SparkMLlib的简介
MLLIB是Spark的机器学习库。提供了利用Spark构建大规模和易用性的机器学习平台,组件:
- ML 算法:包括了分类、聚类、降维、协同过滤
- Featurization特征化:特征抽取、特征转换、特征降维、特征选择
- Pipelines管道:tools for constructing, evaluating, and tuning ML Pipelines
- Persistence持久化:模型的保存、读取、管道操作
- Utilities:提供了线性代数、统计学以及数据处理工具
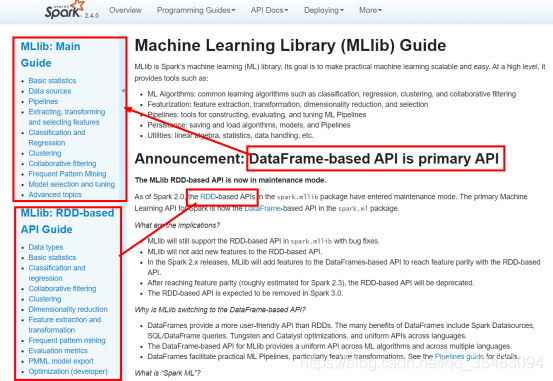
基于DataFrame的API是主要API
*Spark ml基于DataFrame的API
*Spark mllib基于RDD的API
基于MLlib RDD的API现在处于维护模式。
从Spark 2.0开始,软件包中基于RDD的API spark.mllib已进入维护模式。Spark的主要机器学习API现在是包中基于DataFrame的API spark.ml。
有什么影响?
- MLlib仍将支持基于RDD的API spark.mllib以及错误修复。
- MLlib不会为基于RDD的API添加新功能。
- 在Spark 2.x版本中,MLlib将为基于DataFrames的API添加功能,以实现与基于RDD的API的功能奇偶校验。
- 在达到功能奇偶校验(粗略估计Spark 2.3)之后,将弃用基于RDD的API。
- 预计将在Spark 3.0中删除基于RDD的API。
为什么MLlib会切换到基于DataFrame的API?
-
- DataFrames提供比RDD更加用户友好的API。DataFrame的许多好处包括Spark数据源,SQL / DataFrame查询,Tungsten和Catalyst优化以及跨语言的统一API。
- 基于DataFrame的MLlib API跨ML算法和多种语言提供统一的API。
- DataFrames有助于实用的ML管道,特别是功能转换。有关详细信息,请参阅管道指南。
什么是“Spark ML”?
- “Spark ML”不是官方名称,但偶尔用于指代基于MLlib DataFrame的API。这主要是由于org.apache.spark.ml基于DataFrame的API使用的Scala包名称,以及我们最初用来强调管道概念的“Spark ML Pipelines”术语。
MLlib已被弃用吗?
- MLlib包括基于RDD的API和基于DataFrame的API。基于RDD的API现在处于维护模式。但是这两种API都没有被弃用,整个也没有MLlib。
- 两套API的介绍
SparkMLlib的环境支持
- Spark单机版本
首先在官网下载Spark预编译版本,将lib目录下的spark-assembly-1.3.0-hadoop2.4.0.jar文件复制到IDEA安装目录的lib文件夹下。
单击IDEA菜单上File选项,选择Project Strcture,在弹出的对话框单击左侧的Libraries,之后单击中部上方绿色+号,添加刚才下载的jar包文件即可。
- Maven构建依赖环境
在pom文件中加入mllib包的依赖,保存后IDEA会帮我们自动下载。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
**代码基于2.0.2语法代码
SparkMLLIB
MLlib是Spark机器学习库,它是MLBase的一部分,MLBase一共分为一下4部分:
- ML Optimizer:会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数来处理用户输入的数据,并返回模型或者其他的帮助分析结果。
- MLLIB是一个进行特征提取的和高级ML编程抽象的算法实现的API平台。
- MLLIB是Spark实现一些常见的机器学习算法和实用程序。
- MLRuntime是基于Spark计算框架,将Spark的分布式计算应用到机器学习领域。
MLlib提供了常见机器学习算法的实现,包括分类、聚类、协同过滤和降维等。使用MLlib来做机器学习工作通常只需要在对原始数据处理之后,然后直接调用相应的API就可以实现了。但是想要选择合适的算法,必须了解算法的原理以及MLlib API。接下来比较下Spark.mllib和spark.ml
Spark.mllib已经很长时间了,1.0之前的版本已经包含了,提供算法实现都是基于原始的RDD,我们只需要掌握mllib的API就可以完成机器学习工作。但是想要构建完整并且复杂的机器学习流水线是比较困难的,因此有了Spark.ml。
Spark ML Pipeline从Spark1.2版本开始,目前已经从Alpha阶段毕业,成为可用的并且较为稳定的新的机器学习库。ML Pipeline弥补了MLlib库的不足,向用户提供了一个基于DataFrame的机器学习的工作流式API套件,使用ML Pipeline API我们可以很方便地把数据处理、特征转化、正则化以及多个机器学习算法联合起来,构建一个单一完整的机器学习流水线。
从官方文档看,Spark ML Pipeline虽然是被推荐的机器学习方式,但是不会在短期内替代原始的MLlib库,因为MLlib已经包含了丰富稳定的算法实现,并且部分ML Pipeline实现基于MLLib。实际工作中,并不是所有的机器学习过程都需要构建成一个流水线,有时候原始的数据格式整齐且完整,而且使用单一的算法就能实现目标,也没有把事情复杂化,采用最简单且容易理解的方式才是正确的选择。
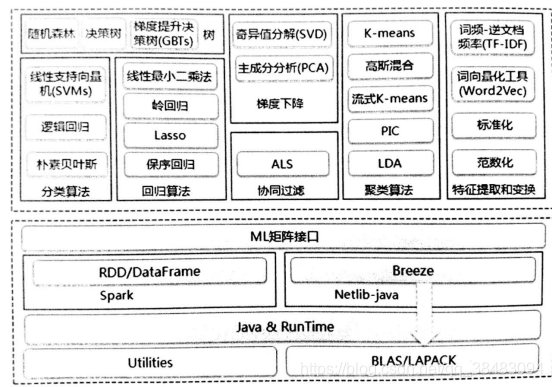
算法架构如下:
MLLIB主要包含两个部分:
- 底层基础:主要包括Spark的运行库、矩阵库和向量库。其中向量接口和矩阵接口基于Nelib和BLAS/LAPACK开发的线性代数库Breeze。MLlib支持本地的密集向量和本地向量,并且支持标量向量;同时支持本地矩阵和分布式矩阵,分布式矩阵分为:RowMatrix、IndexedRowMatrix和CoordinateMatrix等。
- 算法库:包含分类、回归、聚集、协同过滤、梯度下降和特征提取和变换等算法。