只讲深度学习用到的显卡驱动。
以NVIDIA-driver-515.105及cuda-11.7为例
一、显卡驱动的卸载
CentOS / RHEL
方法一:找到旧版本显卡驱动.run文件:
sh NVIDIA-Linux-x86_64-418.126.02.run --uninstall
方法二:清除所有nvidia相关文件和依赖
yum remove nvidia-*
进一步清除(把nvidia-driver的相关组件都清理掉):
rpm -qa|grep -i nvid|sort
yum remove kmod-nvidia-*
清除cuda
yum remove "*nvidia*"
yum remove "*cublas*" "cuda*"
卸除驱动重启
sudo reboot
Ubuntu LTS
值得注意的是,由于内核系统的不同,所采取的命令方法不同
apt-get属于ubuntu、Debian的包管理工具
yum则属于Redhat、Centos包管理工具
在选择利用什么命令删除时,应先确定自己的系统是什么。
如sudo apt-get purge nvidia-*代替yum remove nvidia-*
sudo apt-get purge nvidia-*
sudo apt-get --purge remove cuda
二、显卡驱动的安装
基本知识
显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么? - 知乎
大概补充下知识。
CUDA驱动程序:CUDA驱动程序是一个用于与GPU通信的软件组件它负责管理GPU的硬件资源和执行CUDA应用程序。
CUDA Toolkit:CUDA Toolkit是一个用于开发和优化CUDA应用程序的软件包,其中包括CUDA驱动程序和CUDA运行时库。
CUDA运行时库:CUDA运行时库是一个用于在GPU上执行CUDA应用程序的软件组件,它提供了一组CUDA API函数,于管理GPU内存和执行CUDA内核。
前置条件
验证系统是否安装gcc,g++,tar,make,如果没有安装,就手动配置yum源进行安装。
查看显卡版本命令:
# 查看自己的显卡信息
lspci | grep -i nvidia
# GPU驱动版本,driverAPI(支持的最高cuda版本)
nvidia-smi
# 动态监控显卡状态
watch -t -n 1 nvidia-smi
# cuda版本,timeAPI(运行时API)
nvcc -V
查询选取对应版本显卡驱动、CudaToolkit和cudnn:
查询NVIDIA显卡和cuda对应版本关系。NVIDIA CUDA Toolkit Release Notes
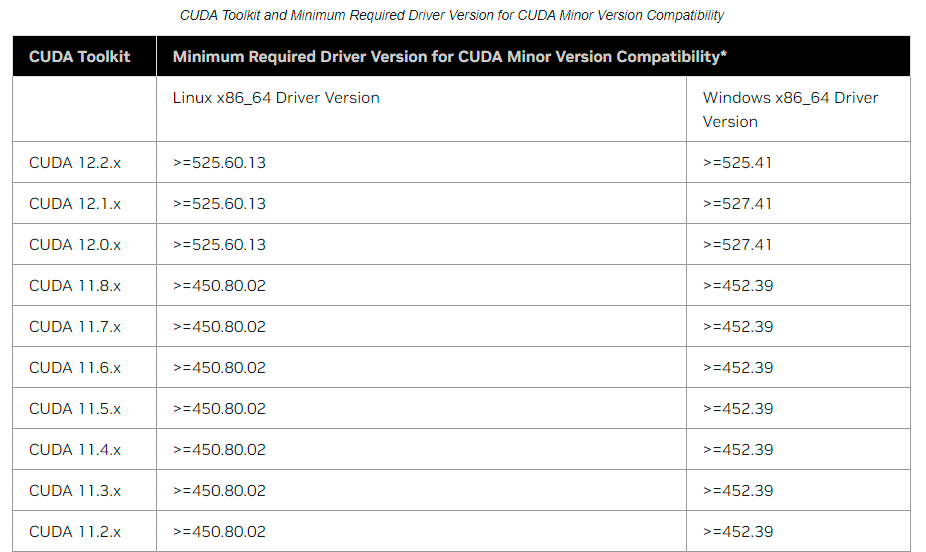
查询PyTorch与cuda对应版本关系Previous PyTorch Versions
本文选取的是NVIDIA-driver-515.105加cuda-11.7。
安装NVIDIA显卡驱动(NVIDIA Driver)
下载NVIDIA 驱动程序,在线的可以用wget下载,或者用复制地址下载拷贝到服务器。
赋予权限,并安装。
chmod +x NVIDIA-Linux-x86_64-515.105.01.run
./NVIDIA-Linux-x86_64-515.105.01.run -no-x-check
在安装过程中可能会显示问题,选择No继续。
如果出现警告可以不用理会,直接接续,直到安装完成。
> Install NVIDIA's 32-bit compatibillity libraries?
