一 简介
朴素贝叶斯算法是有监督的学习算法,解决的是分类问题,如客户是否流失、是否值得投资、信用等级评定等多分类问题。该算法的优点在于简单易懂、学习效率高、在某些领域的分类问题中能够与决策树、神经网络相媲美。但由于该算法以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提,就会导致算法精度在某种程度上受影响。
二 朴素贝叶斯理论
把样本空间划分成容易研究的几种情况。
- 全概率公式(由原因到结果)考察在每一种情况下事件B发生的概率,计算B的概率。
- Bayes公式(由结果到原因)在事件B发生的条件下,考察每种情况出现的条件概率。
条件概率
公式推导
我们需要了解什么是条件概率(Conditional probability),就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。
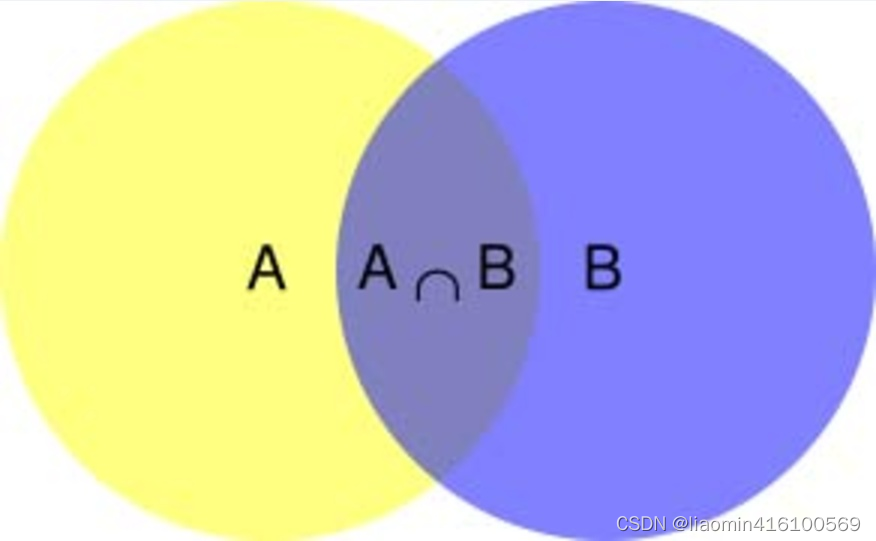
根据文氏图,可以很清楚地看到在事件B发生的情况下,事件A发生的概率就是P(A∩B)除以P(B)。
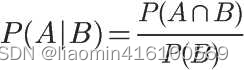
因此,
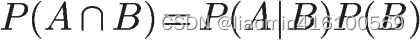
同理根据条件概率知道A发生时B的概率
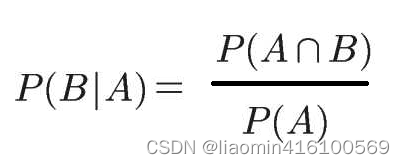
转换下
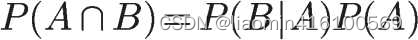
所以

即
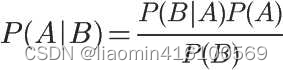
这就是条件概率的计算公式。
计算案例
引例.掷一枚质地均匀的骰子,
- 向上的点数是偶数”的概率是多少?
- 向上的点数是偶数并且大于4”的概率是多少?

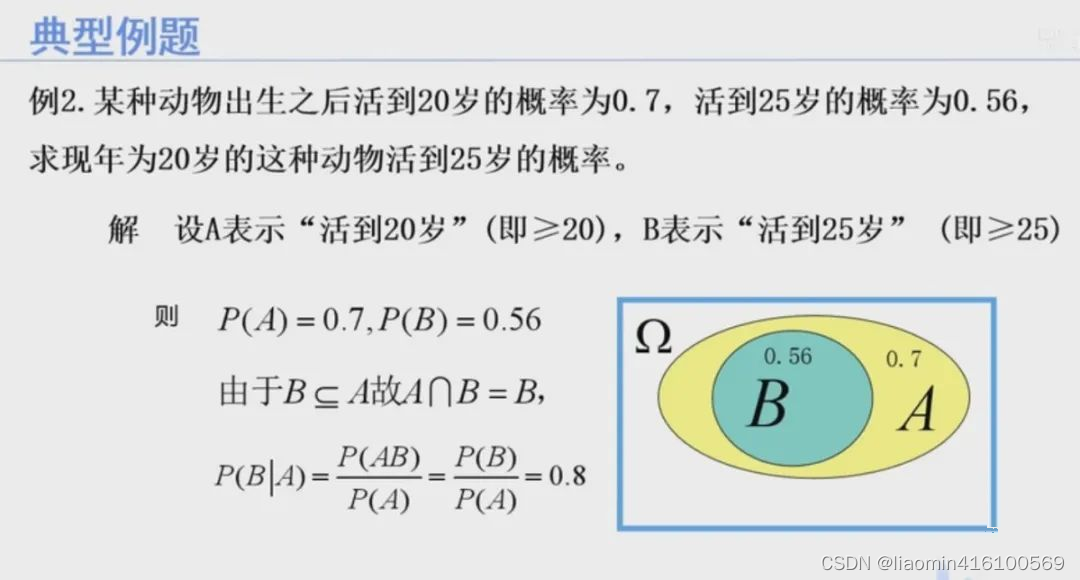
例2.某种动物出生之后活到20岁的概率为0.7,活到25岁的概率为0.56求现年为20岁的这种动物活到25岁的概率。
全概率公式
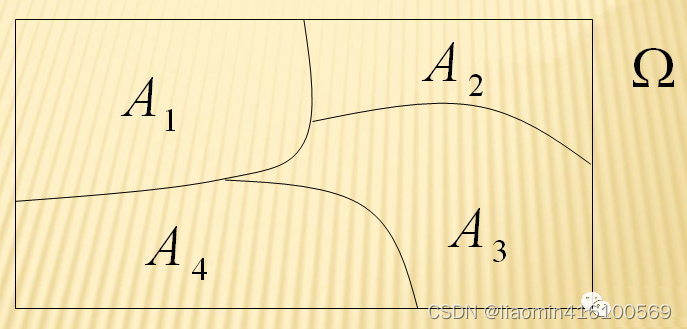
首先要理解什么是“样本空间的划分”【又称“完备事件群”。】
我们将满足(假定样本空间Ω,是两个事件A与A’的和)
- A1,A2,…,An是一组两两互斥的事件
- A1 U A2 U,…,An=Ω
这样的一组事件称为一个“完备事件群”。简而言之,就是事件之间两两互斥,所有事件的并集是整个样本空间(必然事件)。
B在整个Ω中发生的概率是:

公式推导
假定样本空间S,是两个事件A与A’的和。
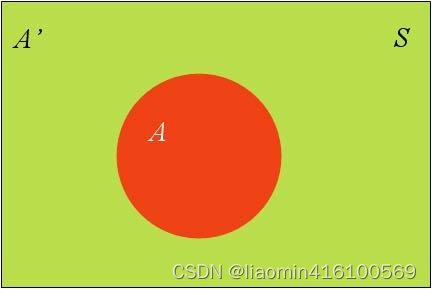
