前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
思维导图
正文
对 Flink 这种以流为核心的分布式计算引擎而言,数据流是核心数据抽象,表示一个持续产生的数据流,与 Apache Beam 中的 PCollection 的概念类似。
在 Flink 中使用 DataStream 表示数据流, DataStream 是一种逻辑概念,并不是底层执行的概念。
DataStream 上定义了常见的数据处理操作 API (转换为 Transtormation ),同时也具备自定义数据处理两数的能力,当 DataStream 提供的常见操作不满足需求的时候,可以自定义数据处理的逻辑。
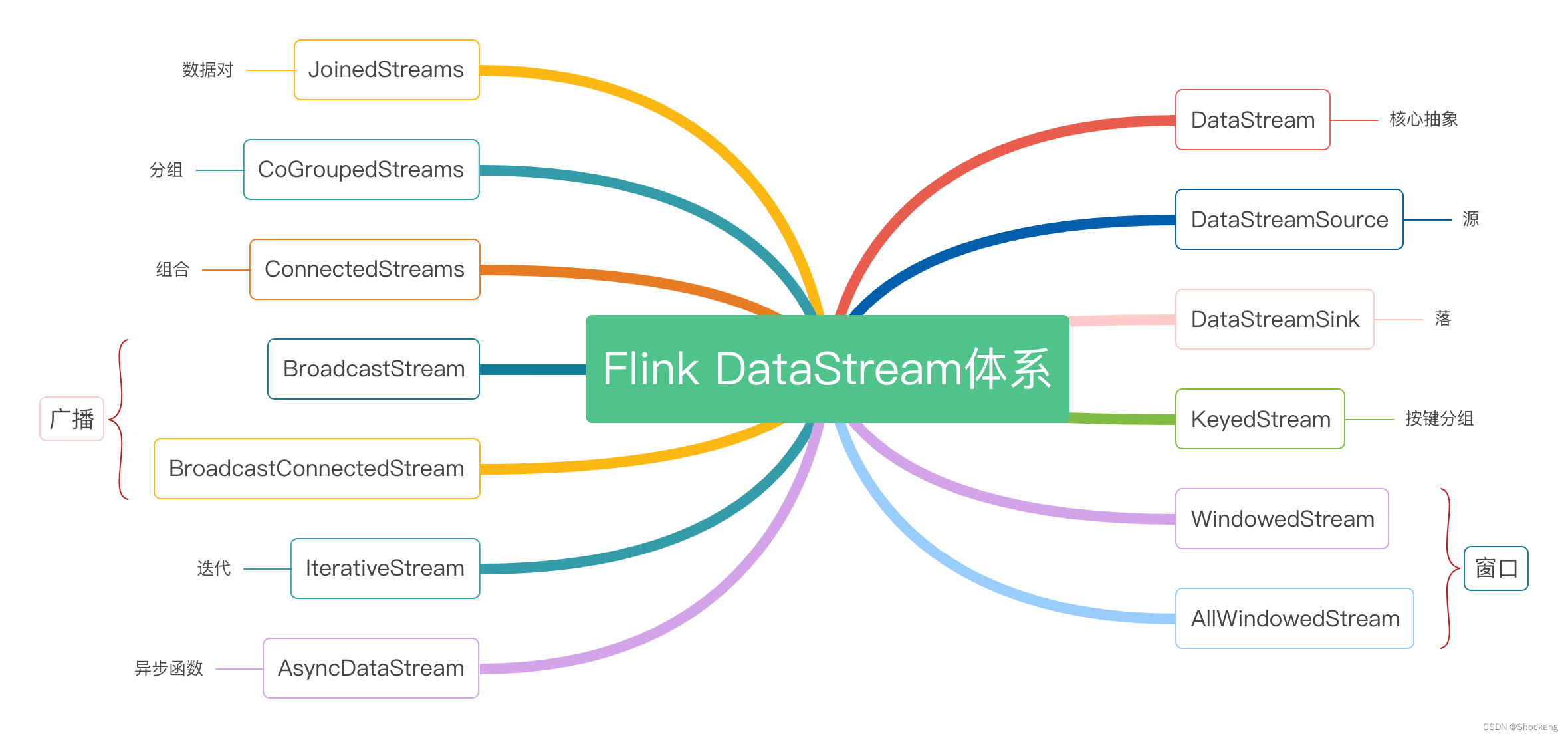
DataStream 体系如下图所示。

DataStreamSource 本身就是一个 DataStream。DataStreamSink 、 AsyncDatastream 、 BroadcastDataStream 、 BroadcastConnectedDataStream 、 QueryableDataStream 都是对一般 DataStream 对象的封装,在 DataStream 实现特定的功能,接下来对这些 DataStream 一一进行介绍。
DataStream是 Flink 数据流的核心抽象,其上定义了对数据流的一系列操作,同时也定义了与其他类型 DataStream 的相互转换关系。 每个 DataStream 都有一个 Transformation 对象,表示该 DataStream 从上游的 DataStream 使用该 Transformation 而来。DataStreamSource是 DataStream 的起点, DataStreamSource 在 StreamExecutionEnvironment 中创建,由 StreamExecutionEnvironment.addSourcce ( SourceFunction )创建而来,其中 SourceFunction 中包含了 DataStreamSource 从数据源读取数据的具体逻辑。DataStreamSink数据从 DatasourceStream 中读取,经过中问的一系列处理操作,最终需要写出到外部存储,通过 DataStream.addSink(sinkFunction)创建而来,其中 SinkFunction 定义了写出数据到外部存储的具体逻辑。KeyedStream用来表示根据指定的 key 进行分组的数据流。 一个 keyedStream 可以通过调用 DataStream.keyBy()来获得。 而在 KeyedStream 上选行任何 Transformation 都将转变回 DataStream 。 