目录
1097. 游戏玩法分析 V
1098. 小众书籍
1107. 每日新用户统计
1112. 每位学生的最高成绩
1113. 报告的记录
1126. 查询活跃业务
1127. 用户购买平台
1132. 报告的记录 II
1142. 过去30天的用户活动 II
1149. 文章浏览 II
1159. 市场分析 II
1164. 指定日期的产品价格
1097. 游戏玩法分析 V **
注:2022年阿里春招实习大数据开发岗位笔试第一题就是留存率

- 源代码:
with install_dt as ( select player_id, min(event_date) dt from activity group by player_id ) select dt as install_dt, count(*) as installs, round(count(event_date) / count(*), 2) as day1_retention from install_dt left join activity on install_dt.player_id = activity.player_id and datediff(activity.event_date, install_dt.dt) = 1 group by dt; - 思路:这个题目和留存率的题目很像,但是这个题目是简化了的,就是只用求每个玩家第一天登录日期的次日留存;拿到这个题目,我首先就求出了每个玩家第一天登录日期是多少,然后再拿这张临时表去和源表进行join,注意这个join一定是left join,因为很有可能只是第一天登录了,后面就没有登录过了,限制条件除了id相同之外,就是限制 次日登录了,也就是两张表的日期间隔为1,当然我们也可以在join之后,去
select中去利用count(case when...)计算也是可以的。
