1.基本思想
场景:动作在变,环境不变
需要解决的问题:如何获取动作信息和环境信息?
对于环境信息,我们可以取视频中的某一帧出来,利用卷积等方式提取特征,即可获取环境信息。对于动作信息,我们可以采样出视频中的包含时间信息的图像序列,通过3D卷积等方式提取特征。
但是,我们需要考虑一个问题,即速度,假如我们对每一帧进行处理,网络复杂度比较大,无法满足实时处理的需求。但是,对于一个动作,虽然是一个连续的过程,我们也可以通过有间隔的采样去表示这个动作。这样就能够减少大量的运算。

2.网络结构分析
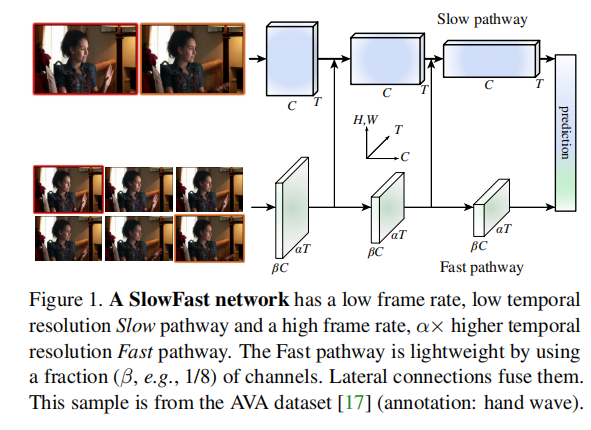
Slow Fast具有两条路径,(i)一个缓慢的路径,在低帧率下运行,以捕获空间语义,即获得环境信息(ii)一个快速的路径,在高帧率下运行,以捕获精细时间分辨率的运动。即动作信息,快速路径可以通过减少其通道容量而变得非常轻,通道数为slow 路径的倍,但是fast路径具有高帧率(
),且在时间维度不进行降采样。
对于特征融合,网络采用将fast提取的信息融合到slow pathway中,即将动作信息融合进入环境信息。
最后进行网络的预测。
3.网络结构设计分析
第一层data layer为采样层,对于slow pathway,每16帧采样1帧,对于fast pathway,每2帧采样1帧。
网络基础结构采用resnet,但是值得注意的是,这里是3D卷积,对于slow pathway,在浅层时间维度上卷积核为1,即只提取静止信息,这是由于实验观察,即在早期的层中使用时间卷积会降低准确性。作者认为,这是因为当物体移动快速且时间步幅较大时,除非空间感受域足够大(即在后面的一层),否则在时间感受域内几乎没有相关性。但作者在实验中发现,在深层(res4/res5)上,提取时间维度上的特征能够提升网络性能,故stride为3.在fast pathway中,各个网络层均在时间维度上提取特征,fast pathway在每个块中都具有非退化的时间卷积。这是由于观察到该路径具有良好的时间分辨率的时间卷积捕捉详细的运动。此外,快速路径在设计上没有时间降采样层。值得注意的是,在slow pathway和fast pathway,H,W均保持相等。
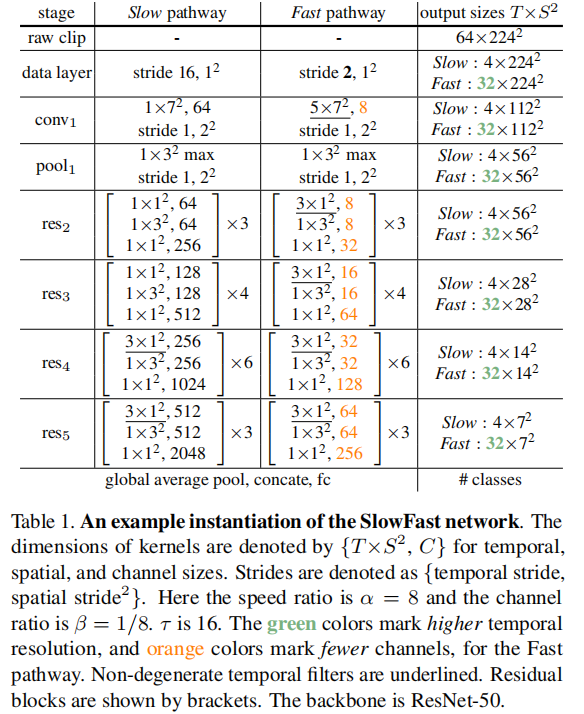
特征融合:论文中给出了3种特征融合方法,即:
(i) Time-to-channel: 将{αT,S^2,βC}重塑并转置为{T,S^2,αβC},这意味着将所有的α帧打包到一个帧的通道中。
(ii) Time-strided sampling: 简单地从每个α帧中取样一个,所以{αT,S^2,βC}就变成了{T,S^2,βC}
(iii) Time-strided convolution: 我们使用2βC输出通道和步幅=α对5×12内核进行三维卷积。
但是经过实验证明,经过使用2βC输出通道和步幅=α对5×12内核进行三维卷积效果是最好的。
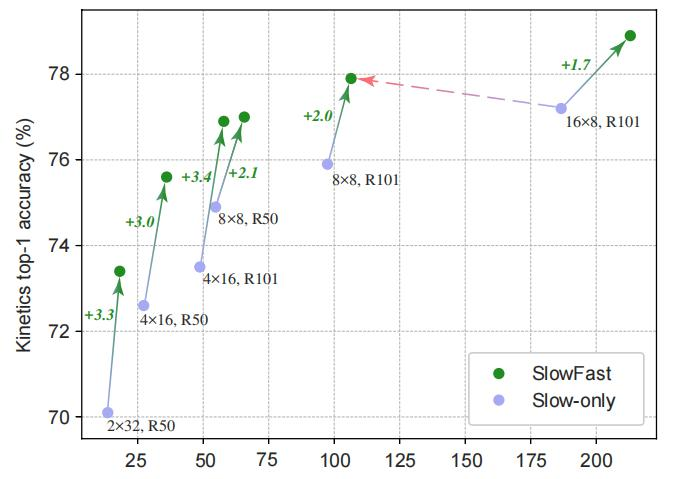
效果分析: