ExSwin-Unet

数据集来源: https://feta.grand-challenge.org/
摘要
准确的胎儿大脑MRI图像分割对于胎儿疾病的诊断和治疗至关重要。然而手动分割费力、耗时且容易出错,但自动分割是一项具有挑战性的任务,因为:
- 患者大脑结构的形状和大小存在差异,
- 先天性疾病引起的细微变化,
- 脑的复杂解剖结构。
我们提出了一种配备了新的 ExSwin 转换器块的新型不平衡加权 Unet,通过有效地捕获不同样本之间的远程依赖性和相关性来全面解决上述问题。我们设计了一个更深层次的编码器来促进特征提取和保留更多语义细节。此外,采用自适应权重调整方法动态调整不同类的损失权重,以优化学习方向并从欠学习类中提取更多特征。在 FeTA 数据集上进行的大量实验证明了我们模型的有效性,取得了比最先进方法更好的结果。
目的:医学图象实例分割
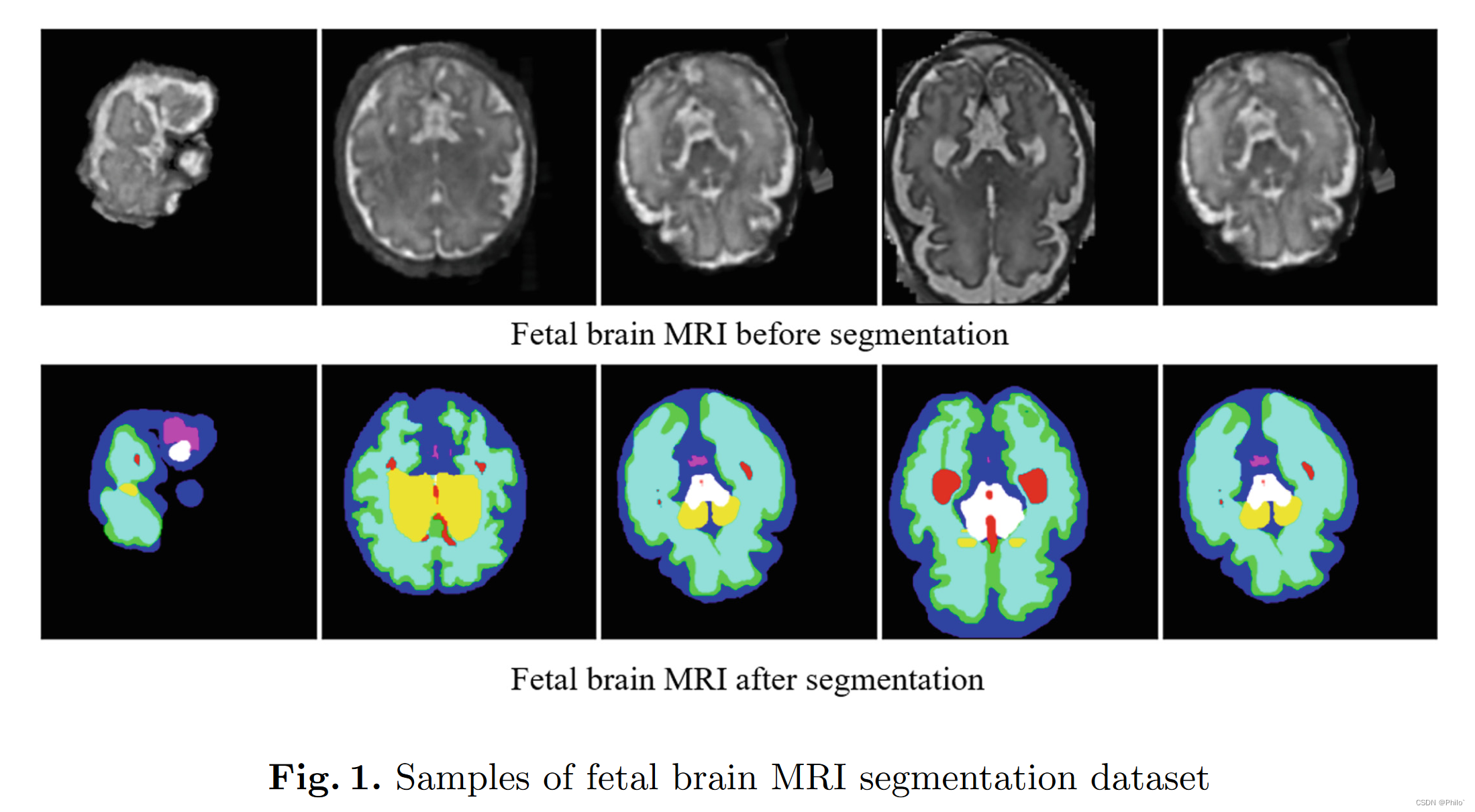
1 引言
我们提出了一种新型的不平衡加权 Unet,配备了用于胎儿大脑 MRI 图像分割的新 ExSwin 变换器块,以有效捕获不同样本之间的远程依赖性和相关性,从而提高分割性能。 ExSwin 转换器块由窗口注意块和基于外部注意方案的外部存储器块组成。 window attention block负责局部和全局特征表示学习,而external memory block将不同的样本内特征与其两个外部记忆单元相结合,以减少由于降维而导致的信息损失,并获得数据集的归纳偏置信息。此外,我们设计了一种特殊的不平衡 Unet 结构,我们采用更大的编码器尺寸来促进特征提取和保留更深层次的语义信息。此外,实现了一种自适应权重调整方法来动态调整不同类的损失权重,这有助于优化模型学习方向并从正在学习的类中提取更多特征。由于我们的数据集来自 FeTA 2021 挑战赛,因此我们与几个参与者的网络(例如 Unet、Res-Unet 和 Trans-Unet)进行了比较,我们的模型在这些网络中具有更好的性能。对数据集的定量实验和消融研究证明了所提出模型的有效性,取得了比最先进的方法更好的结果。
2 方法
我们的非平衡 ExSwin-Unet 框架如图 2 所示。我们的 ExSwin Unet 主要由编码器、瓶颈、解码器以及编码器和解码器块之间的跳过连接组成。在我们的编码器模块中,输入图像被分成不重叠的块,块大小为 4×4,每个块的特征维度变为 16 倍。此外,特征维度通过线性嵌入层投影到选定的维度 C。之后,我们不断交替应用 ExSwin 块和补丁合并层,其中 ExSwin 块掌握特征表示,补丁合并层增加下采样的特征维度。具体来说,ExSwin 块大小是均匀的,因为它需要交替执行 window 和 shift window attention 来捕获图像的局部和全局特征。我们的 ExSwin 模块能够从输入图像中提取高级特征。然后我们应用两个 ExSwin 块作为瓶颈块,以增强输入特征维度和输出特征维度相同的模型收敛能力。