> Yes [No]

如有问题检查是否卸载驱动或看问题1:./NVIDIA-Linux-x86_64-515.105.01.run -no-x-check
测试显卡驱动是否安装成功
nvidia-smi
安装CUDA
下载CUDA Toolkit 下载地址,或者搜旧版本下载CUDA Toolkit 旧版本下载地址。
赋予权限,并安装。
chmod +x cuda_11.7.1_515.65.01_linux.run
./cuda_11.7.1_515.65.01_linux.run
安装过程中,会问你是否需要下载驱动(Drive),正常情况下请不要下载,即选择否。
取消第一个Driver选项里的X,[X]改为[ ],不下载驱动Driver(ctrl+c快速跳过),因为已安装(这里需要强调一下)。
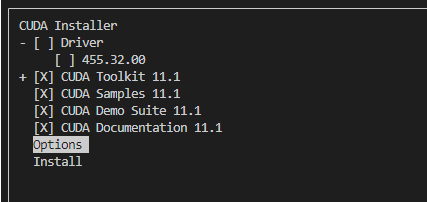
安装完会出现:
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-11.7/
Please make sure that
- PATH includes /usr/local/cuda-11.7/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-11.7/lib64, or, add /usr/local/cuda-11.7/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-11.7/bin
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-11.7/doc/pdf for detailed information on setting up CUDA.
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 515.105 is required for CUDA 11.7 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run -silent -driver
配置环境变量,将以下内容添加到~/.bashrc文件中。
打开文件
vim ~/.bashrc
在文件末尾添加如下两行,可以将cuda版本11.7替换成安装的版本,如cuda-12.2。
export PATH=/usr/local/cuda-11.7/bin${
PATH:+:${
PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.7/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
使用以下命令刷新~/.bashrc配置文件,使得配置生效。
source ~/.bashrc
测试、查询nvcc版本检查是否安装成功
nvcc -V
安装cudnn
下载cuDNN 下载地址。
rpm -i cudnn-local-repo-rhel7-8.9.2.26-1.0-1.x86_64.rpm
三、Docker显卡适配
软件版本:
Docker:Docker version 20.10.9, build c2ea9bc
CUDA:NVIDIA-SMI 515.105.01 Driver Version: 515.105.01 CUDA Version: 11.7
系统:CentOS-7
docker在19.03版本以后已经不需要再独立安装nvidia-docker就可以支持显卡了,只需要配置好docker和CUDA环境即可,现在用新方式装NVIDIA Container来支持docker调用显卡。
Nvidia-Docker安装需要安装两个部分,Docker-CE和NVIDIA Container Toolkit,也就是不再需要Docker-CE。
NVIDIA-Container-Toolkit架构
NVIDIA官网架构概述,可以用Chrome自带网页翻译仔细阅读,本文仅简单介绍。
NVIDIA Container主要组件包括nvidia-container-runtime, nvidia-container-toolkit, libnvidia-container,安装时需要提前装好CUDA驱动;
在3.6.0版本后,runtime包成为一个只依赖于toolkit包(指container-toolkit而不是nvidia CUDA toolkit)的包,在官网中也指出,对于一般的应用而言,nvidia-container-toolkit能够满足绝大多数需求。
