果的样本来实现。
- 节点的分裂:一般当一个节点所代表的属性无法给出判断时,则选择将这一节点分成2个
子节点(如不是二叉树的情况会分成n个子节点) - 阈值的确定:选择适当的阈值使得分类错误率最小 (Training Error)。
举例数据:
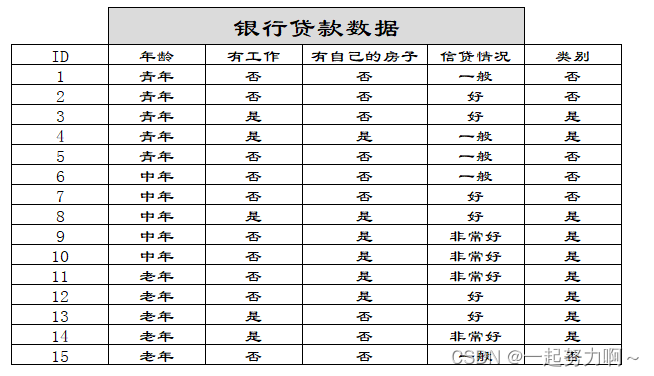
假设是二叉树的时候,决策树一般决策结果为如下图:
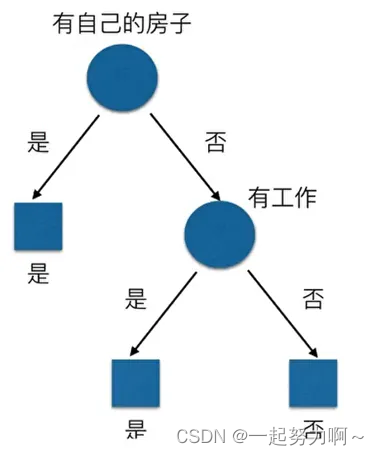
在这里,为什么有自己的房子应该放在最开始的地方呢?我们可以通过信息增益的大小可知,根据上面信息增益的公式,我们套用一下:
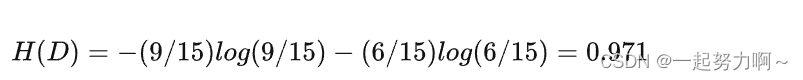 然后我们让A1,A2,A3,A4分别表示年龄、有工作、有自己的房子和信贷情况四个特征,则计算出年龄的信息增益为:
然后我们让A1,A2,A3,A4分别表示年龄、有工作、有自己的房子和信贷情况四个特征,则计算出年龄的信息增益为:

同理我们可以计算出g(D,A2)=0.324,g(D,A3)=0.420,g(D,A4)=0.363,相比较来说特征A3的信息增益最大,所以放在最前面。
决策树的优缺点:
- 优点
决策树易于理解和解释,可以可视化分析,容易提取出规则;
可以同时处理标称型和数值型数据;
比较适合处理有缺失属性的样本;
能够处理不相关的特征;
测试数据集时,运行速度比较快;
在相对短的时间内能够对大型数据源做出可行且效果良好的结果。 - 缺点
容易发生过拟合(随机森林可以很大程度上减少过拟合);
容易忽略数据集中属性的相互关联;
对于那些各类别样本数量不一致的数据,在决策树中,进行属性划分时,不同的判定准则会带来不同的属性选择倾向;信息增益准则对可取数目较多的属性有所偏好(典型代表ID3算法),而增益率准则(CART)则对可取数目较少的属性有所偏好,但CART进行属性划分时候不再简单地直接利用增益率尽心划分,而是采用一种启发式规则)(只要是使用了信息增益,都有这个缺点,如RF)。
ID3算法计算信息增益时结果偏向数值比较多的特征。
为什么要剪枝?