另一方面,在解码器模块中,我们应用具有多个 ExSwin 块的补丁扩展层来分层执行特征上采样。 应用同级 ExSwin 块之间的跳过连接来补充下采样过程中丢失的详细信息,并保留高级特征图中包含的更多高分辨率细节。在解码器的末端,添加了一个特定的补丁扩展层以进行 4× 上采样,其中特征分辨率映射到输入分辨率。最后,上采样的特征将通过线性投影层映射到分割预测。
网络总体结构图:
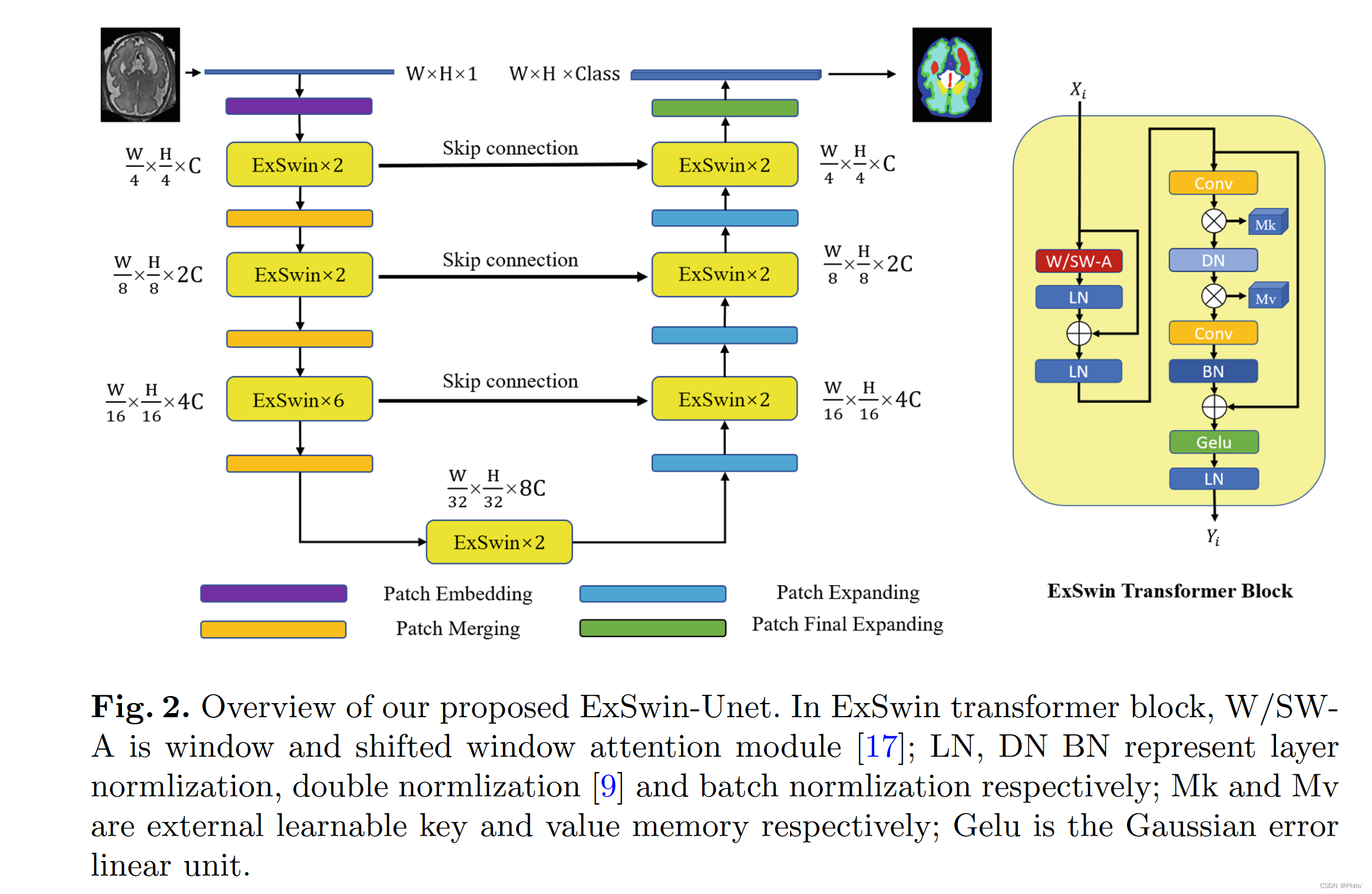
在ExSwin Transformer Block中,W/SWA是window and shifted window attention module(Swin Transformer中的模块);LN、DNBN分别代表layer normlization、double normalization和batch normlization; Mk和Mv分别是外部可学习的key和value memory; Gelu 是高斯误差线性单位。
2.1 基于窗口的注意力块
基于移位窗口机制和层次结构,Swin transformer 能够提取输入图像的局部和全局特征。由于我们的 Feta 数据集样本是从 3D 图像生成的 2D 图像,空间信息很容易丢失。为了弥补空间信息的损失并提高不同样本之间的特征融合,我们提出了一个名为 ExSwin transformer block 的新 transformer block。 ExSwin 块由基于窗口的注意力块和外部注意力块构成。我们的 ExSwin 块的结构如图 2 所示。ExSwin 块的操作可以表述如下:

调整窗口注意块
在窗口注意块中,我们应用了基于窗口的多头自注意(W-A)模块和基于移位窗口的多头自注意(SW-A)[17]。基于窗口和基于移位窗口的多头自注意力模块应用于两个连续的变压器块。基于窗口的多头自注意力计算每个窗口中的注意力以捕获局部窗口特征。另一方面,shifted window-based multi-head self-attention,凭借其shifting机制,计算注意力以混合跨窗口特征并捕获全局特征。局部自注意力可以表示为:
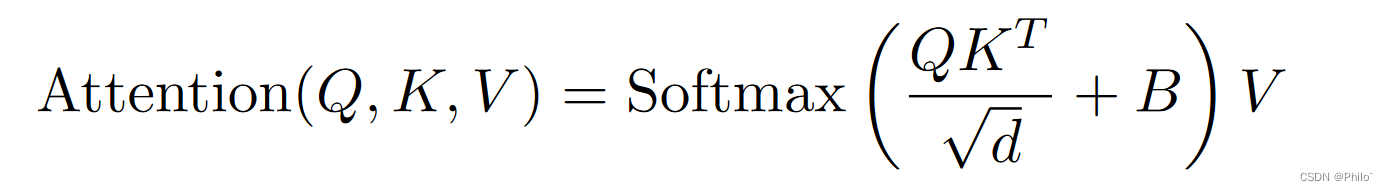
其中 Q, K, V ∈ RM2×d 表示查询、键和值矩阵; M 2 表示窗口中的补丁数,d表示查询或键的维度; B 是相对位置偏差,其值取自偏差矩阵 ^ B ∈ R(2M−1)×(2M+1),因为沿每个轴的相对位置位于 [−M +1,M − 1].
