目录
一、环境与说明
1.1、环境
操作系统:win10 家庭版
编辑器:pycharm edu
版本:python 3.10
使用的库:requests、re、numpy、Image、WordCloud、
思路:使用requests模块发送请求,re模块进行解析页面源代码并提取,numpy模块进行绘制数据可视化,Image进行数据转换、WordCloud进行词云的绘制。
1.2、说明
本次要获取的是内容db电影top250的:黑客帝国2评论(至少100条)
数据可视化是:词云图
数据保存的位置是:当前.py文件同一目录下
要生成词云的图片位置是:当前.py文件同一目录下
小提示:生成的词云图图片可以任意进行改变
使用的url不会是真实的,移植测试注意识别并更改。
二、完整代码
2.1、完整源代码如下
import requests
import re
import jieba
import numpy
import PIL.Image as Image
from wordcloud import WordCloud
from bs4 import BeautifulSoup
class GetDiscuss:
def __init__(self, text_one, text_two, headers):
print(text_one)
self.t_two = text_two
self.headers = headers
# 第一个请求,要拿到跳转到具体电影的页面url
def one_requests(self):
global one_tru
one_tru = [] # 保存全部分页url
one_url = "这里的代码应该是排行top250的url" # 拿到第一个界面的url
one_rep = requests.get(one_url, headers=self.headers) # 发起请求
one_text = one_rep.text # 第一个页面源代码
one_rep.encoding = 'utf-8' # utf-8方式编码第一个页面的源代码
one_result = BeautifulSoup(one_text, "html.parser")
one_div = one_result.find("div", class_="paginator").find_all("a")
global tru
tru = [] # 保存全部分页url
for i in one_div:
once_href = i.get("href")
urls = "排行top250的url" + once_href
tru.append(urls) # 每一个分页都存入
# print(tru)
# 第二次请求,进入具体电影页面,并且进入影评界面
def two_requests(self):
global three_tru
global f_hrefs
global f_href
three_tru = []
two_tru = tru
# print(two_tru)
two_rep = requests.get(two_tru[8], headers=self.headers) # 发起请求
two_text = two_rep.text # 第一个页面源代码
two_rep.encoding = 'utf-8' # utf-8方式编码页面的源代码
# 正则提取url,re.S规则是使.可以匹配空格
two_obj = re.compile(f'<em class="">228</em>.*?<div class="hd">.*?<a href="(?P<two_href>.*?)" class="">', re.S)
two_result = two_obj.finditer(two_text)
for i in two_result:
t_href = i.group("two_href")
# print(t_href) # 输出测试获取的链接是否是我们要的
# 第三次发起请求,进入完整的影评界面
three_rep = requests.get(t_href, headers=self.headers) # 发起请求
three_text = three_rep.text # 页面源代码
three_rep.encoding = 'utf-8' # utf-8方式编码页面的源代码
three_obj = re.compile(f'> <a href="(?P<three_href>.*?)" >', re.S)
three_result = three_obj.finditer(three_text)
for j in three_result:
f_href = j.group("three_href")
# print(f_href) # 输出测试获取的链接是否是我们要的 comments?sort=new_score&status=P
f_hrefs = "https://movie.douban.com/subject/1304141/" + f_href
# print(f_hrefs)
# 实际上是发起的第四次请求,分别拿到5页的评论,要拿更多需要更改上面的x元组
def three_requests(self):
global f_all_hrefs
global f_hrefs
f_all_href = f_hrefs.strip("?")[:-23] # 通过观察得出需要拼接部分的url,进行截取
# 拼接评论完整url
f_all_hrefs = f_all_href + "start={}&limit=20&status=P&sort=new_score"
x = [20, 40, 60, 80, 100, 120]
for k in range(0, 1):
f_all_url = f_all_hrefs.format(x[k])
# print(f_all_url)
four_rep = requests.get(f_all_url, headers=self.headers) # 发起请求
four_text = four_rep.text # 第一个页面源代码
print('4', four_rep.status_code)
# print(four_text)
four_rep.encoding = 'utf-8' # utf-8方式编码第一个页面的源代码
four_obj = re.compile(f'<span class="short">(?P<pape_dis>.*?)</span>', re.S)
four_result = four_obj.finditer(four_text)
for p in four_result:
ones_dis = p.group("pape_dis")
with open("all_dis.txt", mode="a", encoding='utf-8') as file:
file.write(ones_dis)
print(self.t_two)
def word_cloud():
with open("all_dis.txt", encoding='utf-8', mode='r') as f:
text1 = f.read()
text2 = jieba.cut(text1)
wordsDict = {}
for word in text2:
if len(word) == 1:
continue
elif word.isdigit() == True:
continue
elif word in wordsDict:
wordsDict[word] += 1
else:
wordsDict[word] = 1
wordsDict_seq = sorted(wordsDict.items(), key=lambda x:x[1], reverse=True) # 按字典的值降序排序
print(wordsDict_seq[:20])
mask_pic = numpy.array(Image.open("one.jpg"))
text3 = " ".join(jieba.cut(text1))
image = WordCloud(font_path="msyh.ttc", mask=mask_pic).generate(text3)
image = image.to_image()
image.show()
if __name__ == '__main__':
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0",
}
one_pr = "开始爬取"
two_pr = "爬取结束"
global f_hrefs
global f_href
global tru
global one_tru
global three_tru
global f_all_hrefs
example = GetDiscuss(one_pr, two_pr, header)
example.one_requests()
example.two_requests()
example.three_requests()
word_cloud()
三、结果
3.1、结果图片
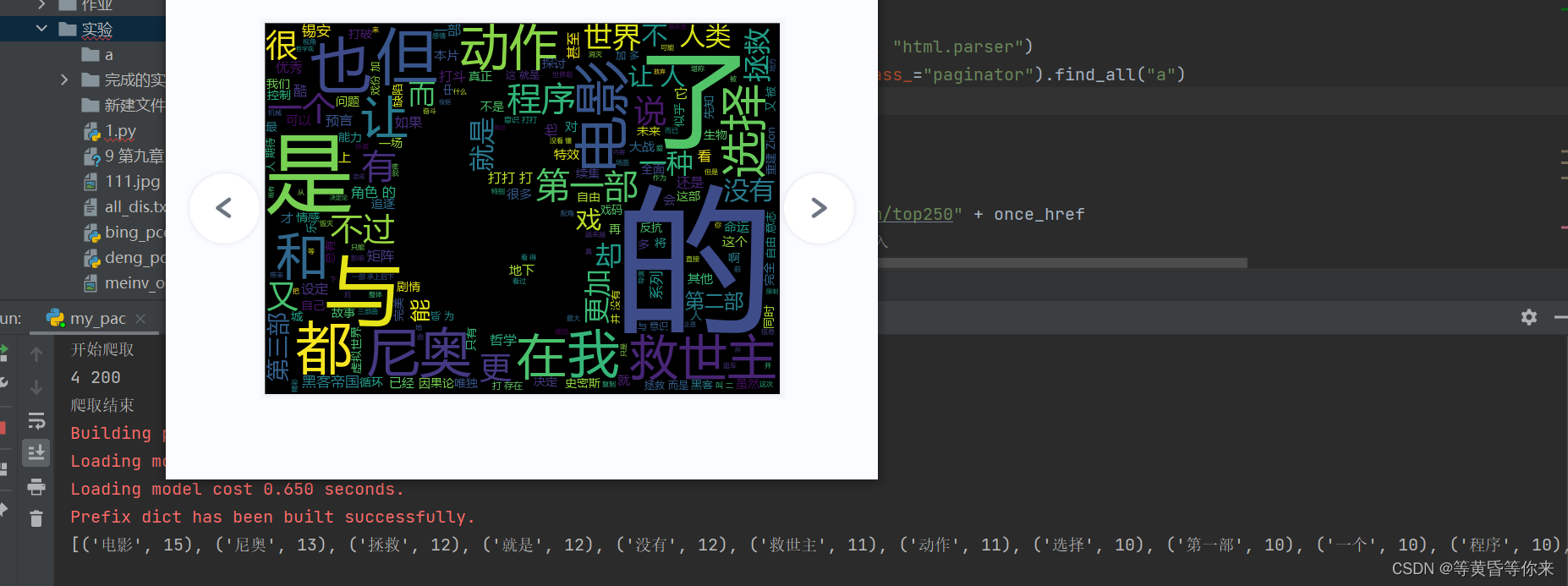
3.2、保存的文件内容结果
