1. pom文件依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.11.8</scala.version>
<flink.version>1.9.0</flink.version>
<kafka.version>1.0.2</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<!--slf4j-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.9</version>
</dependency>
</dependencies>2. 写入数据到kafka代码
def main(args: Array[String]): Unit = {
val properties = new Properties()
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName)
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName)
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "1.2.3.4:9092")
properties.setProperty(ProducerConfig.CLIENT_ID_CONFIG, "producer-1")
properties.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 90000000.toString)
val producer = new KafkaProducer[String, String](properties)
val threadPool = new ScheduledThreadPoolExecutor(
//该参数为核心线程数
4,
//该参数为org.apache.commons.lang3.concurrent中的工厂实现类
new BasicThreadFactory.Builder().namingPattern("thread-call-runner-%d").daemon(true).build())
for (i <- 0 to 3) {
threadPool.submit(new Runnable {
override def run(): Unit = {
while (true) {
producer.send(new ProducerRecord[String, String]("test_wzq", i, i + "号分区key", i + "-" + UUID.randomUUID().toString))
Thread.sleep(4000)
}
}
})
}
Thread.sleep(Long.MaxValue)
}将上述代码中的IP地址和主题名修改为自己的即可,主题分区数为4,为了后面看到读取不同分区数据的效果。
上面的方法可以一直运行写入数据。
3. 读取value数据
flink官网有提供了kafka的连接器,pom依赖引入为:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.9.0</version>
</dependency>该连接器支持读取和写入kafka数据,如果是直接读取kafka的message,也就是读取value值,非常简单,代码如下:
def main(args: Array[String]): Unit = {
import org.apache.flink.api.scala._
val env = StreamExecutionEnvironment.getExecutionEnvironment
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "1.2.3.4:9092")
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group-8")
val source: DataStream[String] = env.addSource(new FlinkKafkaConsumer("test_wzq", new SimpleStringSchema(), properties))
source.print()
env.execute()
}注意代码中的 new SimpleStringSchema() ,这是对于字符串序列化和反序列化的schema,部分源码如下:
/**
* Very simple serialization schema for strings.
*
* <p>By default, the serializer uses "UTF-8" for string/byte conversion.
*/
@PublicEvolving
public class SimpleStringSchema implements DeserializationSchema<String>, SerializationSchema<String>因此直接使用该反序列化模型,可以读取到kafka消息中的value数据,运行结果如下:
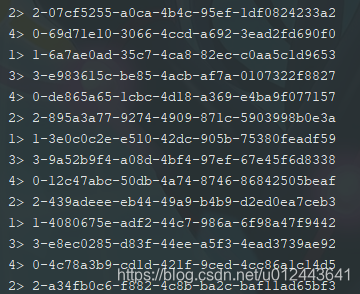
四个并行度输出数据,我电脑是4核,所以默认并行度为4,后面所有读取代码都一样。
4. 读取key-value数据
4.1 使用已提供的反序列化器(不可用)
def main(args: Array[String]): Unit = {
import org.apache.flink.api.scala._
val env = StreamExecutionEnvironment.getExecutionEnvironment
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "dev.cloudiip.bonc.local:9092")
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group-7")
val source: DataStream[tuple.Tuple2[String, String]] = env.addSource(new FlinkKafkaConsumer("test_wzq", new TypeInformationKeyValueSerializationSchema[String, String](classOf[String], classOf[String], env.getConfig), properties))
source.print()
env.execute()
}注意代码 new TypeInformationKeyValueSerializationSchema[String, String](classOf[String], classOf[String], env.getConfig) ,使用的是连接器里提供的反序列化/序列化模型,部分源码如下:
/**
* A serialization and deserialization schema for Key Value Pairs that uses Flink's serialization stack to
* transform typed from and to byte arrays.
*
* @param <K> The key type to be serialized.
* @param <V> The value type to be serialized.