后标准化
在训练基于窗口注意力的模型时,我们可能会遇到训练不稳定的情况,因为网络深层的激活值非常低 [16]。为了缓解不稳定的情况,图 3 所示的后归一化应用于注意块,并在外部注意块之前添加了一个额外的层归一化单元。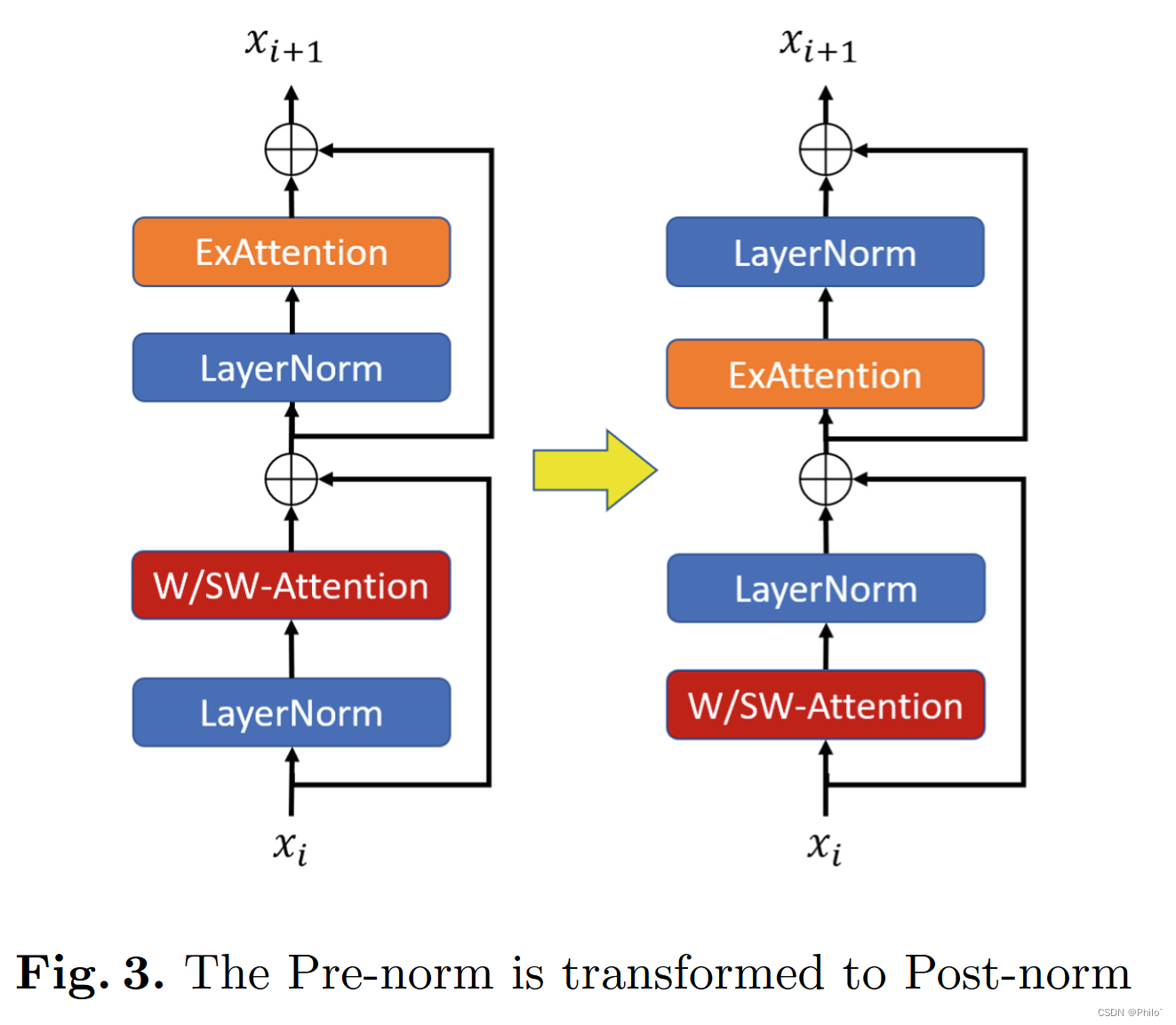
比例余弦注意力
window attention和shifted window attention模块在计算自注意力时,某些block或heads中的attention map支配了其他特征,导致特征提取有偏差。我们可以用余弦相似度代替内积相似度来改善问题:
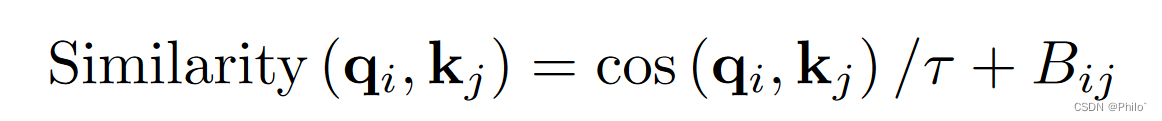
其中 Bij 是像素 i 和 j 之间的相对位置偏差; τ 是一个可学习的标量,不跨头和层共享。由于余弦函数是等价归一化的,代入可以缓解一些内积支配的情况。
2.2 外部注意力块
在外部注意块中,我们设计了一个多头外部注意模块,它应用两个卷积层来掌握特征表示和两个外部可学习记忆单元来捕获不同样本之间的空间信息和样本亲和力。外部注意块采用外部注意机制,采用两个外部存储单元Mk和Mv来恢复相邻切片之间的空间信息并存储当前全局信息。外部注意力模块是为捕获样本内特征而设计的,它能够从输入样本中学习到更具代表性的特征。外部注意块结构如图 4 所示,我们的多头外部注意模块的伪代码如算法 1 所示。
由于多头注意力和卷积机制是互补的,我们在外部注意力块中应用了两个卷积层。为了聚合跨通道特征,第一个卷积层内核大小为 1 × 1。为了获得对注意机制的有用补充,第二个卷积层内核大小为 3×3,填充大小为 1。3×3 卷积层以更大的感受野捕获局部信息并增强对特征表示的掌握。