上图中,红色部分是事件A,绿色部分是事件A’,它们共同构成了样本空间S。
在这种情况下,事件B可以划分成两个部分。
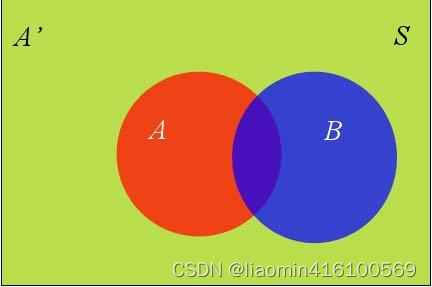
即
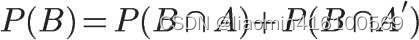
在上一节的推导当中,我们已知
所以,
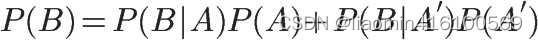
就是全概率公式。它的含义是,如果A和A’构成样本空间的一个划分,那么事件B的概率,就等于A和A’的概率分别乘以B对这两个事件的条件概率之和。
计算案例
例1:有一批同一型号的产品,已知其中由一厂生产的占30%,二厂生产的占50%,三厂生产的占20%,又知这三个厂的产品次品率分别为2%,1%,1%,问从这批产品中任取一件是次品的概率是多少?

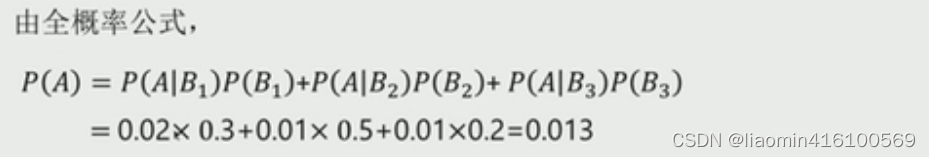
例2:有某电子设备制造厂所用的元件是由三家元件制造厂提供的。根据以往的记录,有以下的数据:
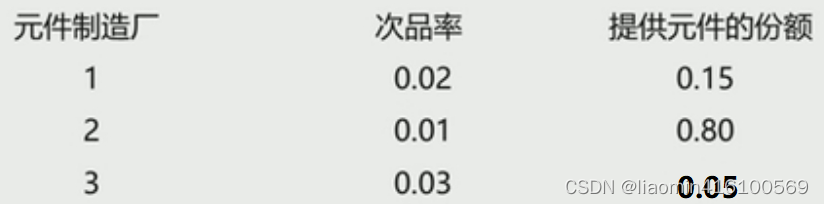
设这三家工厂的产品在仓库中是均匀混合的,且无区别的标志。
- 在仓库中随机地取一只元件,求它是次品的概率;
- 在仓库中随机地取一只元件,若已知取到的是次品,分析此次品出自何厂,需求出此次品有三家工厂生产的概率分别是多少。试求这些概率。

贝叶斯
贝叶斯决策
假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示:
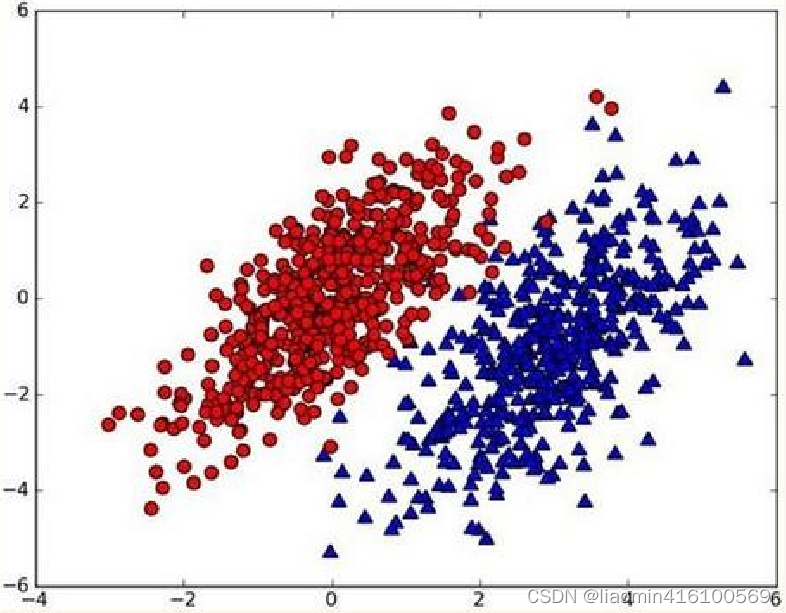
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
- 如果p1(x,y)>p2(x,y),那么类别为1
- 如果p1(x,y)<p2(x,y),那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。已经了解了贝叶斯决策理论的核心思想,贝叶斯的实现就是如何计算p1和p2概率。
贝叶斯推导
对条件概率公式进行变形,可以得到如下形式:
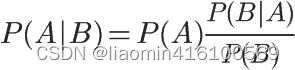
通过全概率公式
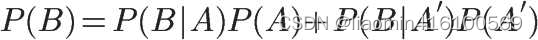
得到条件概率的另外一种变形
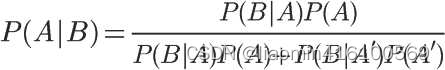
在条件概率
我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:
后验概率 = 先验概率 x 调整因子