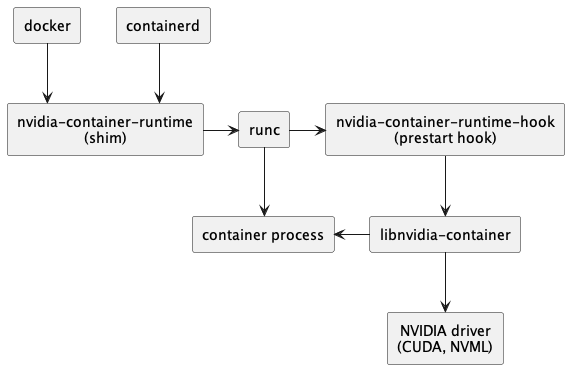
安装包依赖关系
官网文档依赖图如下。
├─ nvidia-container-toolkit (version)
│ ├─ libnvidia-container-tools (>= version)
│ └─ nvidia-container-toolkit-base (version)
│
├─ libnvidia-container-tools (version)
│ └─ libnvidia-container1 (>= version)
└─ libnvidia-container1 (version)
nvidia-container-toolkit-base现包含在nvidia-container-toolkit内部里,并且不再需要安装nvidia-container-runtime。(之前的nvidia-docker需要多安装两个包nvidia-container-runtime和nvidia-docker2。)
按照上文依赖关系,安装三个软件包,顺序为
libnvidia-container1 -> libnvidia-container-tools -> nvidia-container-toolkit
离线下载安装
这里下载安装包离线安装。
官网提供GitHub链接:
1.nvidia-container-toolkit安装包下载地址
找到对应系统版本的安装包下载。
例如我使用的CentOS7系统,就可以下载nvidia-container-runtime/stable/centos7/x86_64/目录下面的nvidia-container-toolkit-1.5.1-2.x86_64.rpm安装包
2.libnvidia-container1和libnvidia-container-tools安装包下载地址
找到对应系统版本的安装包下载。
同样我使用的CentOS7系统,就可以下载nvidia-container-runtime/stable/centos7/x86_64/目录下面nvidia-container-toolkit-1.5.1-2.x86_64.rpm安装包
(点到文件里右上角有个 ↓ Download raw file按钮,没反应的话怀疑一下网络是否科学联通)
三个包都下载好后导入系统,选择到对应文件夹下安装。
rpm包安装方式,安装文件夹下所有rpm安装包
rpm -ivh *.rpm
deb包安装方式
dpkg -i *.deb
装完重启docker服务。
systemctl restart docker
systemctl status docker
成功!可以--gpus all启动一个容器测试下是否容器使用GPU是否正常。
四、测试
使用docker run --gpus all启动一个容器,进入容器内部测试下使用GPU是否正常。
在python里检查,也是大家用的最多的方式,检查GPU是否可用(但实际并不一定真的在用)
import torch
torch.cuda.is_available()
# setting device on GPU if available, else CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
print()
#Additional Info when using cuda
if device.type == 'cuda':
print(torch.cuda.get_device_name(0))
print('Memory Usage:')
print('Allocated:', round(torch.cuda.memory_allocated(0)/1024**3,1), 'GB')
print('Cached: ', round(torch.cuda.memory_reserved(0)/1024**3,1), 'GB')
五、错误汇总
1.ERROR: You appear to be running an X server; please exit X before installing. For further details, …
安装NVIDA驱动时,出现这个错误。主要是由于安装远程控制lightgm 导致X-server启动。
解决办法:
sudo chmod +x NVIDIA-Linux-X86_64-515.105.run
sudo ./NVIDIA-Linux-X86_64-515.105.run -no-x-check
在后面加上-no-x-check,不对Xserver进行检查的命令,就可以安装成功!