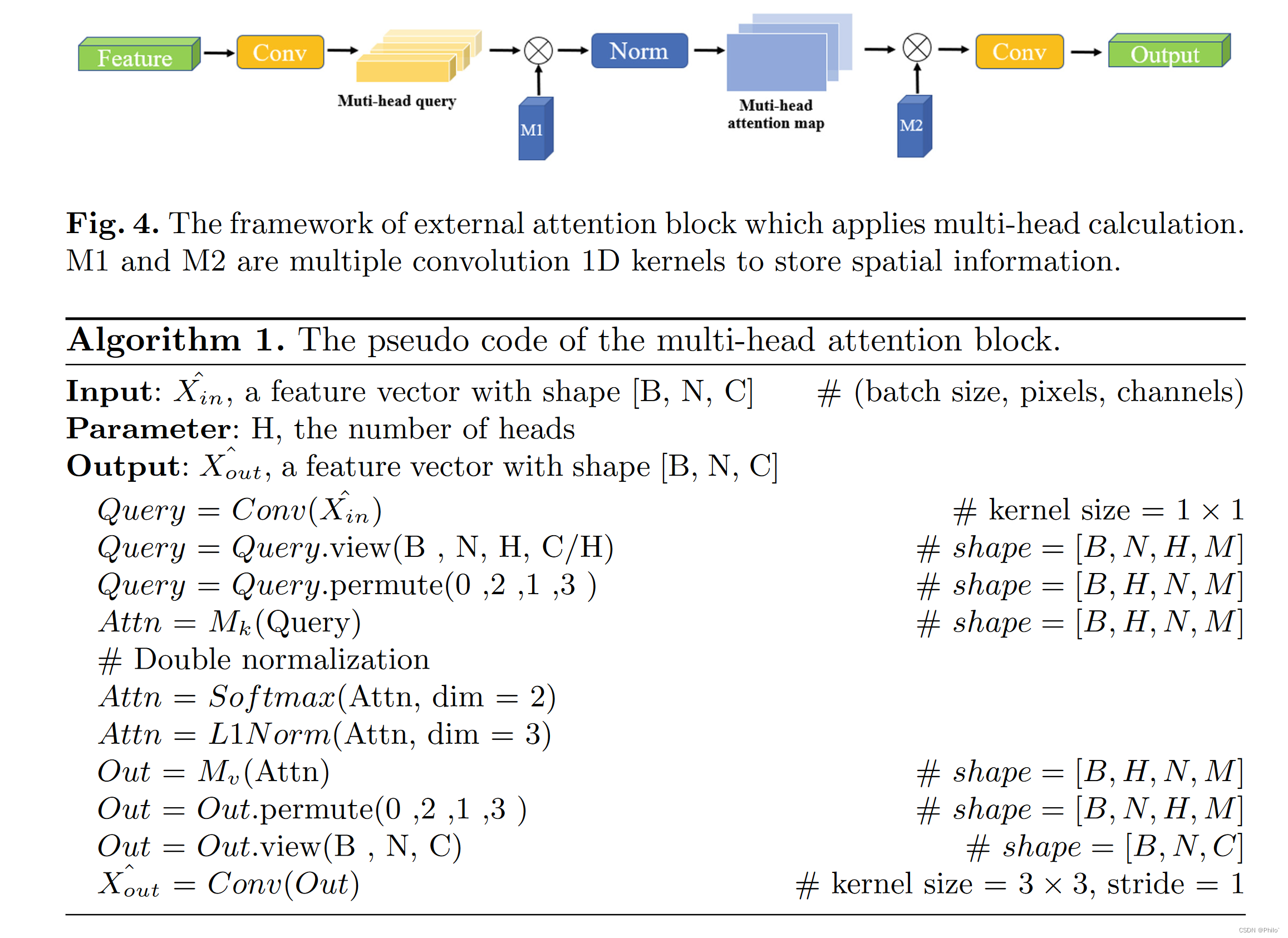
应用多头计算的外部注意块框架。 M1和M2是多个卷积一维核,用于存储空间信息。
2.3 不平衡的 Unet 架构
在编码器-解码器unet结构中,编码器和解码器中Ex-Swin块的大小不同。编码器和解码器模块的 Ex-Swin 块大小分别为 [2, 2, 6] 和 [2, 2, 2]。超参数设置的想法受到 Swin-T 模型的启发,我们的实验结果也证明了它对平衡 Unet 结构的有效性。具有更深尺寸 Ex-Swin 块的编码器块能够获得更好的特征提取并增强保留广泛上下文信息的模型能力。尺寸更小的解码器块节省了计算资源,也有利于模型收敛。
它说的不平衡UNet竟然指的是编解码中使用的Block数量不同
2.4 自适应加权调整
在医学分割任务中,由于标记数据的情况有限且不平衡,我们可能会遇到有偏差的数据分割训练结果。为了减轻偏差并提高模型性能,我们提出了一种损失函数的自适应权重调整策略,该策略对学习不足的样本进行模型学习,并防止模型在模型训练过程中压倒表现良好的样本。在我们的自适应权重调整机制中,类 c 的权重值 vc 计算如下:
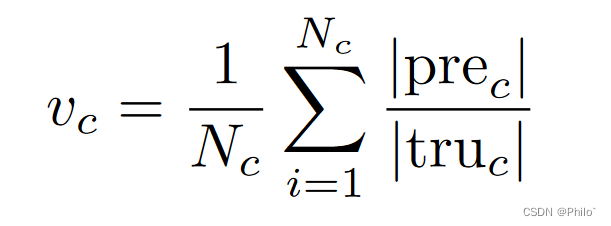
其中 |prec|是与类 c 和 |truc| 的地面实况像素相匹配的预测像素是相应ground truth中c类的总数。并且自适应权重wc可以通过权重值来计算:
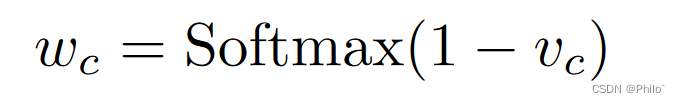