这就是贝叶斯推断的含义。我们先预估一个"先验概率",然后加入实验结果,看这个实验到底是增强还是削弱了"先验概率",由此得到更接近事实的"后验概率"。
在这里,如果"可能性函数"P(B|A)/P(B)>1,意味着"先验概率"被增强,事件A的发生的可能性变大;如果"可能性函数"=1,意味着B事件无助于判断事件A的可能性;如果"可能性函数"<1,意味着"先验概率"被削弱,事件A的可能性变小。
计算案例
为了加深对贝叶斯推断的理解,我们举一个例子。
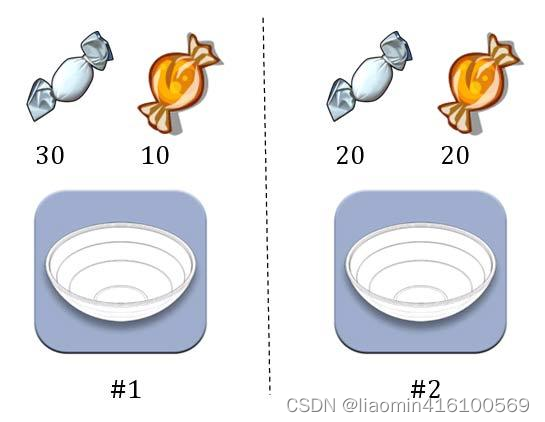
两个一模一样的碗,一号碗有30颗水果糖和10颗巧克力糖,二号碗有水果糖和巧克力糖各20颗。现在随机选择一个碗,从中摸出一颗糖,发现是水果糖。请问这颗水果糖来自一号碗的概率有多大?
我们假定,H1表示一号碗,H2表示二号碗。由于这两个碗是一样的,所以P(H1)=P(H2),也就是说,在取出水果糖之前,这两个碗被选中的概率相同。因此,P(H1)=0.5,我们把这个概率就叫做"先验概率",即没有做实验之前,来自一号碗的概率是0.5。
再假定,E表示水果糖,所以问题就变成了在已知E的情况下,来自一号碗的概率有多大,即求P(H1|E)。我们把这个概率叫做"后验概率",即在E事件发生之后,对P(H1)的修正。
根据条件概率公式,得到
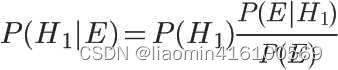
已知,P(H1)等于0.5,P(E|H1)为一号碗中取出水果糖的概率,等于30÷(30+10)=0.75,那么求出P(E)就可以得到答案。根据全概率公式,
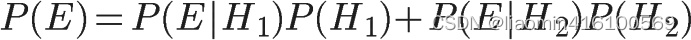
所以,
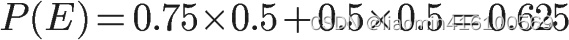
将数字代入原方程,得到
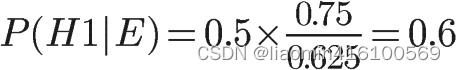
这表明,来自一号碗的概率是0.6。也就是说,取出水果糖之后,H1事件的可能性得到了增强。
同时再思考一个问题,在使用该算法的时候,如果不需要知道具体的类别概率,即上面P(H1|E)=0.6,只需要知道所属类别,即来自一号碗,我们有必要计算P(E)这个全概率吗?要知道我们只需要比较 P(H1|E)和P(H2|E)的大小,找到那个最大的概率就可以。既然如此,两者的分母都是相同的,那我们只需要比较分子即可。即比较P(E|H1)P(H1)和P(E|H2)P(H2)的大小,所以为了减少计算量,全概率公式在实际编程中可以不使用。
对以往数据分析结果表明,当机器调整得良好时,产品的合格率为90%,而当机器发生某一故障时,其合格率为30%。每天早上机器开动时,机器调整良好的概率为75%,试求已知某日早上第一件产品是合格品时,机器调整良好的概率是多少?

某地区居民的肝癌发病率为0.0004,现用甲胎蛋白法进行普查。医学研究表明,化验结果是有错检的可能的。已知患有肝癌的人其化验结果99%呈阳性(有病),而没患肝癌的人其化验结果99.9%呈阴性(无病) 现某人的检查结果呈阳性,问他真的患有肝癌的概率是多少?。

朴素贝叶斯
朴素贝叶斯是一种简单但极为强大的预测建模算法,之所以称为朴素贝叶斯,是因为他假设的每个特征都是独立的。
如果有多个特征条件下预测某个分类,因为假设是每个特征都是独立的所以可以分解为单个特征下分类的概率计算的结果。
比如,收到了一份垃圾邮件,
- 是房地产的概率,
- 是贷款的概率
- 是房地产和贷款的概率

简化为:

朴素贝叶斯模型由两种类型的概率组成
1、每个类别的概率P(CJ)
2、每个属性的条件概率P(AI|CJ)
公式推导
根据贝叶斯公式(假设特征X(多个X1,X2…Xn),对应的分类结果Y)
P(Y|X)=P(Y) * (P(X|Y) / P(X))
因为特征X是多维
P(Y|X)=P(Y) * (P((X1,X2,…Xn)|Y) / P(X1,X2,…Xn))
独立性拆分
P(Y|(X1,X2…Xn))=P(Y) * (P(X1|Y)P(X2|Y)…P(Xn|Y) / P(X1)P(X2)…P(Xn))
假设 某个分类的结果Y=男|女,X特征表示(身高,体重)
此时如果给出某个人的X特征要判断到底是男和女,实际上就是比较
给出的具体身高和体重对应是男和女的概率谁大 即可
由于公式
P(Y|(X1,X2…Xn))=P(Y) * (P(X1|Y)P(X2|Y)…P(Xn|Y) / P(X1)P(X2)…P(Xn))
男或者女情况下 P(Y) 【男和女的概率预测的就是0.5和0.5】 和 P(X1)P(X2)…P(Xn))都是相同的,实际上就只需要比较
P(X1|Y)P(X2|Y)…P(Xn|Y)
的概率大小即可,谁大就是谁的分类结果。
计算案例
离散数据如下:
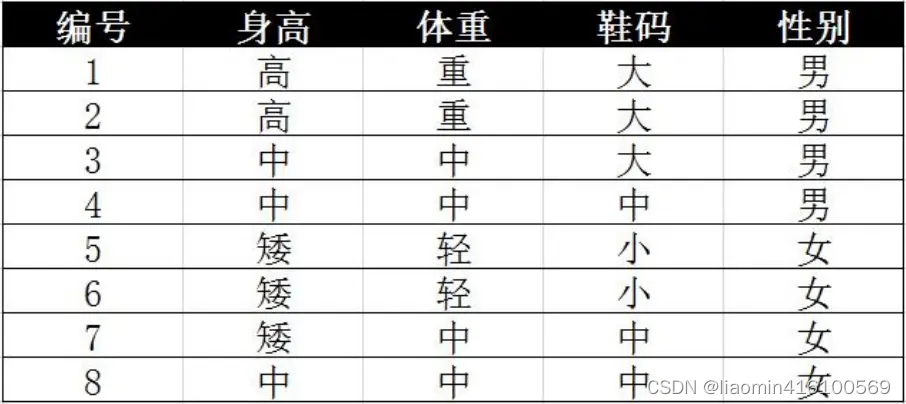
计算:身高为高,体重为中,鞋码为中这个人是男还是女?
X1:表示身高
X2:表示体重
X3:表示鞋码
Y:代表类别 Y1表示男,Y2表示女。未知表示Yj
P(Yj|X1,X2,X3) = P(Yj) * (P(X1|Yj)P(X2|Yj)…P(Xn|Yj) / P(X1)P(X2)…P(Xn))
由于先验概率和分母两个分类都相同,只比较分子
P(X1X2X3|Yj) = P(X1|Yj)P(X2|Yj)…P(Xn|Yj)
假设类别为j=1 Y1是男
P(X1|Y1) = 2/4 就是男生(1-4行)中身高是高(1-2行)的概率
P(X2|Y1) = 2/4
P(X3|Y1) = 1/4
P(X1|Y1)P(X2|Y1) P(X3|Y1) = 2/4*2/4*1/4 = 1/16
假设类别为j=2 Y1是女
P(X1|Y2) = 0 就是女生(5-8行)中身高是高(没有)的概率
P(X2|Y2) = 2/4
P(X3|Y2) = 2/4
P(X1|Y2) P(X2|Y2)P(X3|Y2)) = 0*2/4*2/4 = 0
C1>C2
由此推论:身高为高,体重为中,鞋码为中这个人是男
该案例中由于给定的身高都是确定的数据,判断起来比较简单,如果是连续性数据
1、离散型:有些随机变量它全部可能取到的不相同的值是有限个或可列无限多个,也可以说概率1以一定的规律分布在各个可能值上。
2、连续型:随机变量X的取值不可以逐个列举,只可取数轴某一区间内的任一点。
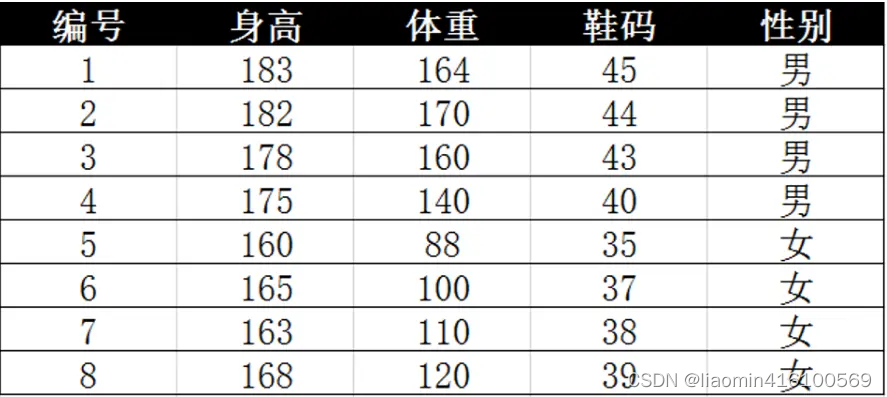
需求:身高180,体重120,鞋码41该人是男还是女?
公式还是上面的公式,但身高,体重,鞋码是连续变量,不能采用离散型方法计算概率。假设身高,体重,鞋码是正态分布通过样本计算出均值和方差,也就得到了正态分布的密度函数,有了密度函数,可以算出一点的密度涵数值。如男性平均身高179.5,标准差3.697正态分布,高180的概率是0.1069
python实现
#%%
import numpy as np
import pandas as pd
df = pd.read_excel('连续性.xlsx',sheet_name="Sheet1",index_col=0)
# 计算男女在每个特征维度的方差和均值
df2 = df.groupby("性别").agg([np.mean, np.var])
print(df2)
#%%
male_high_mean = df2.loc["男","身高"]["mean"]
male_high_var = df2.loc["男","身高"]["var"]
male_weight_mean = df2.loc["男","体重"]["mean"]
male_weight_var = df2.loc["男","体重"]["var"]
male_code_mean = df2.loc["男","鞋码"]["mean"]
male_code_var = df2.loc["男","鞋码"]["var"]
from scipy import stats
# pdf ——概率密度函数标准形式是,算出在男性中身高180的概率
male_high = stats.norm.pdf(180,male_high_mean,male_high_var)
# 算出在男性中体重120的概率
male_weight = stats.norm.pdf(120, male_weight_mean, male_weight_var)
# 算出在男性中鞋码41的概率
male_code = stats.norm.pdf(41, male_code_mean, male_code_var)
fz=(male_high*male_weight*male_code)
print(fz)
female_high_mean = df2.loc["女","身高"]["mean"]
female_high_var = df2.loc["女","身高"]["var"]
female_weight_mean = df2.loc["女","体重"]["mean"]
female_weight_var = df2.loc["女","体重"]["var"]
female_code_mean = df2.loc["女","鞋码"]["mean"]
female_code_var = df2.loc["女","鞋码"]["var"]
#计算在女性分类中的三种特征的概率
female_high = stats.norm.pdf(180, female_high_mean, female_high_var)
female_weight = stats.norm.pdf(120, female_weight_mean, female_weight_var)
female_code = stats.norm.pdf(41, female_code_mean, female_code_var)
ffz=female_high*female_weight*female_code
print(ffz)
if fz>ffz:
print("男性")
else :
print("女性")
三 实践言论过滤器
TF-IDF特征向量
TF-IDF原理
F-IDF特征向量是一种将文本数据转换为数值型表示的方式,其中每个维度代表一个单词,每个样本(也即一个文本)都被表示为一个向量。
TF-IDF是一种用于信息检索与文本挖掘的常用加权技术
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用于信息检索与文本数据分析的算法,用于衡量一个词语对于一个文档或一个文本集合中的其中一份文本的重要程度。
TF(Term Frequency)指的是词频,代表该词在某个文本中出现的次数。IDF(Inverse Document Frequency)指的是逆文档频率,用于衡量该词在整个文本集合中出现的频率,即该词在多少份文本中出现过。如果一个词在文本集合中越常见,它的逆文档频率就越低,说明该词对于区分不同文本的重要性就越小。
因此,TF-IDF值是通过将词频(TF)与逆文档频率(IDF)相乘得到的。对于单个文本而言,TF-IDF值越高,则代表该词对于该文本的重要性越大,越能够代表该文本所表示的主题;而在整个文本集合中,TF-IDF值越高,则代表该词能够很好地区分不同的文本,越能够代表该文本集合所表示的主题。
TF-IDF算法在信息检索、文本分类、关键词提取等领域有着广泛的应用
假设有以下两个文本:
- The quick brown fox jumps over the lazy dog.
- The brown fox is quick and the blue dog is lazy.