1098. 小众书籍

- 源代码:
select t1.book_id, name from ( select book_id, name from books where available_from < '2019-05-23' ) t1 left join ( select order_id, book_id, quantity from orders where dispatch_date between '2018-06-23' and '2019-06-23' ) t2 on t1.book_id = t2.book_id group by t1.book_id having ifnull(sum(quantity), 0) < 10; - 思路:首先注意到有两个条件可以先过滤一下,一个是 上架时间不满一个月,第二个是 订单时间过去一年内**(做SQL就应该这样先把简单的写出来,然后再继续分析)**,那么就还剩下一个条件,订单总量小于10,这也很简单,但是我开始出错了,就是在进行过滤的时候,没有写
ifnull导致null没有被考虑,也就是如果上架的书一个订单都没有,我们sum之后是一个null值,而不是0,所以需要进行处理然后和10进行比较,否则就会出错
1107. 每日新用户统计
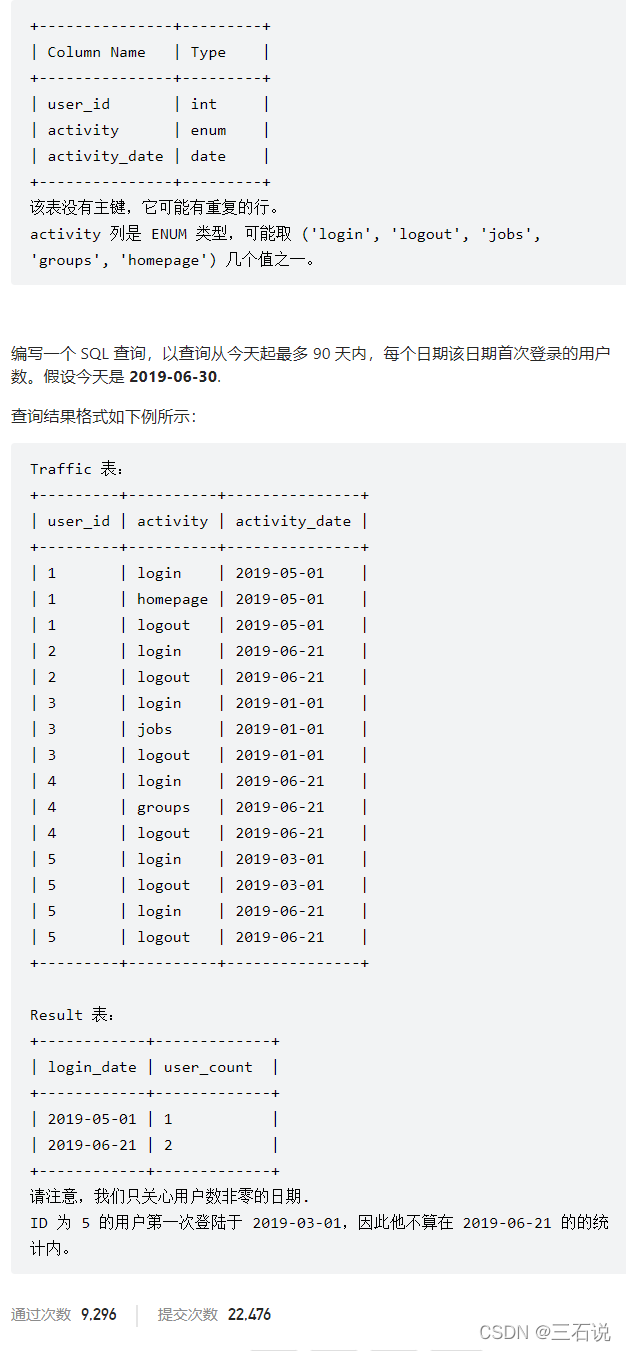
- 源代码:
with first_tmp as ( select user_id, min(activity_date) first_login from traffic where activity = 'login' group by user_id ) select first_login login_date, count(*) user_count from