其中类别权重将针对每个时期的训练过程进行更新。在这种情况下,生成合适的权重以使模型能够调整其学习方向并减轻有偏差的分割结果。
2.5 双重损失函数
为了提高分割精度和学习速度,我们定义了一个对偶损失函数。由于我们采用了自适应权重调整方法,损失是通过取平均值计算每个类的加权损失来获得的。假设 wc 是每个类的权重,C 是类的总数。
多类交叉熵损失:
交叉熵损失衡量两个概率分布之间的差异。它加快了模型收敛并减少了模型训练资源消耗。
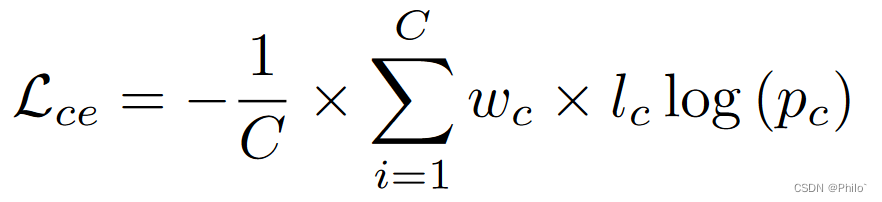
其中 pc 是输出中 c 类的分割概率,lc 是 c 类的标识,范围为 0 或 1,wc 是 c 类的自适应权重。
方形骰子损失:
Dice loss 衡量两个分布的相似性,我们将其应用于计算输出预测和基本事实之间的相似性。它有助于提高模型性能并提高准确性。
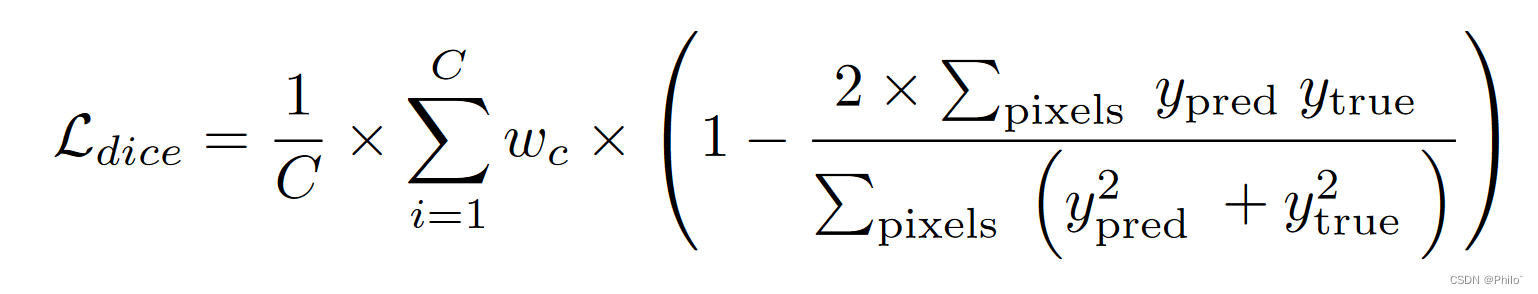
其中 ∑ pixels 表示像素值之和,ypixels 和 ytrue 分别是分割预测和分割真值,wc 是 c 类的自适应权重。
总体损失函数:
总损失是平均加权 CE 损失和平均加权 DICE 损失与系数 α 的线性组合。
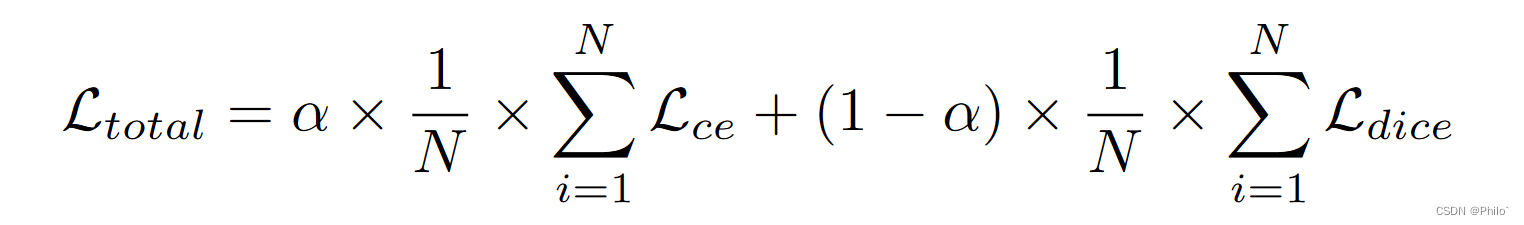
3 实验结果
3.1 数据集