首先,需要将这些文本进行预处理,包括去除标点符号、停用词(the ,is and)等,并将每个文本转换为词语列表。针对这两个文本,可能得到以下词语列表:
['quick', 'brown', 'fox', 'jumps', 'lazy', 'dog']
['brown', 'fox', 'quick', 'blue', 'dog', 'lazy']
接下来,需要计算每个词语在每个样本中出现的次数,即词频(TF, term frequency)。这个过程可以使用CountVectorizer类实现。以第一个样本为例,其词频向量为:
[1, 1, 1, 1, 1, 1]
即’quick’、‘brown’、‘fox’、‘jumps’、‘lazy’、'dog’在第一个样本中均出现了1次。
接着,需要计算逆文档频率(IDF, inverse document frequency),用于衡量每个词语的重要性。IDF的计算公式为:
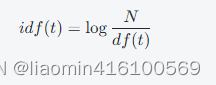
其中,N表示文档总数,这里就是2个文本,df(t)表示包含词语t的文档数量。将以上面两个文本为例进行计算,得到各个词语的IDF值:
[0.0, 0.0, 0.0, 0.6931471805599453, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.6931471805599453, 0.0, 0.0]
其中,‘jumps’在第一个样本中只出现了1次,在所有文档中也只出现了1次,因此其IDF值为
log(2/1)=0.6931。而’quick’、‘brown’、‘fox’、‘lazy’、'dog’在两个文档中都出现了,因此它们的IDF值为0。
最后,需要将每个文本的TF向量与对应的IDF向量相乘,得到TF-IDF特征向量。以第一个文本为例,其TF-IDF向量为:
[0.0, 0.0, 0.0, 0.6931471805599453, 0.0, 0.0]
是因为’jumps’在第一个文本中出现了1次,而且在所有文档中也只出现了1次,因此其TF-IDF值为
1*log(2/1)其他词语的TF-IDF值均为0。
以此类推,可以得到所有文本的TF-IDF特征向量。需要注意的是,每个文本的特征向量维度通常是一样的,因此在计算TF-IDF时需要遍历所有文本。
TfidfVectorizer和CountVectorizer区别
TfidfVectorizer计算的是词语在文本中的重要程度,即TF-IDF值。
CountVectorizer只计算词语在文本中出现的次数。
以下是使用实际数据来说明 TfidfVectorizer 和 CountVectorizer 的区别:
假设我们有以下三篇文档:
- 文档A:天气晴朗,温度适宜,阳光明媚。
- 文档B:天气多云,温度适宜,偶有小雨。
- 文档C:天气阴天,温度偏低,有雨。
我们可以使用 TfidfVectorizer 和 CountVectorizer 对这三篇文档进行特征向量化,得到它们的词频矩阵。
具体来说,使用 CountVectorizer 可以得到以下的词频矩阵:
| 词汇 | 文档A | 文档B | 文档C |
|---|---|---|---|
| 天气 | 1 | 1 | 1 |
| 温度 | 1 | 1 | 1 |
| 适宜 | 1 | 1 | 0 |
| 阳光明媚 | 1 | 0 | 0 |
| 多云 | 0 | 1 | 0 |
| 偶有小雨 | 0 | 1 | 0 |
| 阴天 | 0 | 0 | 1 |
| 偏低 | 0 | 0 | 1 |
| 有雨 | 0 | 0 | 1 |
而使用 TfidfVectorizer 可以得到以下的词频矩阵:
| 词汇 | 文档A | 文档B | 文档C |
|---|---|---|---|
| 天气 | 0.00 | 0.00 | 0.58 |
| 温度 | 0.42 | 0.42 | 0.42 |
| 适宜 | 0.58 | 0.58 | 0.00 |
| 阳光明媚 | 0.81 | 0.00 | 0.00 |
| 多云 | 0.00 | 0.81 | 0.00 |
| 偶有小雨 | 0.00 | 0.81 | 0.00 |
| 阴天 | 0.00 | 0.00 | 0.58 |
| 偏低 | 0.00 | 0.00 | 0.81 |
| 有雨 | 0.00 | 0.00 | 0.58 |
从上面的词频矩阵可以看出,CountVectorizer 只考虑了每种词汇在当前文档中出现的频率,而 TfidfVectorizer 则同时考虑了某一词汇在当前训练文本中出现的频率以及包含这个词汇的其它训练文本数目的倒数,因此 TfidfVectorizer 更能够反映出不同文档之间的差异性。
TfidfVectorizer和CountVectorizer实例
CountVectorizer统计词频
#%%
postingList=['my my dog has flea problems help please', #切分的词条
'maybe not take him to dog park stupid',
'my dalmation is so cute I love him',
'stop posting stupid worthless garbage',
'mr licks ate my steak how to stop him',
'quit buying worthless dog food stupid']
classVec = [0,1,0,1,0,1] #类别标签向量,1代表侮辱性词汇,0代表不是
from sklearn.feature_extraction.text import CountVectorizer
# 初始化CountVectorizer并进行文本特征提取
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(postingList)
# 显示特征向量和对应的单词
print(X.toarray())
print(vectorizer.get_feature_names())
输出
[[0 0 0 0 1 1 0 0 1 1 0 0 0 0 0 0 0 2 0 0 1 0 1 0 0 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 0 0 1 1 0 0 0 0 0 0 0 1 1 1 0]
[0 0 1 1 0 0 0 0 0 0 1 0 1 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 1]
[1 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 1 1 0 0 0 0 0 0 0 1 1 0 0 1 0]
[0 1 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 1]]
['ate', 'buying', 'cute', 'dalmation', 'dog', 'flea', 'food', 'garbage', 'has', 'help', 'him', 'how', 'is', 'licks', 'love', 'maybe', 'mr', 'my', 'not', 'park', 'please', 'posting', 'problems', 'quit', 'so', 'steak', 'stop', 'stupid', 'take', 'to', 'worthless']
12
注意,是将所有的单词去重复后作为特征列,数据行就是当前的文档,行中的数据就是在这个特征单词上出现的次数
TfidfVectorizer统计tf-idf
#%%
from sklearn.feature_extraction.text import TfidfVectorizer
# 初始化TfidfVectorizer
tvectorizer = TfidfVectorizer(stop_words='english')
# 转换文本数据到词袋模型
X_train = tvectorizer.fit_transform(postingList)
# 显示特征向量和对应的单词
print(X_train.toarray())
print(vectorizer.get_feature_names())
输出
[[0. 0. 0. 0. 0.37115593 0.53611046
0. 0. 0.53611046 0. 0. 0.
0. 0. 0. 0.53611046 0. 0.
0. 0. 0. ]
[0. 0. 0. 0. 0.40249409 0.
0. 0. 0. 0. 0. 0.58137639
0. 0.58137639 0. 0. 0. 0.
