本文为SLAM for Dummies的主要内容翻译文献,主要目的是记录做此领域研究的历程。原文参考SLAM for Dummies,包含部分算法的实现代码,值得仔细研读。水平十分有限,翻译不得当之处还请指正。
1.介绍
本文写作目的是给移动机器人的实时定位预测图(SLAM)一个文献参考,虽然现在有许多相关文献,但对于一个入门学者而言想要完全领会这些应用于SLAM的复杂算法和技术需要耗费大量时间 。因此,希望能够通过本文给读者关于SLAM清楚、简要的认识.但想要真正领会其中的精髓还需要多多实践。
2.关于SLAM
[介绍SLAM(实时定位与测图)起源部分略过]
SLAM主要包含几个部分:1.地标 -> 2.数据关联 -> 3.姿态估计 -> 4.姿态更新及地标更新
每一部分都有多种解决方案,本文将给出相关例子。了解一些相关的背景知识可以帮助你更好的理解本文。
3.硬件
硬件支持十分重要。要想从事SLAM的相关研究,需要有一个移动机器人和距离量测传感器(如:激光扫描仪)。本文只研究算法,不考虑复杂的机器人运动与控制方面的相关内容。[列出了一些基本的量测设备,不再具体翻译,有需要的直接参考原文]
前方重头戏....做好准备!!!
4.SLAM流程
SLAM包含很多步骤,目的是利用环境来更新机器人的位置。因为机器人的测距误差往往比较大,因此不能直接依靠测距信息来估计自己的位置。这就需要提取环境特征,并当机器人再次出现在近似位置时对其重新观测(闭环)。扩展卡尔曼滤波(EKF)是这个算法的核心,是一种可靠的用于更新机器人位置的方法。环境特征被称为地标(landmark),后文会做详细解释。EKF对机器人位置估计的不确定性及环境中地标的不确定性进行连续追踪。SLAM的流程框架如图:
 当机器人产生位移,测距信息改变时,不确定性将感知到这种位置的变化,EKF就可以利用不确定度对量测距离进行更新。在新的环境下,提取环境特征。对于那些已经观测过得地物特征,而后机器人将这些特征与之前更新的特征进行关联,最后EKF使用机器人对地标的重观测更新自己的位置;对于那些之前并未观测的地标将标记为新的地物用于之后的数据关联和重观测。所有这些步骤都会在下面做一个详述。需要指出的是,机器人无论在哪,进行到以上步骤的哪一步,都会有一个对当前位置的估计。
当机器人产生位移,测距信息改变时,不确定性将感知到这种位置的变化,EKF就可以利用不确定度对量测距离进行更新。在新的环境下,提取环境特征。对于那些已经观测过得地物特征,而后机器人将这些特征与之前更新的特征进行关联,最后EKF使用机器人对地标的重观测更新自己的位置;对于那些之前并未观测的地标将标记为新的地物用于之后的数据关联和重观测。所有这些步骤都会在下面做一个详述。需要指出的是,机器人无论在哪,进行到以上步骤的哪一步,都会有一个对当前位置的估计。
下图用于解释这个过程,其中三角表示机器人,五角星表示地标。
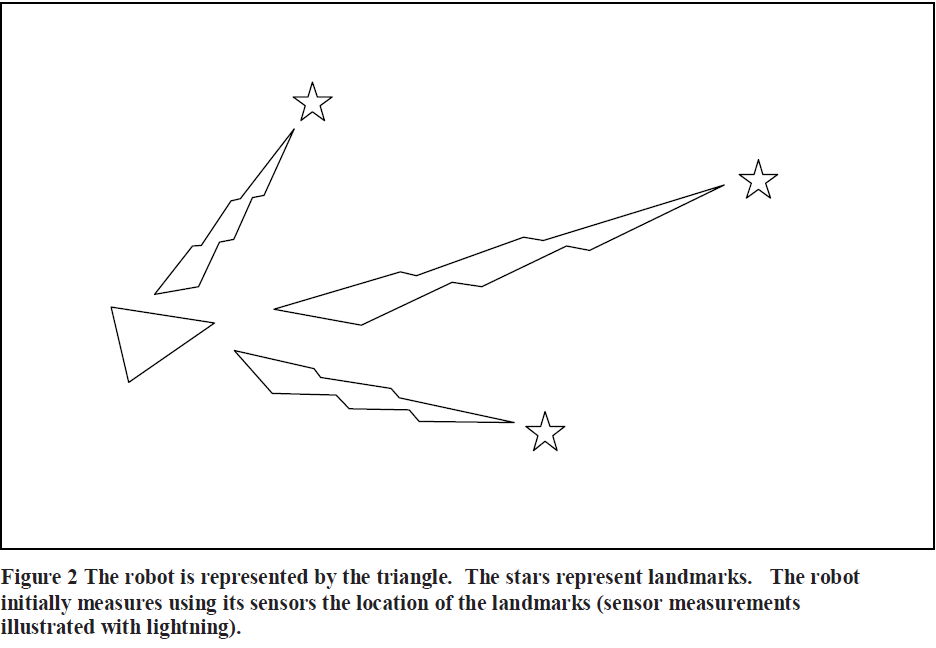


 [ 注记:其实了解卡尔曼滤波(KF)的人都应该清楚,扩展卡尔曼滤波(EKF)是KF的非线性情况,多做了一步线性化。一般线性化的常用方法使泰勒展开,需要一个展开的初始位置。因此KF的运动方程实际上就是求这个初始位置,但这个估计可能不准确,于是就给他一个相应的信任度或是称为权值。有了初始位置再加入距离量测信息,距离量测值也根据其观测质量给出权值,通过两者加权平均得到最终估计值。所以本质上卡尔曼滤波运动方程和量测方程就是估计与修正的过程。得到最终的位置也并非完全准确地,也就是说并非真实的位置,因为距离量测值和里程计量测值都是有误差的。]
[ 注记:其实了解卡尔曼滤波(KF)的人都应该清楚,扩展卡尔曼滤波(EKF)是KF的非线性情况,多做了一步线性化。一般线性化的常用方法使泰勒展开,需要一个展开的初始位置。因此KF的运动方程实际上就是求这个初始位置,但这个估计可能不准确,于是就给他一个相应的信任度或是称为权值。有了初始位置再加入距离量测信息,距离量测值也根据其观测质量给出权值,通过两者加权平均得到最终估计值。所以本质上卡尔曼滤波运动方程和量测方程就是估计与修正的过程。得到最终的位置也并非完全准确地,也就是说并非真实的位置,因为距离量测值和里程计量测值都是有误差的。]
5.激光数据
SLAM的第一步是获得环境数据,采用激光扫描仪,获得的就是激光数据。[简单介绍了一下量测数据的格式之类的,并给出了SICK激光扫描仪的激光数据处理代码,需要注意:1.弄清楚所采数据所对应的激光束 2. 有一个门限值,超过了说明该光束此次测量数据错误]
6.里程计数据
里程计数据是SLAM中很重要的一部分,主要用来估计机器人的粗略位置用于EKF解算。一个难点是确保激光数据与里程计数据时间同步。一般用于时间同步的方法是外推。由于里程计数据是连续的并且对于机器人的控制量是已知的,我们可以很容易的得到里程计的外推数据。另外一种方法是采用时间触发装置,该装置每触发一次里程计和激光扫描仪响应一次。
7.地标
地标应具有:1 便于从环境中分辨,独特性较强,不与别的物体产生混淆;2 便于从各个角度重新观测的特点;3 不能过少;4 是静止的,避免歧义;地标主要用于机器人的定位。在室内环境中,墙角、地线常用来做地标。
8.地标提取
当我们决定了地标是什么,就可以将它从传感器数据从提取出来。特征提取的方法有很多,依提取目标和所选用传感器不同而有差异。激光扫描中常用的两种方法是Splike和RANSAC。
- Spike 地标
spike特征提取通过极值寻找特征。当相邻两个距离量测值的差异大于某个特定的值将该距离量测值标记为特征值。Spike可以用于突变地标的探测,但对于连续变化的地标这种算法很显然是不可行的。
 RANSAC(Random Sampling Consensus)
RANSAC(Random Sampling Consensus)
RANSAC方法可以从激光扫描数据中提取出一条直线,并将其作为地标。方法:通过激光扫描仪得到一系列点,从中随机选取几个样本做最小二乘拟合,再将样本以外的观测值与该直线做比对,若观测值得分布符合这条直线,则认为提取出了这条直线。这里设置了一个门限,表示满足该直线分布的数据个数。思想:在满足1.仍有未关联的点 2.剩余的点数多于所设门限值 3.循环少于最大采样次数时执行循环,从剩余点中随机取出一个,在当前所有样本的一定角度内再取样若干点进行最优拟合,判断符合该直线的点数,若多于门限值则将该随机取样点列入该直线地标列表中,并从未关联数据列表中剔除。
EKF输入值是相对机器人位置的距离和方位角。通常取提取的特征直线到机器人距离最近的点,如下图:

或是扩展EKF的使用面,可以用来处理线而不是点。这里不再做深入讨论。
- 更多方法
扫描配准法。[原文附录A给出代码,可以用于参考]
9.数据关联
数据关联的一个难点在于不同时刻扫描得到的特征地标之间的匹配,也称为重观测。在数据关联中可能会遇到:1. 不能每次都重观测到某一地标(上次看到了,下次不一定看到) 2.将某一物体标记为地标,之后再也看不到了(再也不见) 3. 错误的将某地标与之前的地标进行关联。前两个种情况在第七节已经做了解释,这两种情况下不会将其标记为地标,因此第三种情况是最大的问题。它意味着将错误地估计自己当前的位置。为避免这种情况,在建立地标数据库时,第一步就是若不是观测到某一地物N次以上,不将其作为地标。
数据关联一般采用距离最近法:1. 特征提取 -> 2. 将该特征与最距离最近的并且出现了N次的路标关联 -> 3.关联验证。若通过则将该路标出现次数加1,否则在数据库中建立一个新的路标。
其中关联验证的验证门限就是EKF给定的地标观测的不确定度限制。因此我们可以通过判断地标是否在不确定度范围内来决定观测到的地标是否为数据库中的地标,这个区域可以由误差椭圆画出。
10.EKF(重点来了!!高能预警!!)
只要地标提取和数据关联完成了,那么EKF分为三步:1. 用里程计数据更新当前的姿态 2. 用重观测的路标数据进行姿态更新的修正 3. 当前姿态中增加新路标。
第一步十分简单,就是一个简单的动态方程,如:姿态(x,y,theta),控制量为(dx,dx,dtheta),则估计结果为(x+dx,y+dy,theta+dtheta)。
第二步,进行地标的重观测。使用运动方程的位置估计值可以估计出地标在这个姿态下的位置,而这个位置与地标的量测位置是有偏差的(因为通过运动方程得到的位置估计偏差很大),这个偏差称为新息(innovation)。所以实际上,新息反映的就是机器人估计位置与实际位置的偏差。[ 正如我们上文说的,EKF就是利用量测值,即重观测到上一时段的地标,来修正这个偏差 ]。在第二步中,每个观测地标的不确定度同样要被更新。举个例子,如果当前观测的不确定度十分小,从这个位置在低不确定下重观测一个地标将增加地标的准确性,直白点就是解算时的权值附的更大一点,因为我们更信任这个量测值。
第三步,在当前的姿态中。向机器人地图增加新的地标。
[ 结合上文分析,EKF的流程:1. 通过里程计获得概略位置,并在此基础上计算地标的位置。2. 由测距设备获得量测值,通过量测值的特征提取(Spike算法、RANSAC算法等)获得地标,将当前时刻的地标与之前的地标匹配,得到机器人的新息,并重新估计自己的位置。3. 带回观测方程,得到此次观测的各个地标的位置估计及其不确定度。]
- 系统状态:X

- 协方差阵:P
协方差用来描述两个变量的相关程度,在SLAM过程中不断更新,初值P=A为对角阵。
协方差矩阵是一个非常重要的矩阵,它包含了机器人位置的方差,地标的方差,机器人位置与地标的协方差,地标之间的协方,矩阵的形式如下图。其中对角线上,A为机器人位置3*3的方差阵;B位第一个地标2*2的方差阵,直到C;非对角线上,D表示机器人位置与第一个地标之间2*3的协方差阵,E为D的转置;G表示第一个地标与第N个地标之间的协方差阵,F为G的转置;随着地标数据库的不断更新加入新的地标,姿态矩阵X与协方差阵P也不断变大。