该数据集是 2021 年发布的 Fetal Brain Tissue Annotation and Segmentation Challenge [20]。胎儿大脑 MRI 被手动分为 8 个不同的类别,平面内分辨率为 0.5mm×0.5mm。数据集包括 80 个 3D T2 加权胎儿大脑和重建方法,用于创建胎儿大脑的超分辨率重建。我们将数据集分为 60 个训练集和 20 个测试集。为了节省时间和能源消耗,我们将数据集转换为大小为 256×256 的二维图像。
3.2 实现细节
我们在单个 NVIDIA RTX 2080Ti(11 GB RAM)上训练和测试我们的模型。 ExSwin-Unet 模型是在 Python 3.7 和 Pytorch 1.7.0 上训练的。为了增加数据多样性并避免数据过度拟合,我们对数据集应用了简单的数据增强翻转和旋转。我们采用加权双重损失函数,并使用前瞻优化器 [26] 和 Adam 优化器 [12] 作为内部优化器。此外,我们通过实验设置总损失系数α=0.4以获得相对更好的性能。在模型训练期间,初始学习率为 1e-4,每个 epoch 都有损失衰减。我们训练了 200 个 epochs 的模型,批量大小为 16。
3.3 与 SOTA 方法的比较
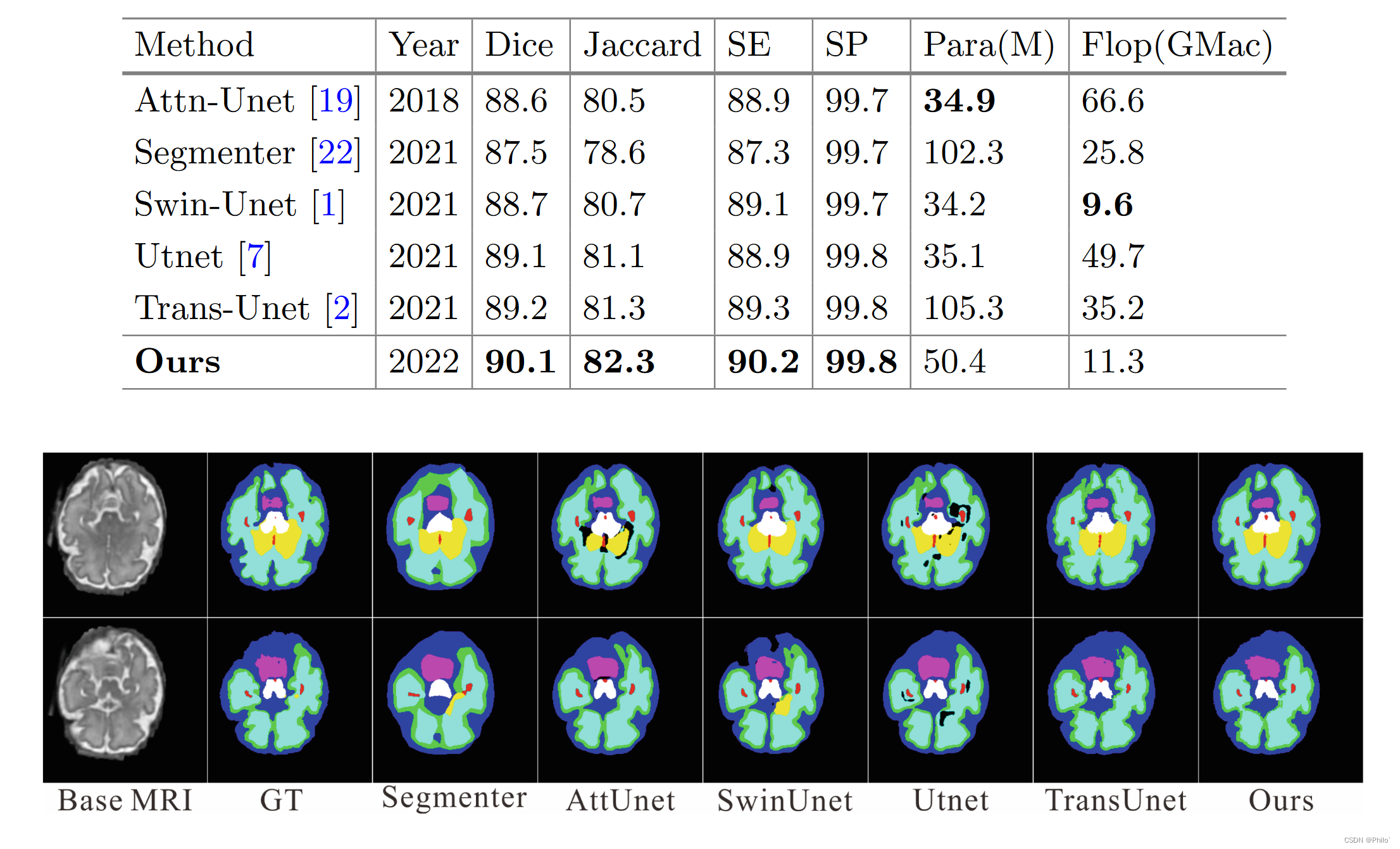
为了评估我们方法的性能,我们将我们的网络与五种最先进的方法进行了比较,包括 Segmenter [22]、Attn-Unet [19]、Utnet [7]、Swin-Unet [1] 和 Trans-Unet [2].比较的模型包括四个基于 transformer 的模型结构和一个基于 CNN 的模型,即 Attention Unet。我们在相同的计算环境下进行了比较,没有使用任何预训练模型。视觉和统计比较都是使用相同的数据集和相同的数据处理方法进行的。统计对比结果如表1所示,可视化结果如图5所示。