first_tmp where first_login between date_sub('2019-06-30', interval 90 day) and '2019-06-30' group by first_login - 思路:这个题目就关注两个条件,一个是 用户第一次登陆,还有一个是 第一次登陆时间在90天内,然后聚合就可以了
1112. 每位学生的最高成绩
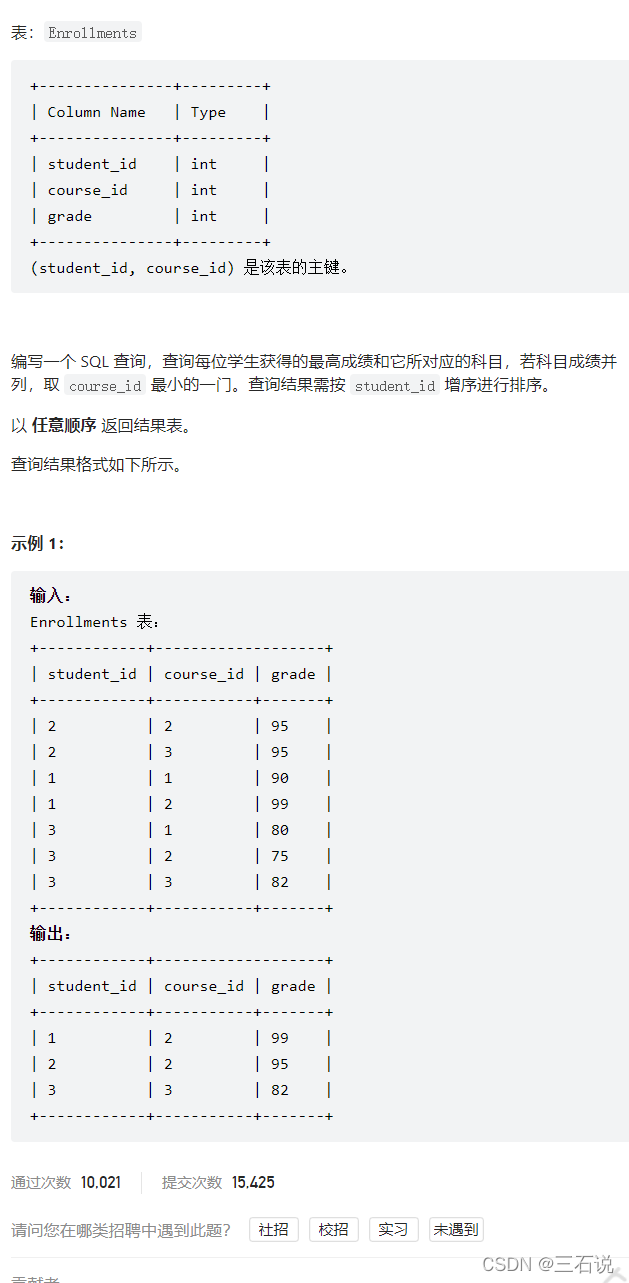
- 源代码:
select student_id, course_id, grade from ( select student_id, course_id, grade, row_number() over(partition by student_id order by grade desc, course_id) rk from enrollments ) t where t.rk = 1 order by student_id; - 思路:这个题目特别明显是一个分组排序的问题,唯一需要注意的是 开窗函数中排序条件有多个,这一点我一开始是忽略了的,因为之前没有写过多个排序条件的开窗函数
1113. 报告的记录
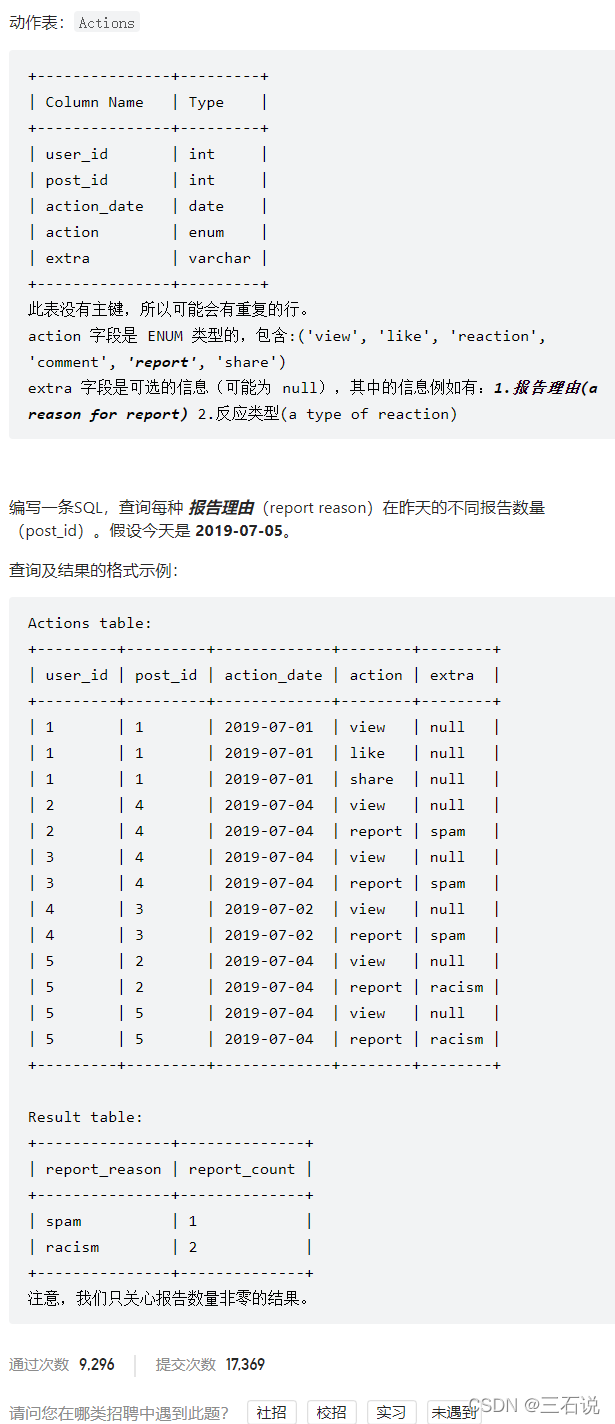
- 源代码:
select extra report_reason, count(distinct post_id) report_count from actions where action_date = '2019-07-04' and action = 'report' group by extra - 思路:弄清楚过滤条件就可以了,另外还需要注意对
post_id进行去重
1126. 查询活跃业务

- 源代码:
with avg_tmp as ( select event_type, avg(occurences) avg_occ from events group by event_type ) select business_id from events join avg_tmp on events.event_type = avg_tmp.event_type where occurences > avg_occ group by business_id having count(*) >= 2; - 思路:需求拆解完就很简单了,也就是先求每个时间类型的平均发生次数,建立中间表,然后和源表进行join,判断条件为:发生次数大于平均发生次数,最后分组聚合,并且判断该业务至少出现2次
1127. 用户购买平台
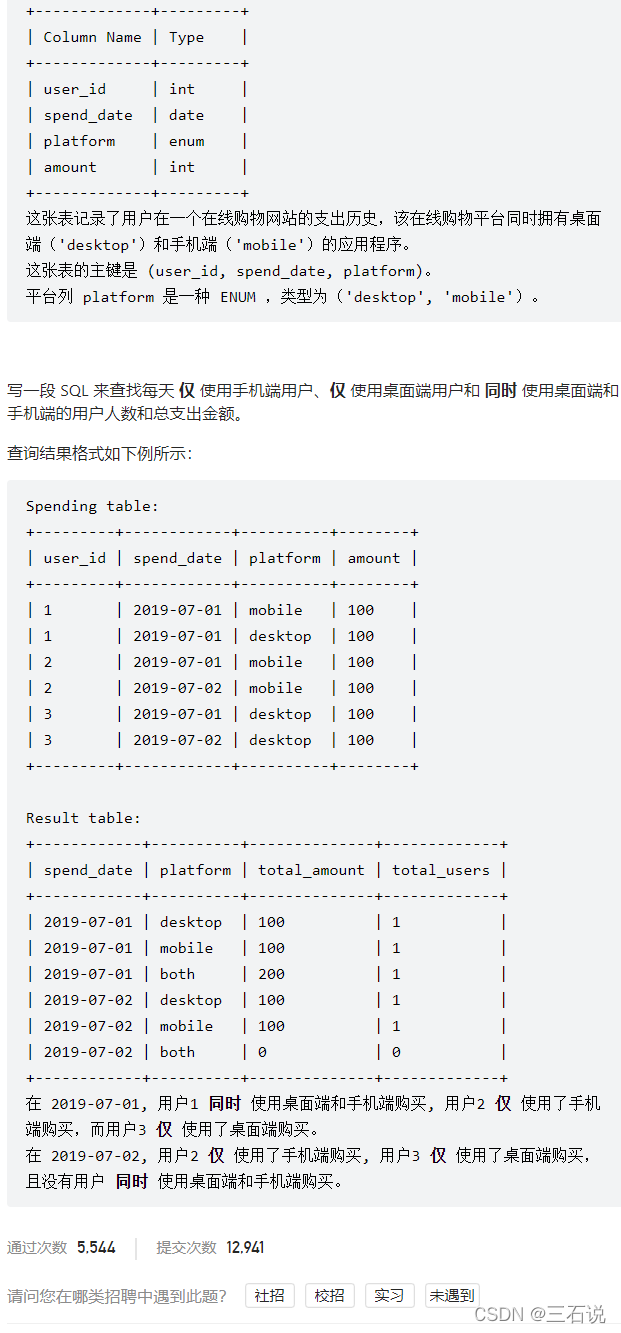
- 源代码:
select t1.spend_date, t1.platform, coalesce(sum(total_amount), 0) as total_amount, coalesce(count(user_id), 0) as total_users from ( select distinct spend_date, 'desktop' as platform from spending union select distinct spend_date, 'mobile' as platform from spending union select distinct spend_date, 'both' as platform from spending ) t1 left join ( select user_id, spend_date, case when count(platform) = 2 