决策树模型过拟合风险很大,理论上可以完全分开数据。因为如果节点过多,是可以将每一个样本分在一篇叶子上的。可以在训练集取得较好的效果,但是在测试集的效果并不好。因此,在构建好决策树模型之后,要采取一个剪枝的策略,使分类标准更强而有力,也可以使树更加简洁,加速运行效率,同时提升模型的适用程度。
剪枝思路:
预剪枝(pre-pruning):提前终止某些分支的生长
后剪枝(post-pruning):生成一颗完整树,再回头从下往上“修剪”
预剪枝示例:
划分后精度变低了,则不划分进行剪枝,划分后精度没变化,遵循奥卡姆剃刀原则,不划分
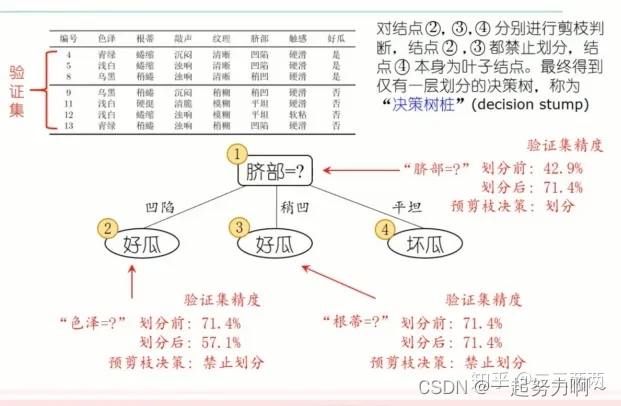
后剪枝示例:
由下到上,每一个结点都要考察是否剪,如果剪前剪后没有变化则不剪。
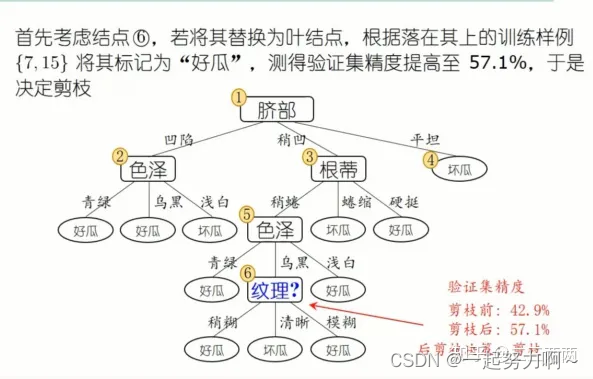
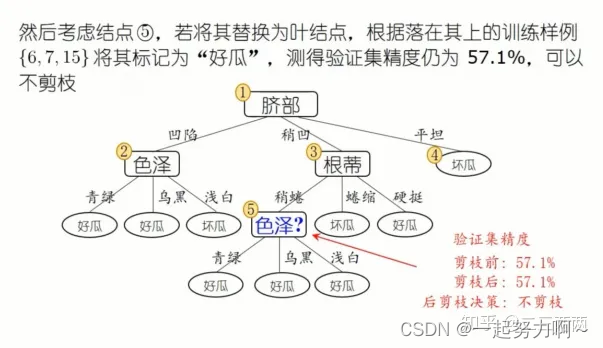
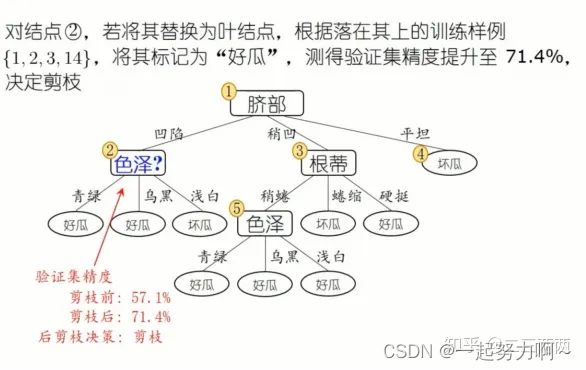
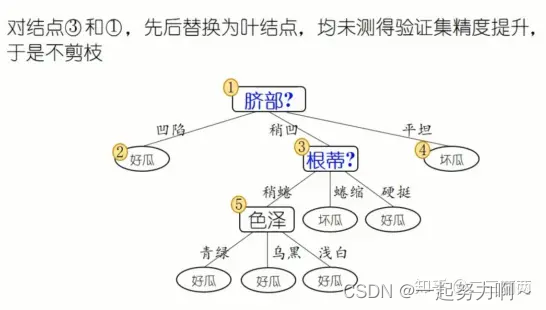
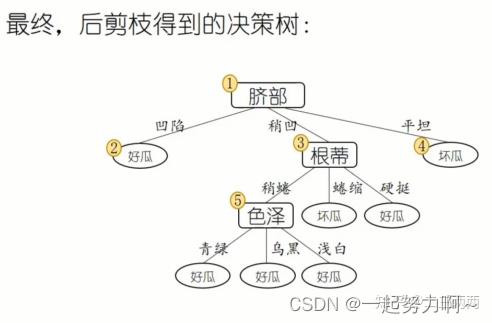
预剪枝VS后剪枝
(1)时间开销
预剪枝:测试时间开销降低,训练时间开销降低
后剪枝:测试时间开销降低,训练时间开销增加
(2)过/欠拟合风险:
预剪枝:过拟合风险降低,欠拟合风险增加
后剪枝:过拟合风险降低,欠拟合风险基本不变
(3)泛化性能:后剪枝通常优于预剪枝