上篇文章(推荐系统(六)双塔模型)介绍了双塔模型,分析了其存在问题以及基本优化思路,本文梳理粗排模型从预估分、排序结果、特征三个方面蒸馏学习精排模型。
目录
1 知识蒸馏
知识蒸馏基础介绍参考文献[1,2],知识蒸馏基本框架如下图,采取 Teacher-Student 模式:
- 将复杂且大的模型作为 Teacher,Student 模型结构较为简单,用 Teacher 来辅助 Student 模型的训练,Teacher 学习能力强,可以将它学到的知识迁移给学习能力相对弱的 Student 模型,以此来增强 Student 模型的泛化能力。
- 复杂笨重但是效果好的 Teacher 模型不上线,就单纯是个导师角色,真正部署上线执行预测任务的是灵活轻巧的 Student 小模型。

如上图所示,粗排和精排学习目标一致,但在特征和网络结构上,精排有着明显优势:
- 特征上,精排有交叉特征,特征表达能力更强;
- 网络结构上,精排特征丰富,可以采用更加复杂的网络
因此在推荐系统中,精排可以作为粗排的 Teacher 模型进行知识蒸馏,下面从预估分、排序结果、特征三个方面介绍粗排蒸馏学习精排模型。
2 预估分蒸馏
2.1 logits
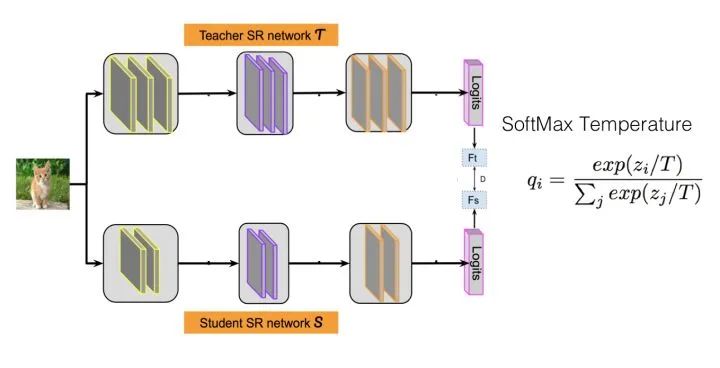
本节简单说明下 Logits 方法的思路。在介绍之前,首先得明白什么是 Logits。我们知道,对于一般的分类问题,比如图片分类,输入一张图片后,经过 DNN 网络各种非线性变换,在网络接近最后一层,会得到这张图片属于各个类别的大小数值 ,某个类别的
数值越大,则模型认为输入图片属于这个类别的可能性就越大。
什么是 Logits? 这些汇总了网络内部各种信息后,得出的属于各个类别的汇总分值 ,就是Logits,
代表第
个类别,
代表属于第
类的可能性。因为 Logits 并非概率值,所以一般在Logits 数值上会用 Softmax 函数进行变换,得出的概率值作为最终分类结果概率。Softmax 一方面把 Logits 数值在各类别之间进行概率归一,使得各个类别归属数值满足概率分布;另外一方面,它会放大 Logits 数值之间的差异,使得 Logits 得分两极分化,Logits 得分高的得到的概率值更偏大一些,而较低的 Logits 数值,得到的概率值则更小。
上图中的公式 就是一个变体的 Softmax 公式,如果把
拿掉或令
,则是个标准的 Softmax 公式,
就是第
个类别的 Logits 数值,
是 Logits 数值经过 Softmax 变换后归属于第
个类别的概率值。
知道了什么是 Logits 后,我们来说什么是 Logits 蒸馏方法。假设我们有一个 Teacher 网络,一个Student 网络,输入同一个数据给这两个网络,Teacher 会得到一个 Logits 向量,代表 Teacher 认为输入数据属于各个类别的可能性;Student 也有一个 Logits 向量,代表了 Student 认为输入数据属于各个类别的可能性。最简单也是最早的知识蒸馏工作,就是让 Student 的 Logits 去拟合 Teacher 的 Logits,即 Student 的损失函数为:
其中, 是 Teacher 的 Logits,
是 Student 的 Logits。在这里,Teacher 的 Logits 就是传给Student 的暗知识。
2.2 基本方法
基本思路:除真实 label 外,把 Teacher 模型 softmax 层输出的类别概率(或 logits),也作为学习目标,使粗排模型与精排模型的预估分尽量对齐。
主要说明两个问题:
(1)预估分蒸馏为什么有效
softmax 层的输出,除了正例之外,负标签也带有 Teacher 模型归纳推理的大量信息[1],比如某些负标签对应的概率远远大于其他负标签,则代表 Teacher 模型在推理时认为该样本与该负标签有一定的相似性。而在传统的训练过程(Hard-target)中,所有负标签都被统一对待。也就是说,知识蒸馏的训练方式使得每个样本给 Student 模型带来的信息量大于传统的训练方式。
(2)温度系数作用
神经网络使用 softmax 层来实现 logits 向类别概率的转换。原始的 softmax 函数:

但是直接使用 softmax 层的输出值作为 soft target,这又会带来一个问题: 当 softmax 输出的概率分布熵相对较小时,负标签的值都很接近 0,对损失函数的贡献非常小,小到可以忽略不计。因此 "温度" 这个变量就派上了用场。下面的公式是加了温度这个变量之后的 softmax 函数:

当 时,为标准的 softmax 函数,越大输出结果越平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
2.3 业界实践
(1)美团搜索[3]

(2)腾讯音乐[5]

(3)爱奇艺[6]
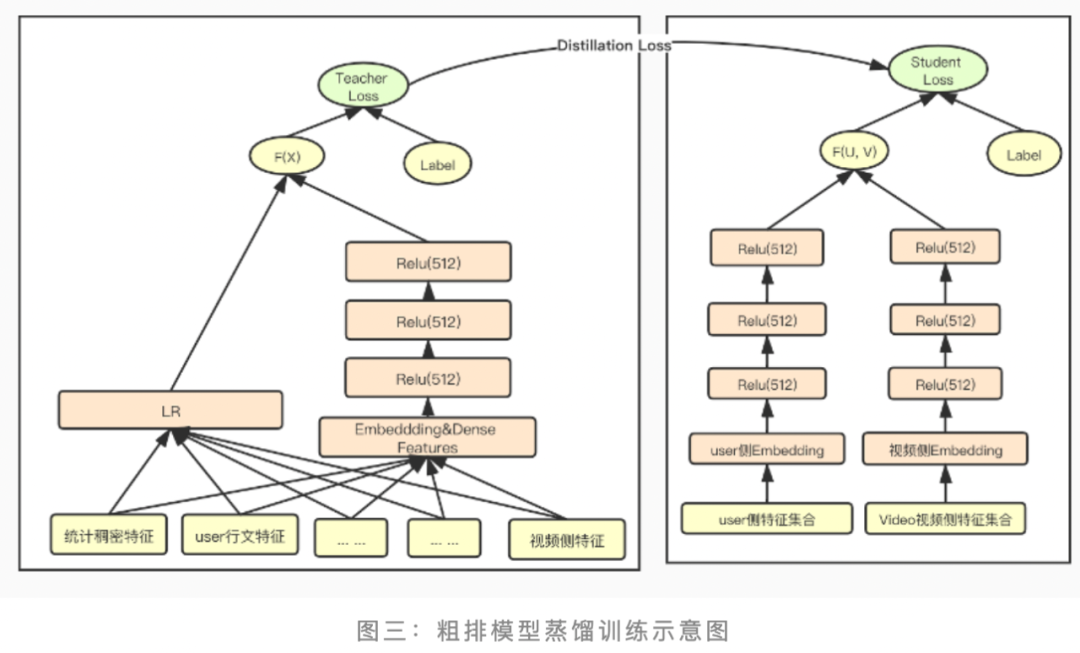
在蒸馏训练的过程中,为了使粗排模型输出的 logits 和精排模型输出的 logits 分布尽量对齐,训练优化的目标从原来单一的粗排模型的 logloss,调整为三部分 loss 的加和:student loss(粗排模型 loss)、teacher loss(精排模型 loss)和蒸馏 loss三部分组成。

其中蒸馏 loss 线上采用的是粗排模型输出和精排模型输出的最小平方误差,为了调节蒸馏 loss 的影响,在该项 loss 前又加了一维超参 lamda,设置超参 lamda 随着训练步数迭代逐渐增大,增强蒸馏 loss 的影响,在训练后期使得粗排模型预估值尽量向精排模型对齐。
(4)58招聘[7]

3 排序结果蒸馏
精排模型的输出结果是有序的,这里面也蕴含了 Teacher 的潜在知识,粗排模型拟合精排模型的排序结果,以此学习精排的排序偏好。
3.1 样本优化
通过精排模型排序结果,构造正负样本,这样既能一定程度缓解粗排模型的样本选择偏置,也能将精排的排序能力迁移到粗排。
(1)负样本扩充[3]

(2)正样本扩充[4]
假设精排每次返回 N 个结果,取列表前 Top K 的排序靠前的结果,将其指定为正例,位置 K 之后的例子作为负例。意思是通过排名最高的一部分数据,来学习精排模型的排序偏好。
3.2 pair-wise蒸馏
精排的排序结果是有序列表,在列表内随机任意抽取两个 Item,都能维持序关系。因此,可以构造成对的训练数据。

4 特征蒸馏
(1)粗排模型一般采用双塔结构,对于双塔结构 User 和 Item 表征向量分离学习,隐层特征蒸馏不太适合,可以通过共享 Embedding 层的方式,蒸馏学习精排 Embedding 特征表示。
(2)对于采用非双塔结构的模型,可以对隐层特征蒸馏[1,2],把 Teacher 和 Student 模型隐层特征向量 MSE 差异最小化作为损失。
(3)对比学习技术也可以应用到粗排建模中,使得粗排模型在蒸馏精排模型的表征时,也能蒸馏到序的关系[3]。


参考:
[1] 深度学习中的知识蒸馏技术(上)
[3] 美团搜索粗排优化的探索与实践
[4] 知识蒸馏在推荐系统的应用
[6] 爱奇艺短视频推荐:粗排篇
[7] 推荐算法在商业化场景中的探索实践