An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
CNN模型落地需要考虑精度和速度,常见的ResNet系列、DenseNet系列主要以精度为主,而MobileNet系列、ShuffleNet系列以效率优先。有没有一个兼备精度和效率的模型呢,今天看的这个VoVNet就是这样的一个模型。让我们一起去学习一下吧。
1. 模型评价指标
在介绍VoVNet网络之前,我们可以先了解一下模型精度和速度评价指标及其含义(以目标检测为例),以便我们之后对多个模型性能比较。
精度指标
- mAP
mAP全称是mean Average Precision,这里的Average Precision,是在不同recall下计算得到的。具体介绍这里不详述,可参考。
mAP越大,说明模型检测精度越高。
速度指标
- FPS
含义为Frame Per Second,即每秒处理的图像帧数。FPS越大,说明模型推理速度越快。 - Conputation Efficiency(GFLOPs/s)
计算效率,即一秒钟计算多少个F的计算量,该指标代表的是GPU实际的计算量。有的模型设计的好,可以充分发挥GPU的计算潜力(VoVNet可以让GPU一秒计算400G次),而有的模型设计的不好,无法发挥GPU的计算潜力(MobileNet让GPU一秒计算37G次)。GPU计算优势在于它的并行计算,当计算的tensor较大时会充分发挥GPU的计算能力。如果将一个较大的卷积拆成几个小的卷积,尽管效果相同,但是GPU计算低效。相比FLOPs,我们更应该关注FLOPs per Second,即用总的FLOPs除以总的GPU推理时间,该指标值越高,说明GPU利用率越高。
Memory Access Cost(MAC)
内存访问成本,对于CNN来说,内存访问比计算更能增加能耗,如果网络中特征比较大,甚至在同等模型大小下内存访问成本为增加,所以要充分考虑CNN层的MAC。在shuffleNetV2论文中给出计算卷积层MAC的方法:
M A C = h w ( c i + c o ) + k 2 c i c o MAC = hw(c_i + c_o) + k^2c_ic_o \\ MAC=hw(ci+co)+k2cico
这里的 k , h , w , c i , c o k, h, w, c_i,c_o k,h,w,ci,cok, h, w, c_i,c_o 分别为卷积核大小,特征高和框,以及输入和输出的通道数。卷积层的计算量 B = k 2 h w c i c o B=k^2hwc_ic_o B=k2hwcicoB=k^2hwc_ic_o,如果固定 B B BB 的话,那么有:
M A C ≥ 2 h w B k 2 + B h w MAC \geq 2\sqrt{\frac{hwB}{k^2}} + \frac{B}{hw} \\ MAC≥2k2hwB+hwB
根据均值不等式,可以知道当输入和输出的channel数相同时 MAC 才取最小值,此时的设计是最高效的。
- 能用3x3的卷积就不要用1x1卷积,因为1x1卷积计算效率低,而且一般用1x1卷积都是用来改变通道数的,导致访问成本增加;
- 特征图能用大的,就不用小的,因为大的特征图计算效率高。
内存指标
- FLOPs(G)
floating point operations 指的是浮点运算次数,理解为计算量,可以用来衡量算法/模型的复杂度。计算过程见参考。 - Param(M)
模型的参数量(下图参考)

- Memory footprint(MB)
内存需求,在计算机上训练模型需要做矩阵计算,这个过程需要耗费内存。 - Energy Efficiency(J/img)
能耗高效性,反映识别一张图片要消耗的能量。
2. DenseNet模型简介(参考)
VoVNet网络基本是在DenseNet网络基础上改进的,即超越了DenseNet模型精度,又加快模型推理时间,高效利用GPU。所以在介绍VoVNet网络之前,我们先了解一下DenseNet网络结构。
为了追求更高精度,研究人员往往会不断增加网络深度,如ResNet-18,50,101,甚至到1000层。而在不断加深网络的同时,梯度经过这么长的路径反向传播到输入时可能会消失,有没有网络可以让网络又深梯度也不会消失呢。DenseNet提出了一种简单的方法,直接通过将前面所有层的特征与后面层的特征建立密集连接来对特征进行重用来解决这个问题。下图展示部分网络结构:
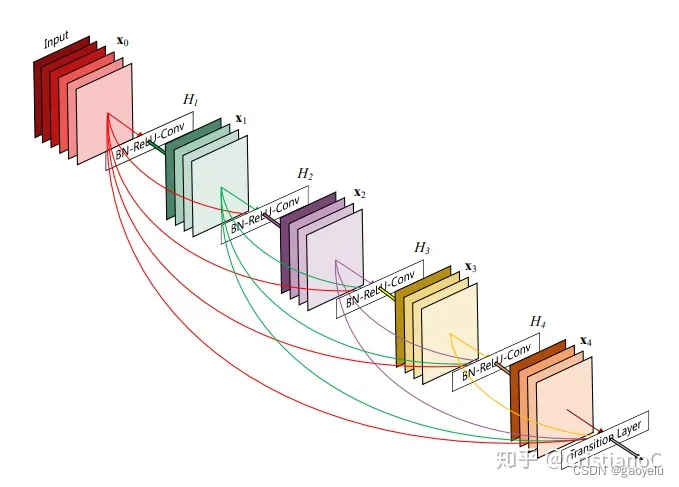
下图是DenseNet网络详细结构图:
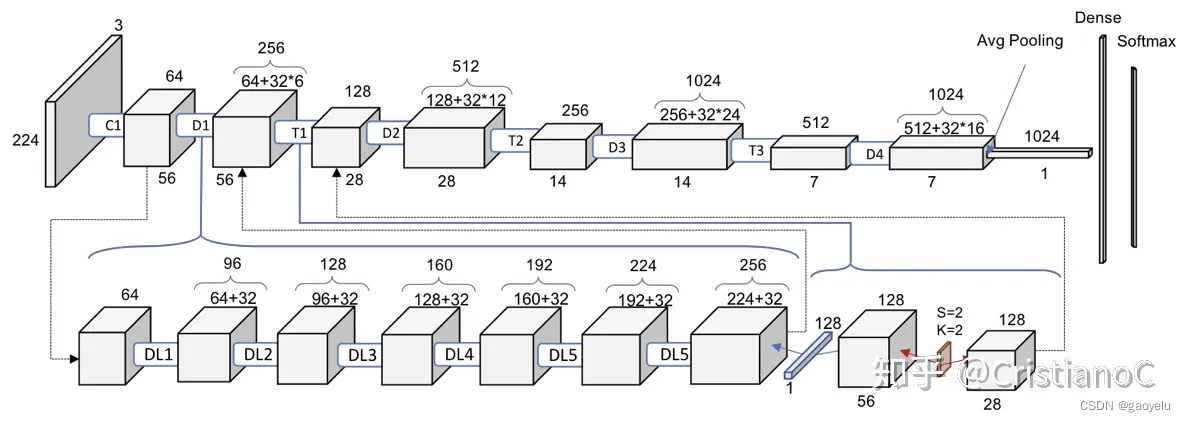
从DenseNet网络结构上看,这种密集连接使得各层的各个尺度特征都能被提取,这也是它精度高的原因。密集的连接有助于梯度回传。
但是限制FLOPs和模型参数,每层的输出通道是固定的,这样导致输入和输出通道不一致,MAC增加。另外,由于前面层的通道的不断累加,要输出固定通道,就必须使用1x1卷积压缩通道数,使得GPU利用率不高,所以即使DenseNet模型的GLIOPs和模型参数量都不大,但是推理并不高效。
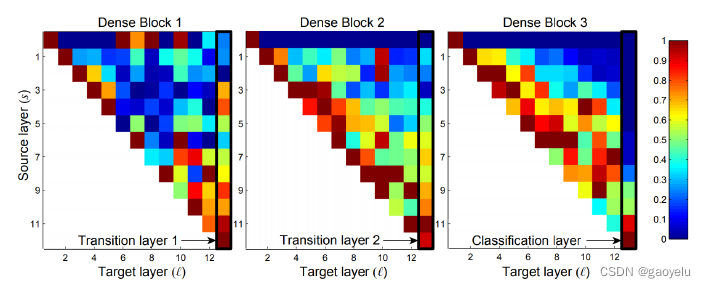
上图是DenseNet各个卷积层之间的相互关系大小。(s,l)表示第s层和第l层之间卷积层的权值的归一化的L1范数大小,表示Xs和Xl之间的关系大小。从图中可以看到,大部分层之间关系都不是很大。所以DenseNet这种连接大部分都是冗余的,是不是可以去掉部分连接呢,去掉之后精度会不会有影响?