我们的模型具有其独特的功能,通常在 dice 和 jaccard 分数上优于其他 SOTA 方法,并且计算消耗更少。我们比 Trans-Unet 节省了 50% 的参数,并获得了更好的分割性能。在视觉上与图 5 中的其他分割方法相比,我们的模型在分割具有不同尺度和不规则形状的胎儿组织方面也表现出色。证明所提出的 ExSwin-Unet 能够提高分割性能。
3.4 消融研究
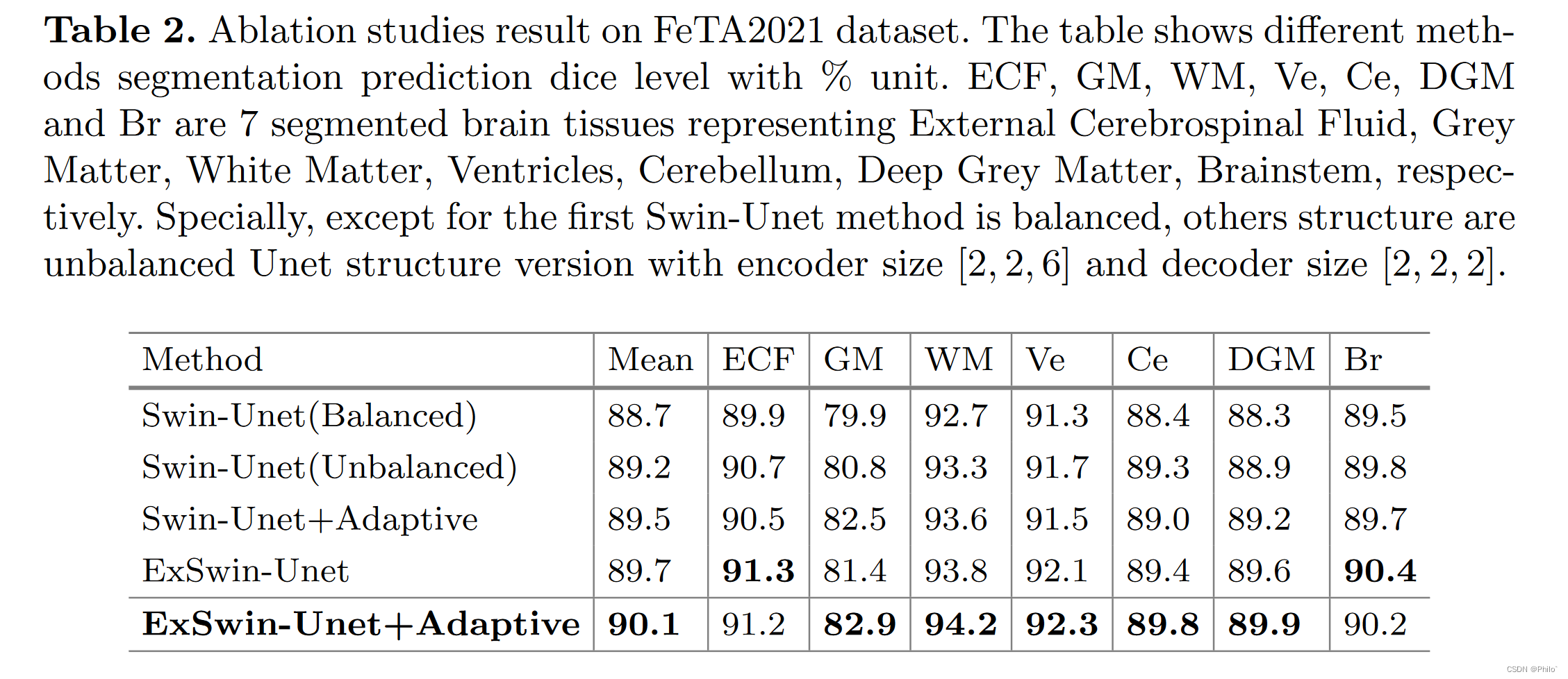
为了证明所提出组件的有效性,我们对不同组件和不平衡结构进行了消融研究。组件消融实验结果如表2所示,不同方法的关注热点如图6所示。为了说明我们的不平衡结构的有效性,我们对不平衡结构进行了消融研究,如表4所示。
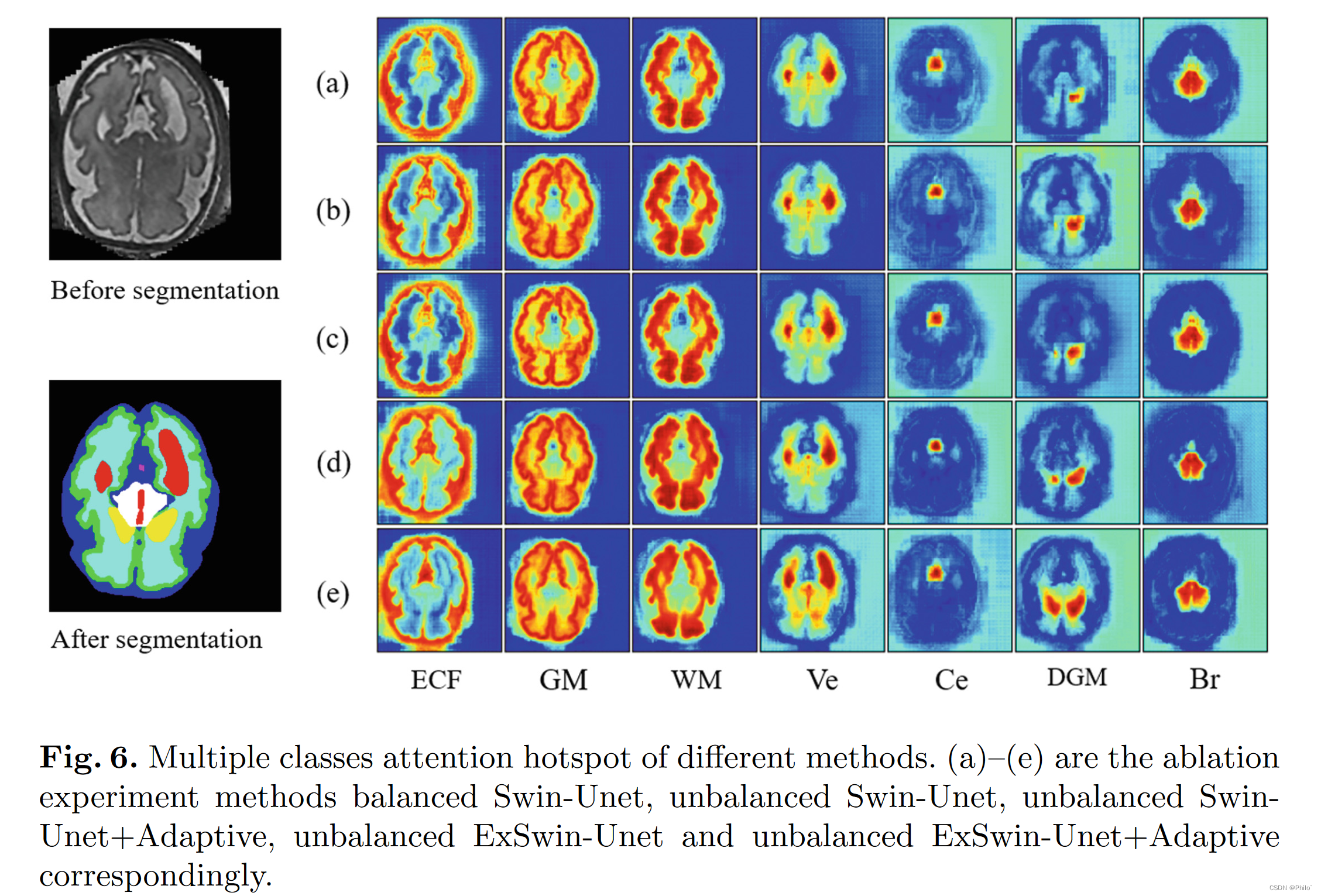
如表 2 所示,不平衡的 Unet 结构以其较大的编码器尺寸有利于特征学习过程。具有外部注意单元的模型能够结合不同的样本内特征并减轻空间信息损失。自适应损失减轻了模型不平衡类欠学习问题。
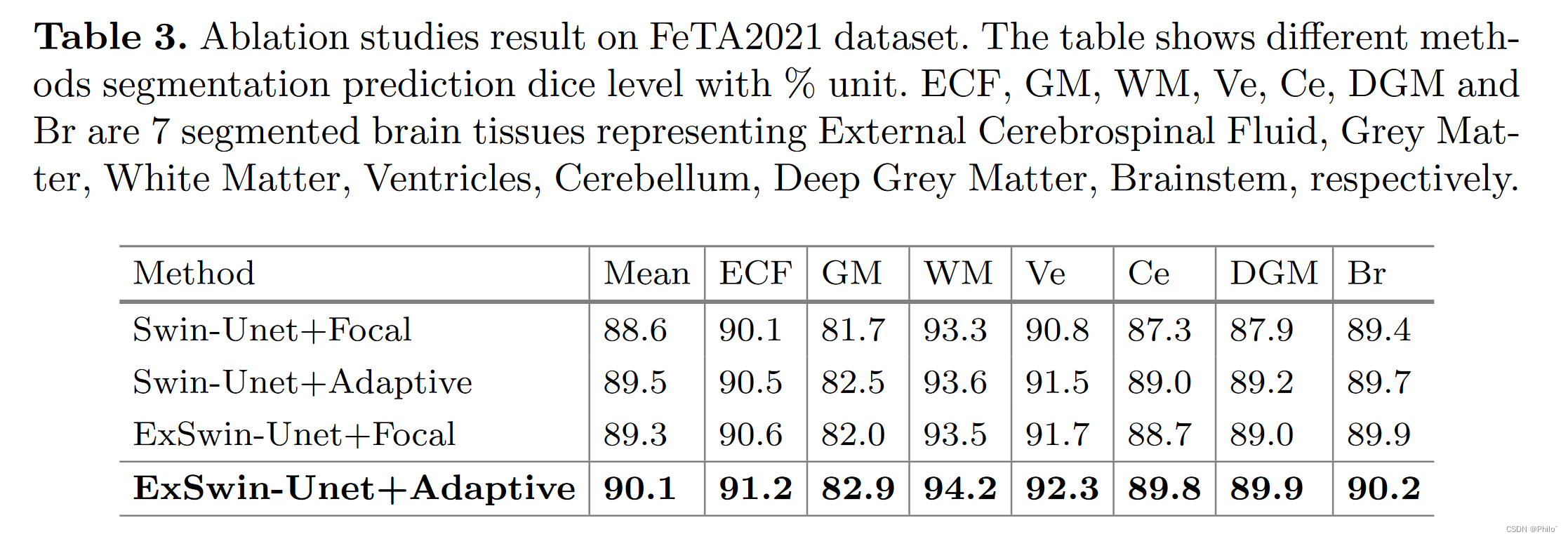
如表 3 所示,我们进一步与典型的类不平衡损失 focal loss [14] 进行比较,以验证我们的自适应损失方法的有效性。结果证明了我们的方法的有效性,其中我们的自适应加权损失函数通过掌握学习不足类的信息和提高整体性能来提高模型学习能力。
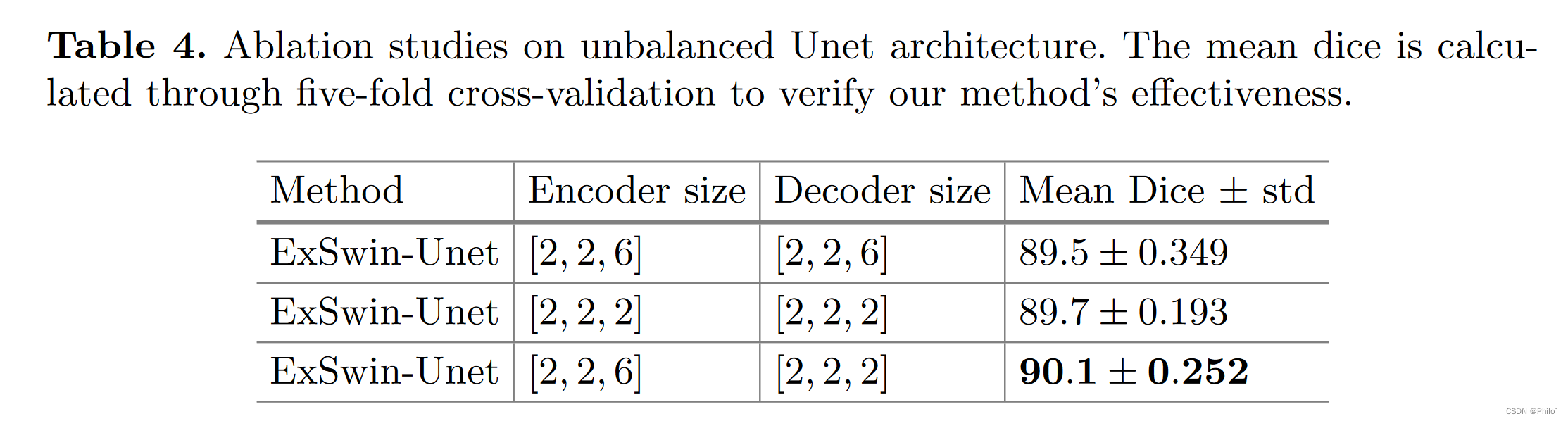