在实现中, KeyedStream 把 key 的信息写人了 Transformation 中。 每条记录只能访问所属 key 的状态,其上的聚合两数可以方便地操作和保存对应 key 的状态。WindowedStream & AllWindowedStreamWindowedStream 代表了根据 key 分组且基于 WindowAssigner 切分窗口的数据流。 所以 WindowedStream 都是从 KeyedStream 衍生而来的,在 WindowedStream 上进行任何 Transformation 也都将转变回 DataStreamJoinedStreams & CoGroupedStreamsJoin 是 CoGroup 的一种特例, JoinedStreams 底层使用 CoGroupedStreams 来实现。
Join 和 CoGroup 两者的区别如下:CoGrouped 侧重的是 Group ,对数据进行分组,是对同一个 key 上的两组集合进行操作,可以编写灵活的代码来实现特定的业务功能。 Join 侧重的是数据对,对同一个 key 的每一对元素进行操作。 CoGroup 更通用,但因为 Join 是数据库上常见的操作,所以在 CoGroup 基础上提供 Join 的特性。 JoinGroup 和 CoGroup 两者都是对特续不断地产生的数据做运算,但是又不能无限地在内存中持有数据,对所有的数据进行 Join 的笛卡儿积操作理论上不可行(理论上内存不足可以刷出到磁盘,反复的硬盘读写会导致性能变得很差),所以在底层上,两者都基于 Window 实现。
ConnectedStreams表示两个数据流的组合,两个数据流可以类型一样,也可以类型不一样。 ConnectedStreams 适用于两个有关系的数据流的操作,共享 State。 一种典型的场景是动态规则数据处理。 两个流中一个是数据流,一个是随着时间更新的业务规则,业务规则流中的规则保存在 State 中,规则会持续更新 State。 当数据流中的新数据到来时,使用保存在 State 中的规则进行数据处理。BroadcastStream & BroadcastConnectedStreamBroadcastStream 实际上是对一个普通 DataStream 的封装,提供了 DataStream 的广播行为。 BroadcastConnectedStream 一般由 DataStream / KeyedDataStream 与 BroadcastStream 连接而来,类似于 ConnectedStream 。IterativeStream是对一个 DataStream 的迭代操作,从逻辑上来说,包含 IterativeStream 的 Dataflow 是一个有向有环图,在底层执行层面上, Flink 对其进行了特殊处理。AsyncDataStream是个工具,提供在 DataStream 上使用异步函数的能力。