then 'both' else platform end as platform, sum(amount) as total_amount from spending group by user_id, spend_date ) t2 on t1.spend_date = t2.spend_date and t1.platform = t2.platform group by spend_date, platform - 思路:我们首先应该求出上面的
t2表,这就是一个分组聚合而已,主要需要清楚按照什么进行分组,聚合字段是什么;因为不管如何,我们都需要输出每种可能,所以我们先构建一张t1表,来和t2表进行left join,t2表中不存在的返回0就可以了 - 难点:经过了两次分组聚合,分组字段不同;根据题目案例的输出格式需要想到要构建一张所有可能的临时表。
1132. 报告的记录 II

- 源代码:
select round(avg(rate) * 100, 2) as average_daily_percent from ( select action_date, count(distinct removals.post_id) / count(distinct actions.post_id) as rate from actions left join removals on actions.post_id = removals.post_id where extra = 'spam' group by action_date ) t - 思路:这个题目使用
left join非常的巧妙,我是分开进行计算的,题解是直接一个语句就写出来了;另外还需要注意对post_id进行去重,因为重复的不用计算。
1142. 过去30天的用户活动 II
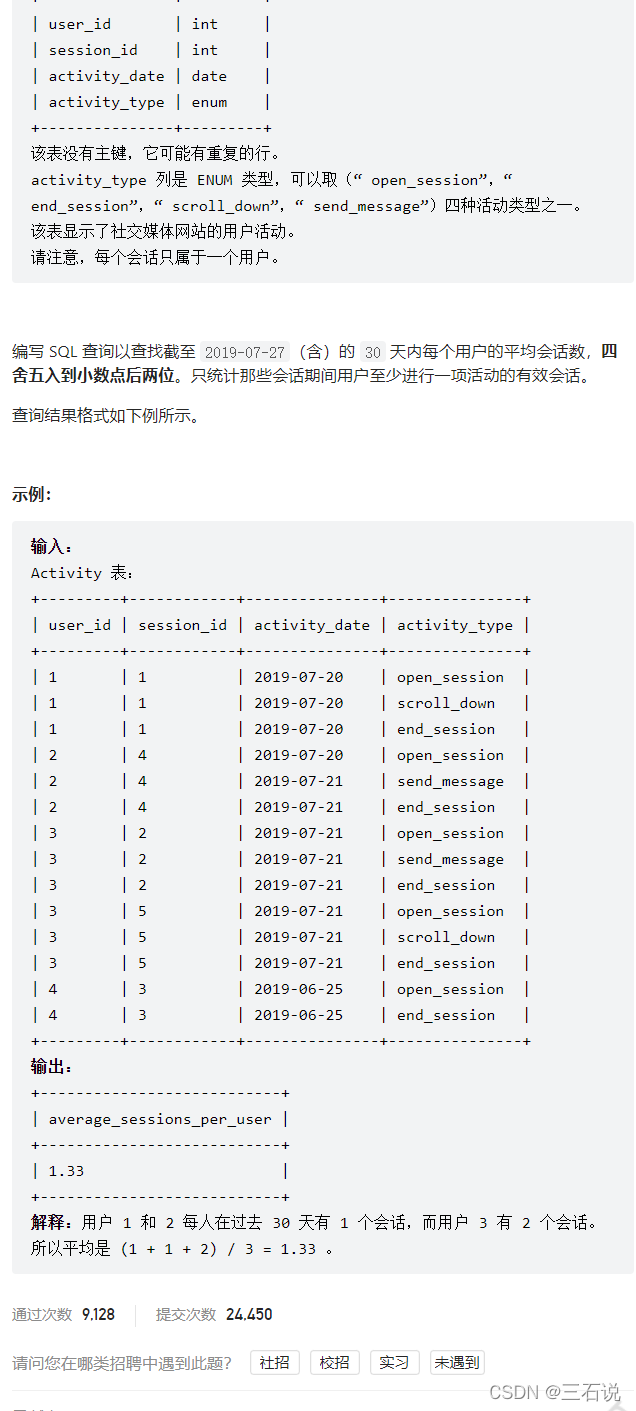
- 源代码:
select ifnull(round(avg(times), 2), 0) as average_sessions_per_user from ( select user_id, count(distinct session_id) as times from activity where datediff('2019-07-27', activity_date) < 30 group by user_id ) t - 思路:本题难点在于一些函数的时候用,比如
datediff可以求出两个日期之间相差的天数
1149. 文章浏览 II
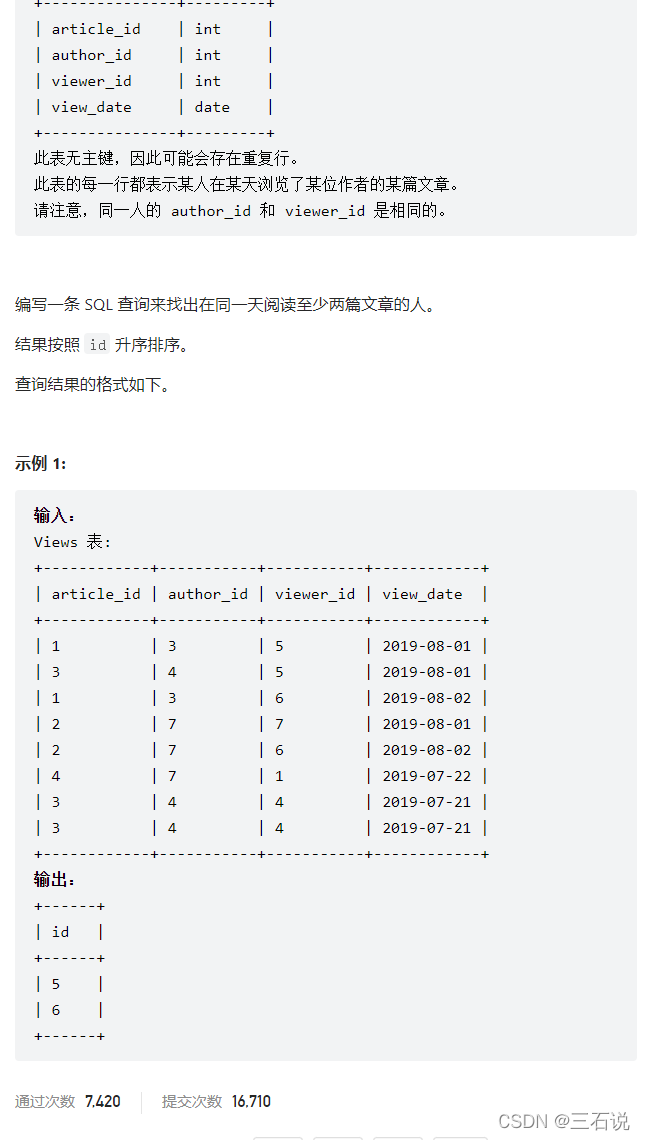
- 源代码:
select distinct viewer_id as id from ( select * from views group by article_id, author_id, viewer_id, view_date )t group by viewer_id, view_date having count(*) >= 2 order by viewer_id - 思路:主要是中间需要对数据表进行去重,也就是按照所有字段进行分组
1159. 市场分析 II
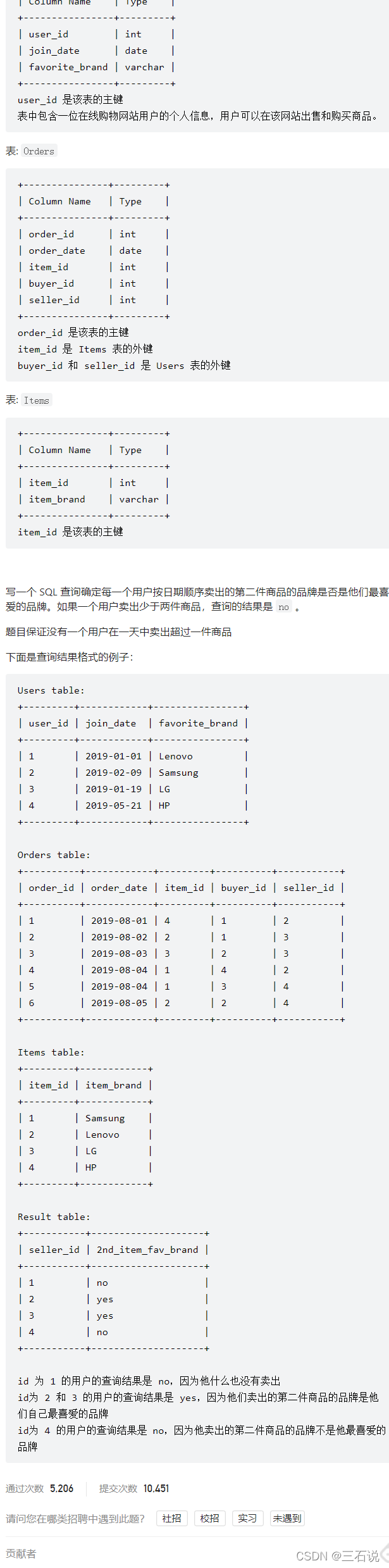
- 源代码:
select users.user_id seller_id, case when seller_id is null then 'no' else 'yes' end 2nd_item_fav_brand from users left join ( select t.seller_id, item_brand from ( select