VoVNet
VoVNet是在上述DenseNet基础上提出的模型,其中提出OSA(One-Shot Aggregation)模块。
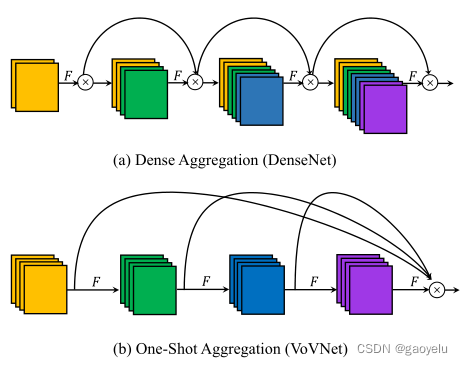
可以看到,与DenseNet不同的是,在一个OSA模块里,各层只是在最后一层进行聚合,去掉了中间层聚合的部分。
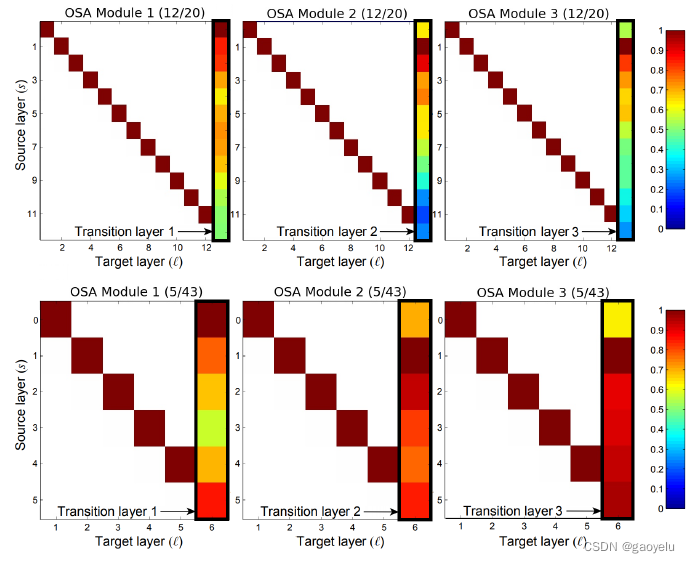
可以看到,去掉之后图中蓝色部分(各层联系不紧密的部分)明显少了很多,说明OSA模块的每个连接都是相对有用的。
模型具体计算结构:
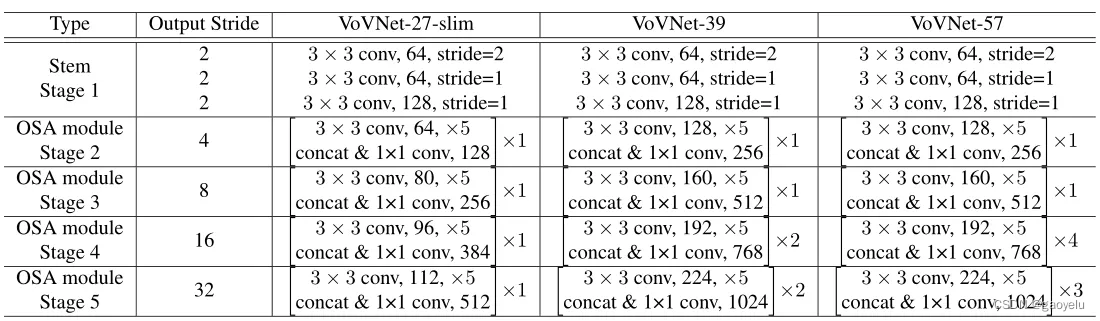 在每个stage结束都会有一个3x3,stride=2的max-pooling层来减少特征维度。
在每个stage结束都会有一个3x3,stride=2的max-pooling层来减少特征维度。
具体VoVNet作为backbone在各个检测模型上的结果和其他backbone的比较,见论文。
参考
- https://zhuanlan.zhihu.com/p/393740052
- https://arxiv.org/pdf/1904.09730v1.pdf
- https://zhuanlan.zhihu.com/p/141178215