随机森林(RandomForest)
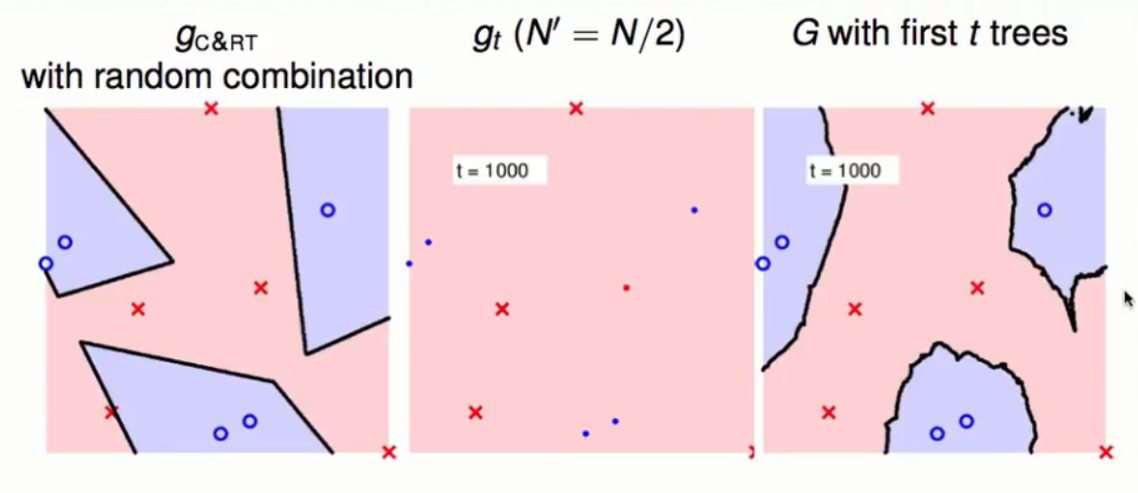
集成学习中的Bagging通过bootstrapping的方式进行抽取不同的资料从每一堆资料中学得一个小的模型g,然后再将这些小的模型进行融合进而得到一个更为稳定的大的模型G。决策树模型通过递归的方式按照某些特征进行分支得到更小的树,最后通过检测不纯度来决定是否停止切割。这个模型受资料影响较大,所以得到的模型不够稳定。如果将这两种学习模型合在一起就会构成一个既稳定又强大的模型就是随机森林。其中随机性来自于Bagging中的bootstrapping,森林也就是树的组合。
随机森林的特点
①由于bootstrapping可以使用同一笔资料并行的去做,再加上C&RT的效率又非常高所以这个演算法在现代的计算架构下的效率非常高。
②由于C&RT演算法能够轻松的解决数字特点和类别特点问题,所以RF也会继承这些特点。
③C&RT对资料很敏感同时也很容易过拟合,而在加上bagging的融合之后RF整体会得到很好地优化。
让随机森林更加随机
以前的不同的模型g的产生是通过bootstrapping得到不相同的资料训练而得到的。现在有一种新的方法就是我们要通过不同的特征去分割这些资料得到不同的g。比如一笔输入资料欧100个维度我们只随机选取其中的10个维度(相当于一个投影的动作)去得到一个g这样通过更换不同的特征就能得到不同的g。通常我们选取的维度要远小于全部的维度这样会更有效率。通缩的讲就是以前切一刀需要看100个维度现在只需要看10维就够了。通常在做每一次的分支的时候都会做一次投影的动作去使得到的树更加不同。像这样的投影也能够用在其他的演算法上。
投影策略
在做投影的时候我们常常可能会将这些特征投影到我们在意的那些方向。实务上我们可以将原始的资料投影到随机的任意方向(也就是欧几里得空间中自然的一些方向)。通常我们会得到一些较小的维度,我们会将这些维度结合起来去做切割。这样RF中导出充满了随机。

随机森林的自检测
回顾bootstrapping
Boostrapping是一种有放回的抽取资料来获得样本的方式,由于是有放回所以有的资料就不会被抽取到。通常通过极限的运算我们会得到大约有1/3的资料没有被抽到。我们称这些资料为OOB(Out Of Bag)的资料。
OOB的资料与模型检测
既然OOB资料没有被用过所以RF天然的可以使用这些资料做模型检测。由于每一个用bootstrap得到的样本都会训练出一个小的模型g来,所以对于一个样本的OOB资料可以对g做模型检测。但是我们最终要的是融合后模型的衡量结果所以我们又使用了一个新的错误衡量方式。
①将单个的一笔资料拿出来然后再获得在所有次抽样中没有用到该资料的所有小的模型。
②将这些小的模型融合起来得到一个大的模型Gn,让这笔资料对这个大模型进行错误衡量。
③然后再次拿出其它的一笔资料来重复上述步骤。
④最后计算Gn错误衡量的平均值作为G的模型检测结果。
这种检测方式叫做自检测,通常在模型训练完成后就能够得到一个RF的评价而且在实务上非常准确。
特征选择
多余的特征
我们在识别一个物体时往往是根据这个物体非常明显的特征,还有一点很重要的就是我们忽略了那些不重要的特征。比如说判断一个物体只不是一个人我们是不会去看这个物体是否带有一个耳环。这就要求我们进行特征的选择,我们要拿着那些最重要的特征去做决策。与此同时还有一个选择标准就是一些等价的特点,比如说同时出现了你的生日和年龄我们会去掉其中的一个特征。
特征选择的优点:
①由于特征减少了所以显得高效。
②由于有了有代表性的特征所以更加容易泛化,不会受到其它维度杂讯的影响(比如说判断一个人的时候回去看是否有耳环)。
③拿着这些特征更容易去解释一些现象。
特征选择的缺点:
①我们在训练模型的时候会有一个选择的步骤在前面,选择也会给我们带来代价。构成了一个组合优化的问题。
②会选择到那些看似很好但是其实不好的维度这样的话就会过拟合。
③如果发生了过拟合的维度我们也就会有错误的解释。
事实上在决策树做分支或逐步增强法单维度切割的时候就间接的进行了维度选择(怎样决策更好)。
根据重要性选择维度
假设我们要从10000个维度选择300个出来,我们就要选择对此次决策最重要的300维出来。我们会将所有的维度列出来然后再给它们排个序最后选择。其中的一个方法就是利用线性模型来选择重要的维度。

当我们在一个样本上做好一个线性模型的时候通常会得到不同大小的权重,用这些权重的大小去代表这个维度的重要性是一个非常不错的方法。然后根据这些大小排序最后选择300个出来。但遗憾的是RF是一个非线性的模型非线性的模型的特征选择比较困难。但好消息是RF的特征使得它的特征选择不是那么困难。
置换检测
置换检测的基本思想就是当改变一个重要维度的取值时模型的表现会发生很大的改变。比如说一个表现不错的模型在它重要的维度上将原来的资料换成是一个杂讯这时这个模型会表现的很差。相反如果在不重要的维度上将杂讯埋进去对模型的整体表现没有太大的影响。那么怎么样去污染某一个维度的资料?
为了保持与整体资料的分布相同我们选择的污染资料也是来自于样本,只是将样本中的一些资料的顺序打乱来模拟样本的随机性。当我们要污染某一个维度的资料时我们就随机的将这笔资料中的资料进行“洗牌”然后观察该维度的变化对整体模型表现的影响。
模型的衡量
如何评价模型变化前后的表现。首先从原始数据中得到模型然后进行自我检测得到一个评价,然后使用置换后的数据训练一个模型再自我检测得到一个评价,最后对比两个评价。但是我们不想做两次的训练,原始的作者就想出了一招将置换后模型的自我检测等价于原始的模型在置换后的资料中的OOB的资料上检测的表现(原始的作者还特别强调这些OOB的资料也最好来自于原始资料中的OOB资料这样的模型检测更为准确)。我们只是在验证的时候做置换动作而不去真正的实现第二个模型,然后检查表现的波动性。实务上这种特征选择常常用于其它非线性模型训练中做一个预选择。

RF的表现
实务上它要比决策树的模型更为平滑与强固,在分开资料的时候同时也做了类似于SVM中的宽的边界。但是它有一个缺点就是模型本身具有随机性理论上一个RF包含越多的树就会越趋向于稳定。