其余参数:
--no-opengl-files:表示只安装驱动文件,不安装OpenGL文件。这个参数不可省略,否则会导致登陆界面死循环,英语一般称为”login loop”或者”stuck in login”。
--no-x-check:表示安装驱动时不检查X服务,非必需。
--no-nouveau-check:表示安装驱动时不检查nouveau,非必需。
-Z, --disable-nouveau:禁用nouveau。此参数非必需,因为之前已经手动禁用了nouveau。
-A:查看更多高级选项。
方法2:修改运行级别为文本模式:升级nvidia驱动程序 - EchoZQN - 博客园
2.Error response from daemon: could not select device driver “” with capabilities: [[gpu]]
Nvidia Docker安装后,使用镜像创建容器时出错,错误提示:
Error response from daemon: could not select device driver "" with capabilities: [[gpu]]
需要安装:NVIDIA Container Toolkit
服务器nvidia驱动已安装,GPU使用没问题,但是docker无法使用GPU,这时就需要检查一下NVIDIA Container Toolkit是否已安装。NVIDIA Container Toolkit允许用户构建和运行GPU加速Docker容器(docker 版本 19之后,18之前使用nvidia-docker命令),所以只有安装了这个之后,才可以在docker内使用GPU。
根据你的系统,在官网上查找对应的安装命令。
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
官网写的非常详细,一步步走下来就可以。
章节三中写的十分详细
3.file /usr/lib64/libnvidia-container.so.1 from install of libnvidia-container1-1.13.5-1.x86_64 conflicts with file form package libnvidia-container1-1.0.0-0.1.beta.1.x86_64
这个错误意味着已经安装的软件包 “libnvidia-container1-1.0.0-0.1.beta.1.x86_64” 中的文件 “/usr/lib64/libnvidia-container.so.1” 与要安装的软件包 “libnvidia-container1-1.13.5-1.x86_64” 中的同名文件冲突。
这可能是由于包管理器尝试在系统中安装一个新版本的软件包,而该软件包的文件与现有软件包中的文件冲突造成的。解决该冲突的一种方法是卸载旧版本的软件包,或者通过更新或替换文件来更新冲突的文件。
使用以下命令尝试解决冲突:
sudo yum remove libnvidia-container1-1.0.0-0.1.beta.1.x86_64
4.ERROR: The Nouveau kernel driver is currently in use by your system. This driver is incompatible with the NVIDIA driver, and must be disabled before proceeding. Please consult the NVIDIA driver README and your Linux distribution’s docum…
这个问题是由于系统当前正在使用 Nouveau 显卡驱动导致的,而 NVIDIA 驱动与 Nouveau 驱动不兼容。为了解决这个问题,需要禁用 Nouveau 驱动。
方法一:通过 blacklisting 禁用 Nouveau 驱动
1)在/usr/lib/modprobe.d/dist-blacklist.conf中添加两行内容:
blacklist nouveau
options nouveau modeset=0
2)给当前镜像做备份
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
3)建立新的镜像
dracut /boot/initramfs-$(uname -r).img $(uname -r)
4)重新启动
sudo init 6
方法二:添加参数
添加参数--no-opengl-files
./NVIDIA-Linux-x86_64-515.105.01.run --no-opengl-files
5.docker: Error response from daemon: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Runing hook #0:: error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: initialization error: driver rpc error: timed out: unknown.
很奇怪的一个错误,启动容器的时候加载显卡--gpus all就会报错。这个链接给出了解答,原因是显卡资源没有打开Persistence Mode。
通过查阅大量资料,发现网上有位大神咨询过英伟达,英伟达给出的解释是:“显卡资源没有打开Persistence Mode”,输入下面的命令即可解决:
nvidia-smi -pm ENABLED
如果上面的命令回车后,出现提示,就按提示安装,安装完之后再次执行上面的命令,就可以了。
参考内容
NVIDIA 驱动程序下载地址.cn
NVIDIA 驱动程序下载地址.com
NVIDIA 驱动及 CUDA Toolkit 适配兼容版本及最低版本要求
CUDA Toolkit 下载地址
CUDA Toolkit 旧版本下载地址
CUDA Toolkit 11.7.1下载地址
cuDNN 下载地址
CentOS.7卸载与安装Nvidia Driver_centos 卸载nvidia驱动_Aaron_秦风的博客-CSDN博客
Linux Centos7安装更新GPU driver驱动和cuda:_linux升级cuda版本_大数据lsy的博客-CSDN博客
升级nvidia驱动程序 - EchoZQN - 博客园
如何降级cuda版本 - Python技术站
openpose环境搭建 ubuntu16.04+nvidia396.37+cuda9.2+cudnn7.1.4_tudou880306的博客-CSDN博客
linux如何查看版本信息-linux运维-PHP中文网
cuda、cudnn、cudatoolkit的所有版本下载网址_cudnn 下载_QT-Smile的博客-CSDN博客
python 查看显卡信息 python查看gpu
Docker离线安装Nvidia-container-toolkit实现容器内GPU调用_NekoTom的博客-CSDN博客
docker: Error response from daemon: could not select device driver ““ with capabilities: [[gpu]]报错_–gpus all 报错_每天都想躺平的大喵的博客-CSDN博客
Error : your appear to running an x server;please exit x before installing .for further details_error: you appear to be running an x server; pleas_EliteA1的博客-CSDN博客
玩NAS先学Linux(3):如何安装.run显卡驱动程序文件+解决NVIDIA Container Toolkit安装过程遇到的难题_软件应用_什么值得买