非平衡 Unet 结构的消融研究如表 4 所示,证明了非平衡 Unet 结构的有效性。使用更大的编码器尺寸,我们的模型可以获得比其他两个平衡模型更好的性能。实验表明,不平衡结构有利于模型特征提取过程并改善分割结果。
4 讨论和限制
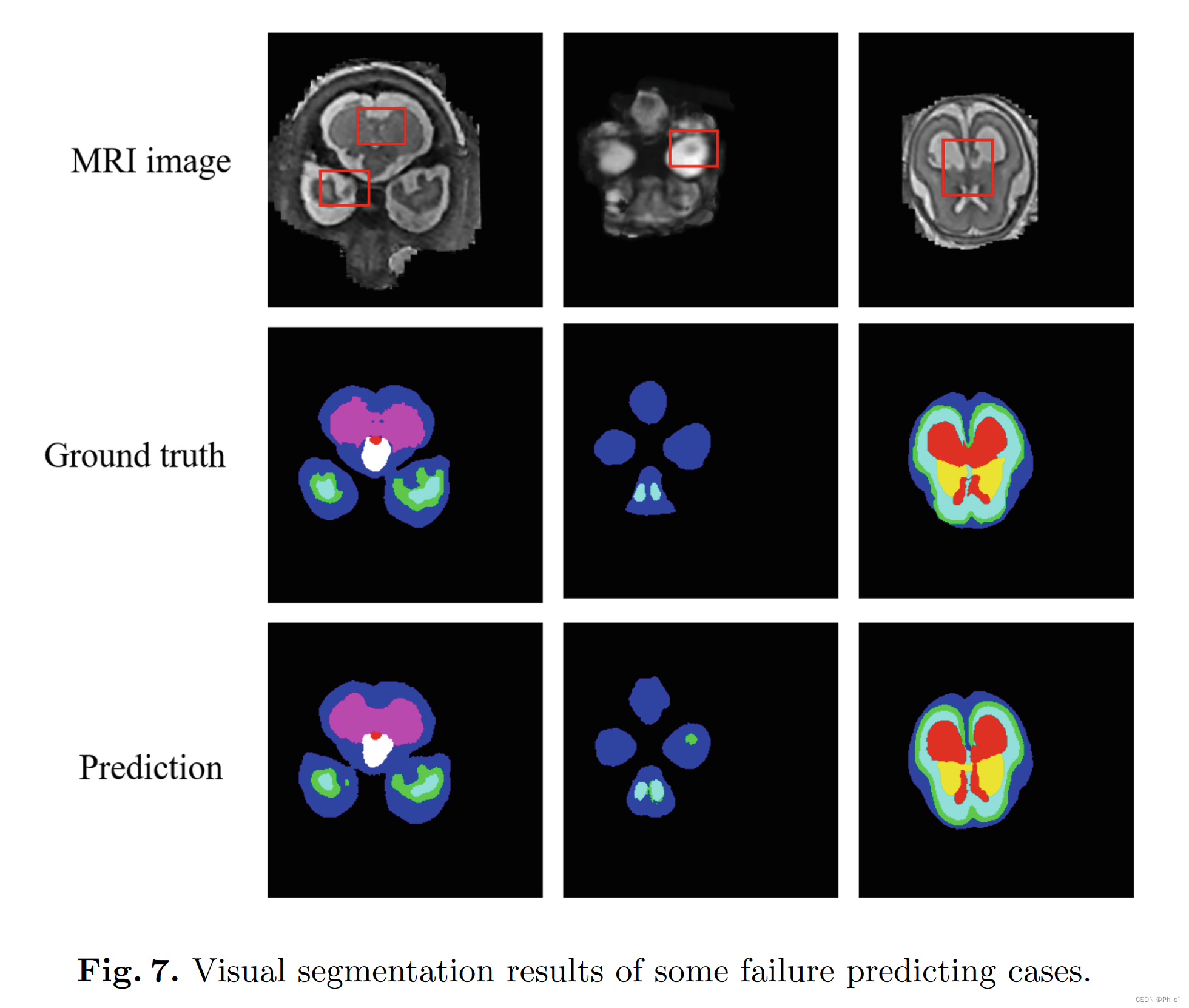
通过上述消融研究和对比实验,我们设计了一个有效的基于 2D 的分割网络,具有外部注意力,以在 3D 图像切片上实现分割任务。我们的目的是发现样本内关系以减轻空间信息损失并有利于特征学习过程。外部注意力模块实现了这个目标,实验证明了它的有效性。此外,我们发现平衡的 Unet 结构对于 Unet 框架来说可能不是必需的,因为不平衡的 Unet 可以获得比平衡的 Unet 更好的性能。另一方面,我们的方法仍然有一些局限性。如图 7 所示,我们的模型未能在一些小尺度上实现正确的预测。
5 结论
在本文中,我们提出了一种新型的不平衡加权 Unet,配备了新的 ExSwin 变压器块,以改善胎儿大脑 MRI 分割结果。 ExSwin transformer 由 shift-window attention 和 external attention 模块组成。 ExSwin transformer block 不仅可以掌握基本的样本特征表示,还可以捕获不同 3D 切片之间的样本内相关性和空间信息。并且 Unet 是不平衡的,其中编码器具有较大的尺寸以促进特征提取过程。此外,我们引入了一种自适应权重调整策略来改善有偏见的数据分割情况。定量比较实验和消融研究证明了我们提出的模型的良好性能。