*/
@PublicEvolving
public class TypeInformationKeyValueSerializationSchema<K, V> implements KafkaDeserializationSchema<Tuple2<K, V>>, KeyedSerializationSchema<Tuple2<K, V>>使用该反序列化模型,返回的数据类型为tuple2,直接运行会报错,如下: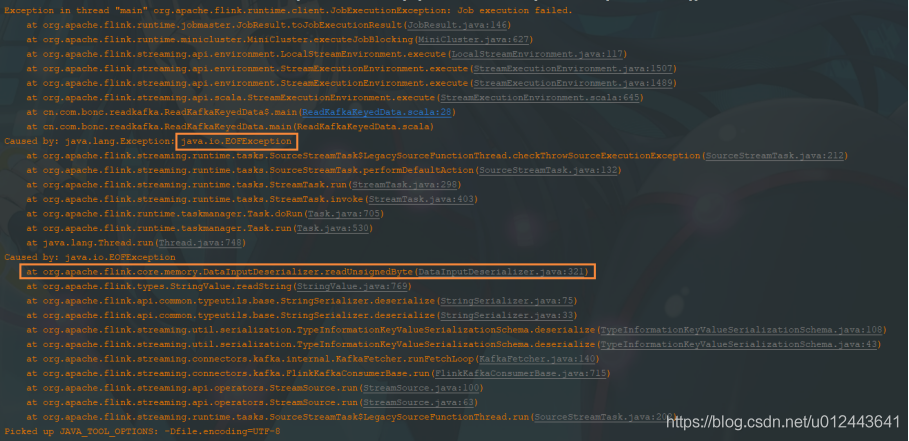
在执行readUnsignedByte函数式报错了,具体原因未知,感兴趣的可以看看源码中的函数体。
4.2 使用自定义反序列化模型
4.2.1 自定义反序列化模型类
/**
* 自定义kafka反序列化模型,将读取到的kafka record中的key、value信息写入二元组
*
* @author wzq
* @date 2019-09-27
**/
class KafkaTuple2DeserializationSchema extends KafkaDeserializationSchema[(String, String)] {
/**
* 用来判断该元素是否为流中的最后一个元素,如果返回true,则会结束发射数据<br>
* 直接返回false,使其一直发射数据,毕竟要用于流式处理
*
* @param nextElement 下一个反序列化完毕的元素
* @return
*/
override def isEndOfStream(nextElement: (String, String)): Boolean = {
false
}
/**
* 反序列化函数,用于将读取到的kafka record封装为需要的对象并返回给flink-source
*
* @param record kafka record消息
* @return 二元组,数据分别为key、value
*/
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
(new String(record.key()), new String(record.value()))
}
/**
* 获取该反序列化器泛型的的类型信息
*
* @return 该反序列化器泛型的的类型信息
*/
override def getProducedType: TypeInformation[(String, String)] = {
TypeInformation.of(classOf[(String, String)])
}
}4.2.2 读取kafka
def main(args: Array[String]): Unit = {
import org.apache.flink.api.scala._
val env = StreamExecutionEnvironment.getExecutionEnvironment
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "dev.cloudiip.bonc.local:9092")
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group-6")
val source: DataStream[(String, String)] =
env.addSource(new FlinkKafkaConsumer[(String, String)]("test_wzq", new KafkaTuple2DeserializationSchema, properties))
source.print()
env.execute()
}运行结果为:
可以看到读取到的数据为二元组。
5. 读取消息所有信息
5.1 自定义反序列化模型类
class KafkaRecord2DeserializationSchema extends KafkaDeserializationSchema[ConsumerRecord[Array[Byte], Array[Byte]]] {
override def isEndOfStream(nextElement: ConsumerRecord[Array[Byte], Array[Byte]]): Boolean = false
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): ConsumerRecord[Array[Byte], Array[Byte]] = {
record
}
override def getProducedType: TypeInformation[ConsumerRecord[Array[Byte], Array[Byte]]] = {
TypeInformation.of(classOf[ConsumerRecord[Array[Byte], Array[Byte]]])
}
}5.2 读取kafka
def main(args: Array[String]): Unit = {
import org.apache.flink.api.scala._
val env = StreamExecutionEnvironment.getExecutionEnvironment