- 卡尔曼滤波增益:K

- 量测模型的加可比矩阵:H
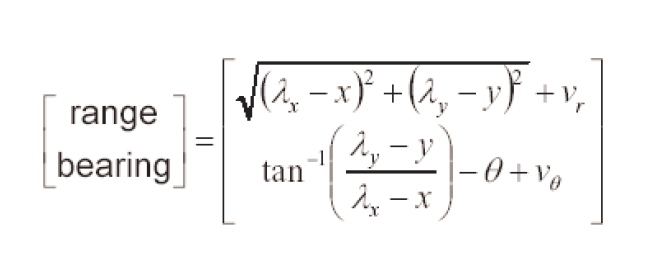 对观测模型求偏导,可的加可比矩阵:
对观测模型求偏导,可的加可比矩阵:
 H表明距离和方位角相对于x,y,theta的变化量。第一行第一个元素是距离在x方向的变化,第二个元素是距离在y方向的变化,第三个元素是距离相对于theta的变化。第二行是方位角相对x姿态的变化。EKF中H矩阵的基本形式就是这么一个2*3的矩阵,但在SLAM中,由于姿态矩阵X为(3+2n)的列矩阵,因此需要扩展H以保证矩阵可以正常运算。
H表明距离和方位角相对于x,y,theta的变化量。第一行第一个元素是距离在x方向的变化,第二个元素是距离在y方向的变化,第三个元素是距离相对于theta的变化。第二行是方位角相对x姿态的变化。EKF中H矩阵的基本形式就是这么一个2*3的矩阵,但在SLAM中,由于姿态矩阵X为(3+2n)的列矩阵,因此需要扩展H以保证矩阵可以正常运算。
 该矩阵前一部分是常规的量测矩阵,由于EKF的姿态估计。后面为每个地标添加两列,上面的矩阵就表示采用第二个地标。根据量测模型,对第二个地标的xy求偏导即可得到-A,-B,-C,-D;
该矩阵前一部分是常规的量测矩阵,由于EKF的姿态估计。后面为每个地标添加两列,上面的矩阵就表示采用第二个地标。根据量测模型,对第二个地标的xy求偏导即可得到-A,-B,-C,-D;
- 动态模型的加可比矩阵:A
动态模型的加可比矩阵A与预测模型紧密相关,因此我们先来看看动态模型。动态模型定义了在给定上一时刻位置和控制输入量的前提下怎样计算一个机器人预期的位置。 公式如下:
 detat是前进方向的变量,对于不同的量测设备,公式可能不同。求偏导可得:
detat是前进方向的变量,对于不同的量测设备,公式可能不同。求偏导可得:
 由于动态模型只与机器人位置有关,因此不需要考虑地标,不对矩阵做扩展。
由于动态模型只与机器人位置有关,因此不需要考虑地标,不对矩阵做扩展。
- SLAM特定的加可比矩阵:
 第二个是地标相对于距离和方位角的动态模型加可比矩阵Jz
第二个是地标相对于距离和方位角的动态模型加可比矩阵Jz

- 过程噪声Q,W
 C代表里程计的精度,一般由实验统计得到。
C代表里程计的精度,一般由实验统计得到。
- 量测噪声R,V
rc和bd即为量测精度的平方。
- SLAM的EKF过程
- 由里程计数据更新当前机器人姿态
这一步称为预测,我们通过里程计数据更新当前姿态。我们采用以下方程
在每次循环时同样要更新动态模型加可比矩阵A和过程噪声Q
 最终我们可以算出新的协方差阵。我们仅更新机器人位姿部分的3*3矩阵下面对姿态与相应地标的协方差阵进行更新
最终我们可以算出新的协方差阵。我们仅更新机器人位姿部分的3*3矩阵下面对姿态与相应地标的协方差阵进行更新
- 通过对地标的重观测更新姿态
由于里程计误差,我们得到的位置估计很不准确,我们要通过对地标的观测补偿这些误差。根据上文讨论的特征地标提取及关联,用已关联的特征地标我们可以计算出机器人实际位置相较于我们对他的估计位置的位移,再用位移量更新机器人位置。第二步将进行所有的重观测,而那些新地标将在第三步进行处理,这也有助于减少这一步的运算量,因为姿态矩阵X和协方差阵P都更小了。
于是用当前位置的估计值和地标数据库中的地标坐标可以计算与地标的距离和方位角,这个值再与我们的量测值z进行比较。H计算如下
有了H就可以计算卡尔曼滤波增益K

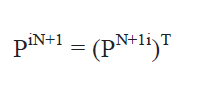 最终计算新的位置估计
最终计算新的位置估计
- 添加新的地标到当前姿态下





[ 这一块比较简单就不再详述 ]
这就完成了SLAM的第一次移动,现在机器人可以进行第二次移动了,如此循环可以一直走下去了。
11. 结语
这里提出的SLAM解决方案十分基础[ 连闭环都没有 ]还有很多提升空间。比如闭环的问题。这个问题很可能出现,当机器人回到一个他来过的地方,机器人需要能够辨认出这个地方并且用新的信息去更新自己的位置。另外,在机器人回到一个已知位置的之前需要更新地标,回到这个一直为之后,修正值传播后要与先前的结果闭合。
还可以将SLAM于栅格地图结合采用d,A*等算法对路径进行规划。