0. 0.40249409 0. ]
[0. 0. 0.57735027 0.57735027 0. 0.
0. 0. 0. 0. 0.57735027 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0.51136725 0. 0. 0. 0.
0. 0. 0.51136725 0. 0. 0.
0.41932846 0.3540259 0.41932846]
[0.46262479 0. 0. 0. 0. 0.
0. 0. 0. 0.46262479 0. 0.
0.46262479 0. 0. 0. 0. 0.46262479
0.37935895 0. 0. ]
[0. 0.46468841 0. 0. 0.32170956 0.
0.46468841 0. 0. 0. 0. 0.
0. 0. 0. 0. 0.46468841 0.
0. 0.32170956 0.38105114]]
['ate', 'buying', 'cute', 'dalmation', 'dog', 'flea', 'food', 'garbage', 'has', 'help', 'him', 'how', 'is', 'licks', 'love', 'maybe', 'mr', 'my', 'not', 'park', 'please', 'posting', 'problems', 'quit', 'so', 'steak', 'stop', 'stupid', 'take', 'to', 'worthless']
训练朴素贝叶斯分类器
我们先得到词条向量
import numpy as np
postingList=['my dog has flea problems help please', #切分的词条
'maybe not take him to dog park stupid',
'my dalmation is so cute I love him',
'stop posting stupid worthless garbage',
'mr licks ate my steak how to stop him',
'quit buying worthless dog food stupid']
classVec = np.array([0,1,0,1,0,1])
from sklearn.feature_extraction.text import CountVectorizer
# 初始化CountVectorizer并进行文本特征提取
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(postingList)
# 显示特征向量和对应的单词
v=np.array(X.toarray())
print(v)
fn=np.array(vectorizer.get_feature_names())
print(fn)
输出
[[0 0 0 0 1 1 0 0 1 1 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 0 0 1 1 0 0 0 0 0 0 0 1 1 1 0]
[0 0 1 1 0 0 0 0 0 0 1 0 1 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 1]
[1 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 1 1 0 0 0 0 0 0 0 1 1 0 0 1 0]
[0 1 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 1]]
['ate' 'buying' 'cute' 'dalmation' 'dog' 'flea' 'food' 'garbage' 'has'
'help' 'him' 'how' 'is' 'licks' 'love' 'maybe' 'mr' 'my' 'not' 'park'
'please' 'posting' 'problems' 'quit' 'so' 'steak' 'stop' 'stupid' 'take'
'to' 'worthless']
接下来,我们就可以通过词条向量训练朴素贝叶斯分类器。
"""
通过传入单词向量和分类结果训练数据集获取到每个特征在不同分类下的条件概率,以及对应分类的先验概率。
利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,
即计算p(w0|1)p(w1|1)p(w2|1)。
如果其中有一个概率值为0,那么最后相乘的结果也为0
这样是不合理的,为了降低这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。这种做法就叫做拉普拉斯平滑(Laplace Smoothing)又被称为加1平滑,
是比较常用的平滑方法,它就是为了解决0概率问题,具体参考拉普拉斯平滑目录。
"""
def trainData(vecList,classVec):
#获取先验概率P(侮辱类), P(非侮辱类)=1-P(侮辱类)
PϹ侮辱类先验Ͻ=np.sum(classVec)/len(classVec)
#找到所有classVec==0非侮辱类索引行并取得数据行。
vec0=vecList[np.where(classVec==0)]
#找到所有classVec==1侮辱类索引行并取得数据行。
vec1=vecList[np.where(classVec==1)]
#设置拉普拉斯平滑因子为1: ,分类的种类是2中所有分子+1,分母+2
a=1
#让分子都加上1
vec0=np.add(vec0,a)
vec1=np.add(vec1,a)
#计算每个特征在对应分类下的条件概率,分母加上2
PϹ特征l非侮辱类Ͻ=np.sum(vec0,axis=0)/(np.sum(vec0)+a*2)
PϹ特征l侮辱类Ͻ=np.sum(vec1,axis=0)/(np.sum(vec1)+a*2)
return PϹ特征l侮辱类Ͻ,PϹ特征l非侮辱类Ͻ,PϹ侮辱类先验Ͻ
PϹ特征l侮辱类Ͻ,PϹ特征l非侮辱类Ͻ,PϹ侮辱类先验Ͻ=(trainData(v,classVec))
print(PϹ特征l非侮辱类Ͻ,PϹ特征l侮辱类Ͻ,PϹ侮辱类先验Ͻ)
输出:
[0.03389831 0.02542373 0.03389831 0.03389831 0.03389831 0.03389831
0.02542373 0.02542373 0.03389831 0.03389831 0.04237288 0.03389831
0.03389831 0.03389831 0.03389831 0.02542373 0.03389831 0.05084746
0.02542373 0.02542373 0.03389831 0.02542373 0.03389831 0.02542373