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "dev.cloudiip.bonc.local:9092")
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group-5")
val source: DataStream[ConsumerRecord[Array[Byte], Array[Byte]]] =
env.addSource(new FlinkKafkaConsumer[ConsumerRecord[Array[Byte], Array[Byte]]]("test_wzq", new KafkaRecord2DeserializationSchema, properties))
source.print()
env.execute()
}直接运行结果为:

可以看到通过使用kafka client提供的 ConsumerRecord 类来作为反序列化模型的泛型,就可以直接拿到kafka消息的所有信息。如果业务中需要用到kafka消息的所有信息,则可以使用上面提供的自定义反序列化模型。
6. 读取消息部分信息
如果你只是想读取kafka消息的一部分信息,比如读取key、value、topic等,但是不需要headers等信息,则使用上面的自定义反序列化模型,就会返回很多很多数据,造成资源浪费。
6.1 自定义类
/**
* @param key 消费记录的key
* @param value 消费记录的值
* @param topic 消费记录对应的主题
* @param partition 消费记录对应主题的分区编号
* @param offset 消费记录对应的偏移量
* @author wzq
* @date 2019-09-27
**/
case class KafkaConsumerRecord(key: String, value: String, topic: String, partition: Int, offset: Long)该类用于自定义反序列化模型类的泛型。
直接使用case class,可以使用到其提供的apply、toString等函数,比较方便。
6.2 自定义反序列化模型类
class KafkaRecordDeserializationSchema extends KafkaDeserializationSchema[KafkaConsumerRecord] {
override def isEndOfStream(nextElement: KafkaConsumerRecord): Boolean = {
false
}
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): KafkaConsumerRecord = {
KafkaConsumerRecord(new String(record.key()), new String(record.value()), record.topic(), record.partition(), record.offset())
}
override def getProducedType: TypeInformation[KafkaConsumerRecord] = {
TypeInformation.of(classOf[KafkaConsumerRecord])
}
}6.3 读取kafka
def main(args: Array[String]): Unit = {
import org.apache.flink.api.scala._
val env = StreamExecutionEnvironment.getExecutionEnvironment
val properties = new Properties()
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "dev.cloudiip.bonc.local:9092")
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group-5")
val source: DataStream[KafkaConsumerRecord] =
env.addSource(new FlinkKafkaConsumer[KafkaConsumerRecord]("test_wzq", new KafkaRecordDeserializationSchema, properties))
source.print()
env.execute()
}直接运行结果为:
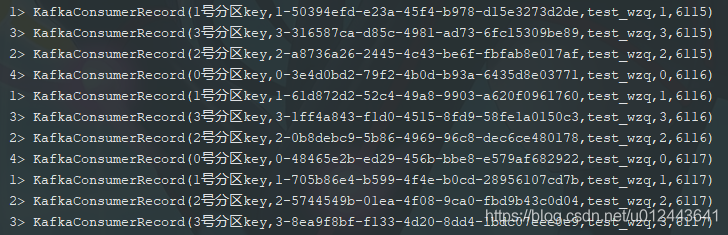
7. 总结
如果你只是想读取kafka消息中的value值,则直接使用 SimpleStringSchema 字符串反序列化模型即可,如果你想要的获取到更多的信息,则可以使用元组、自定义类、使用 ConsumerRecord[Array[Byte], Array[Byte]] 。
建议根据自己的需求来获取自己需要的信息,虽然使用 ConsumerRecord[Array[Byte], Array[Byte]] 可以获取到消息的所有信息,但是将数据传输给flink source,数据量会很大,造成不必要的资源浪费。
