在最近学习中,用Adam作为优化器,在训练时打印学习率发现学习率并没有改变。这好像与之前理解的自适应的学习率有所矛盾?
Adam的理论知识
Adam论文:https://arxiv.org/pdf/1412.6980.pdf
 上图就是Adam优化算法在深度学习应用于梯度下降方法的详细过程,有一些参数要做出说明:
上图就是Adam优化算法在深度学习应用于梯度下降方法的详细过程,有一些参数要做出说明:
 具体可以通过https://blog.csdn.net/sinat_36618660/article/details/100026261来理解Adam的原理。
具体可以通过https://blog.csdn.net/sinat_36618660/article/details/100026261来理解Adam的原理。
问题1 指数滑动平均是什么?
Exponential Moving Average (EMA) 指数滑动平均指各数值的加权系数随时间呈指数式递减,越靠近当前时刻的数值加权系数就越大。
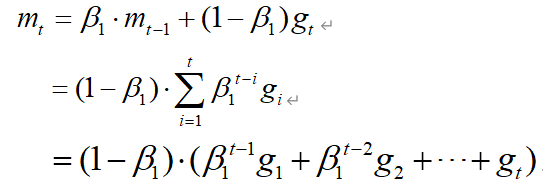
以 m t m_t mt为例,从上面的推导可以看到,越远离时刻t,其梯度所占的比重就越小,在梯度在不断的更新的过程中,虽然使用了历史梯度,但是在不同时刻的梯度对当前 m t m_t mt贡献不同,离时刻t越近,对 m t m_t mt的影响就越大,离时刻t越远,对 m t m_t mt的影响就越小。
问题2 为什么需要进行修正?
(1)通俗解释:
当对 m t m_t mt不进行修正时( β 1 = 0.9 \beta_1=0.9 β1=0.9):
m 0 m_0 m0=0
m 1 m_1 m1= β 1 ∗ m 0 + ( 1 − β 1 ) ∗ g 1 \beta _1* m_0+(1-\beta_1)*g_1 β1∗m0+(1−β1)∗g1= 0.1 g 1 0.1g_1 0.1g1
m 2 m_2 m2= 0.9 ∗ 0.1 ∗ g 1 + 0.1 ∗ g 2 0.9*0.1*g_1+0.1*g_2 0.9∗0.1∗g1+0.1∗g2= 0.09 g 1 + 0.1 g 2 0.09g_1+0.1g_2 0.09g1+0.1g2
m 3 m_3 m3= 0.081 g 1 + 0.09 g 2 + 0.1 g 3 0.081g_1+0.09g_2+0.1g3 0.081g1+0.09g2+0.1g3
依次类推,我们可以看到由于 m 0 m_0 m0=0,导致, m t m_t mt均向0进行偏置,也会离 g t g_t gt越来越远。
(2)理论公式解释:
从上面 m t m_t mt的更新公式可以看出来, m t m_t mt相当于是梯度 g t g_t gt一阶距估计,所以我们计算 m t m_t mt的期望:
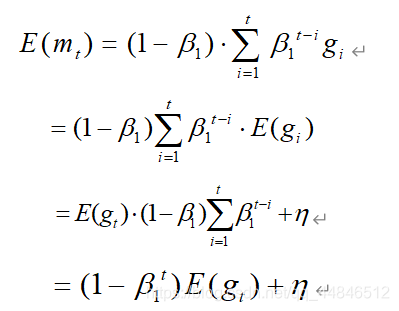
从上面的公式可以看到,需要将 m t m_t mt修正为 m t / ( 1 − β 1 t ) m_t/(1-\beta_1^t) mt/(1−β1t) ,才能近似认为 m t m_t mt为梯度 g t g_t gt的无偏距估计。同样的思路可以解释 v t v_t vt的修正。
问题3 学习率是如何变化的?
在Adam论文中指出可以将下面三行公式:

等价替换成:
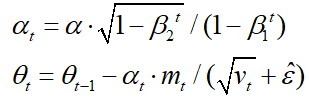
在pytorch源代码中也是按照上述这种写法(附在最后面)。
那这样写是不是说明学习率的变化是由 α 1 − β 2 t / ( 1 − β 1 t ) \alpha \sqrt{1-\beta_2^t}/(1-\beta_1^t) α1−β2t/(1−β1t)来决定呢,那这样还能称之为自适应的学习率吗?
我们知道梯度下降法的定义公式:
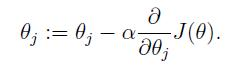
按照梯度下降法的定义公式,我们可以将参数更新公式写成:
θ t = θ t − 1 − α v t ^ + ε ∗ m t ^ \theta_t=\theta_{t-1}- {\frac{\alpha}{\sqrt{\hat{v_t}}+\varepsilon}}*\hat{m_t} θt=θt−1−vt^+εα∗mt^
其中,将 m t m_t mt视为梯度 g t g_t gt的一阶距估计,那么 α v t ^ + ε {\frac{\alpha}{\sqrt{\hat{v_t}}+\varepsilon}} vt^+εα可以看作在t时刻,参数 θ t \theta_t θt 的学习率。从上述公式也可以看出来,对于不同的参数,在每一时刻都会有不同的学习率,所以很难对其进行可视化。
最后附上Adam源码
我通过pytorch1.2/lib/python3.7/site-packages/torch/optim/找到adam.py文件,下面是代码:
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data
if grad.is_sparse:
raise RuntimeError('Adam does not support sparse gradients, please consider SparseAdam instead')
amsgrad = group['amsgrad']
state = self.state[p]
# State initialization
if len(state) == 0:
state['step'] = 0
# Exponential moving average of gradient values
state['exp_avg'] = torch.zeros_like(p.data)
# Exponential moving average of squared gradient values
state['exp_avg_sq'] = torch.zeros_like(p.data)
if amsgrad:
# Maintains max of all exp. moving avg. of sq. grad. values
state['max_exp_avg_sq'] = torch.zeros_like(p.data)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
if amsgrad:
max_exp_avg_sq = state['max_exp_avg_sq']
beta1, beta2 = group['betas']
state['step'] += 1
if group['weight_decay'] != 0:
grad.add_(group['weight_decay'], p.data)
# Decay the first and second moment running average coefficient
exp_avg.mul_(beta1).add_(1 - beta1, grad)
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
if amsgrad:
# Maintains the maximum of all 2nd moment running avg. till now
torch.max(max_exp_avg_sq, exp_avg_sq, out=max_exp_avg_sq)
# Use the max. for normalizing running avg. of gradient
denom = max_exp_avg_sq.sqrt().add_(group['eps'])
else:
denom = exp_avg_sq.sqrt().add_(group['eps'])
bias_correction1 = 1 - beta1 ** state['step']
bias_correction2 = 1 - beta2 ** state['step']
step_size = group['lr'] * math.sqrt(bias_correction2) / bias_correction1
p.data.addcdiv_(-step_size, exp_avg, denom)
return loss
以上均是我个人的理解,如果各位有更好的想法可以留言,共同学习进步!