seller_id, item_id, row_number() over(partition by seller_id order by order_date) rk from orders ) t join items on t.item_id = items.item_id where rk = 2 ) t on users.user_id = t.seller_id and t.item_brand = users.favorite_brand; - 思路:首先就是获得第二名的卖家id,和品牌名称,然后和用户表进行join,条件是用户id等于卖家id,并且品牌名称是自己喜欢的品牌
1164. 指定日期的产品价格
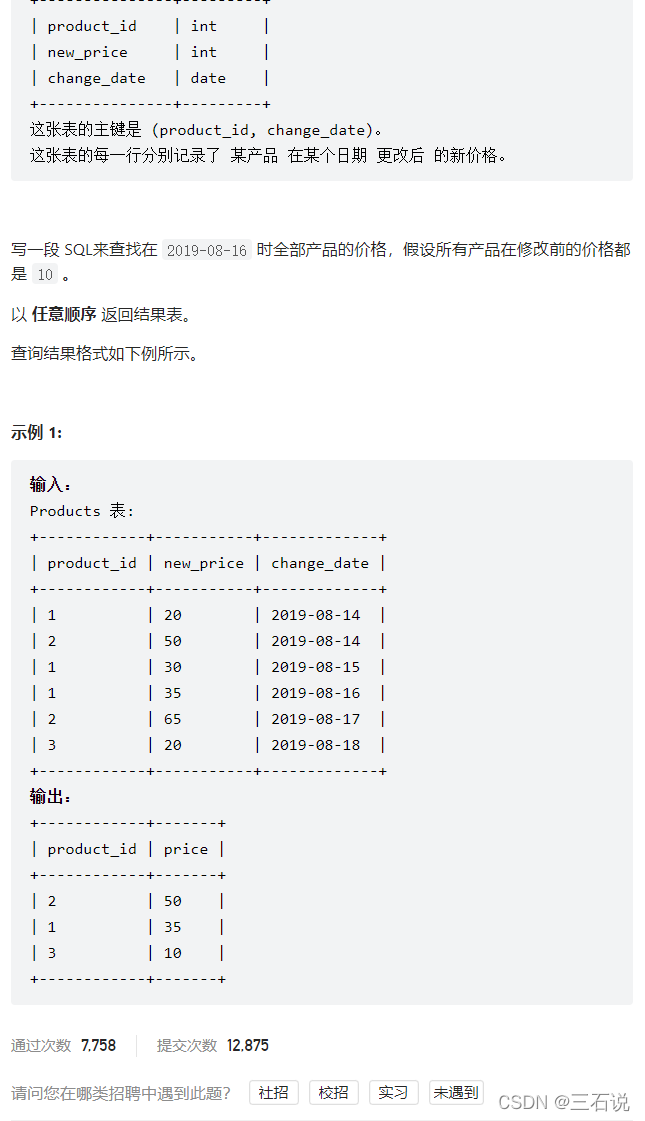
- 源代码:
select p.product_id, ifnull(new_price, 10) as price from ( select distinct product_id from products ) p left join ( select product_id, new_price from products where (product_id, change_date) in ( select product_id, max(change_date) from products where change_date <= '2019-08-16' group by product_id ) ) t on p.product_id = t.product_id - 思路:我们要拿到日期小于等于
2019-08-16的商品id和最新的价格(最新也就是日期要是最大的),然后从原始表中取出所有的商品id,和它进行left join,如果对应的价格为空值,就取默认值10