0.03389831 0.03389831 0.03389831 0.02542373 0.02542373 0.03389831
0.02542373]
[0.02631579 0.03508772 0.02631579 0.02631579 0.04385965 0.02631579
0.03508772 0.03508772 0.02631579 0.02631579 0.03508772 0.02631579
0.02631579 0.02631579 0.02631579 0.03508772 0.02631579 0.02631579
0.03508772 0.03508772 0.02631579 0.03508772 0.02631579 0.03508772
0.02631579 0.02631579 0.03508772 0.05263158 0.03508772 0.03508772
0.04385965]
0.5
拉普拉斯平滑概念和例子参考:https://github.com/lzeqian/machinelearntry/tree/master/sklearn_bayes/%E6%8B%89%E6%99%AE%E6%8B%89%E6%96%AF%E5%B9%B3%E6%BB%91
- P(特征l非侮辱类) 是非侮辱类下某个特征的概率,也就是P(非侮辱类)条件概率的分子,其中第五个特征是dog,也就是P(dog|非侮辱类) 概率是0.03389831 。
- P(特征l侮辱类) 是侮辱类下某个特征的概率,也就是P(非侮辱类)条件概率的分子,其中第五个特征是dog,也就是P(dog|侮辱类) 概率是0.04385965 。
- P(侮辱类先验)就是侮辱类的先验概率。
使用训练数据分类
获取到P(特征l非侮辱类) , P(特征l侮辱类) 和P(侮辱类先验),P(非侮辱类先验)=1-P(侮辱类先验),后就可以使用这些数据和传入的新词汇来判断归属的分类了。
'''
注意求条件概率是找到对应的单词下在对应的分类的乘积,比如
you are a dog as b
0.001 0.0005 0.03 0.666 0.3 0.99
传入的矩阵就是
1 1 1 1 0 0
实际条件侮辱类概率就是
P(you|侮辱类)*P(are|侮辱类)*P(a|侮辱类)*P(dog|侮辱类)
乘积小数位太多就可能导致小数位溢出,需要使用两个乘数的log来防止溢出
log(P(you|侮辱类)*P(are|侮辱类)*P(a|侮辱类)*P(dog|侮辱类))=log(P(you|侮辱类))+log(P(are|侮辱类))+log(P(a|侮辱类))+log(P(dog|侮辱类))
为了通过计算直接获取到对应的这些特征单词的和,可以先求出所有特征的log值和传入的矩阵乘积在求和就是上面的结果
'''
def classResult(wordVec,PϹ特征l侮辱类Ͻ,PϹ特征l非侮辱类Ͻ,PϹ侮辱类先验Ͻ):
PϹ侮辱类Ͻ=np.sum(np.log(PϹ特征l侮辱类Ͻ)*wordVec)+np.log(PϹ侮辱类先验Ͻ)
PϹ非侮辱类Ͻ=np.sum(np.log(PϹ特征l非侮辱类Ͻ)*wordVec)+np.log(1-PϹ侮辱类先验Ͻ)
return 1 if PϹ侮辱类Ͻ>PϹ非侮辱类Ͻ else 0
#测试的词汇
text=["you are a dog"]
testX = vectorizer.transform(text)
testV=np.array(testX.toarray())
print(classResult(testV,PϹ特征l侮辱类Ͻ,PϹ特征l非侮辱类Ͻ,PϹ侮辱类先验Ͻ))
注意多个小数相乘,使用log函数防止小数位溢出理论参考:https://github.com/lzeqian/machinelearntry/blob/master/sklearn_bayes/%E4%B8%8B%E6%BA%A2%E5%87%BA/%E4%B9%98%E7%A7%AF%E7%BB%93%E6%9E%9C%E5%8F%96%E8%87%AA%E7%84%B6%E5%AF%B9%E6%95%B0%E9%98%B2%E6%AD%A2%E4%B8%8B%E6%BA%A2%E5%87%BA.png
四 朴素贝叶斯之数据归类(sklearn)
朴素贝叶斯分类器是对于特征维数较小而训练样本数比较多的分类问题而使用的分类器,其假设所有特征在类别已知的条件下相互独立。在构建分类器时,只需要逐个估计出每个类别的训练样本在每一维特征上的分布,就可以得到每个类别的条件概率密度,大大减少了需要估计参数的数量。也就是说,在给定样本的目标特征值的情况下观察到特征x1,x2,…,xn的联合概率等于每个单独的特征的概率的乘积。
scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。
- GaussianNB就是先验为高斯分布的朴素贝叶斯,
- MultinomialNB就是先验为多项式分布的朴素贝叶斯,
- BernoulliNB就是先验为伯努利分布的朴素贝叶斯。
如果样本特征的分布大部分是连续值,使用GaussianNB会比较好。
如果如果样本特征的分大部分是多元离散值,使用MultinomialNB比较合适。
如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB。
前面讲解的先验概率模型就是先验概率为多项式分布的朴素贝叶斯。
对于新闻分类,属于多分类问题。我们可以使用MultinamialNB()完成我们的新闻分类问题。另外两个函数的使用暂且不再进行扩展,可以自行学习。MultinomialNB假设特征的先验概率为多项式分布,即如下式:
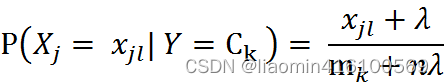
其中, P(Xj = Xjl | Y = Ck)是第k个类别的第j维特征的第l个取值条件概率。mk是训练集中输出为第k类的样本个数。λ为一个大于0的常数,常常取值为1,即拉普拉斯平滑,也可以取其他值。
接下来,我们看下MultinamialNB这个函数,只有3个参数:

参数说明如下:
- alpha:浮点型可选参数,默认为1.0,其实就是添加拉普拉斯平滑,即为上述公式中的λ ,如果这个参数设置为0,就是不添加平滑;
- fit_prior:布尔型可选参数,默认为True。布尔参数fit_prior表示是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率。否则可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior让MultinomialNB自己从训练集样本来计算先验概率,此时的先验概率为P(Y=Ck)=mk/m。其中m为训练集样本总数量,mk为输出为第k类别的训练集样本数。
- class_prior:可选参数,默认为None。
总结如下:

除此之外,MultinamialNB也有一些方法供我们使用:
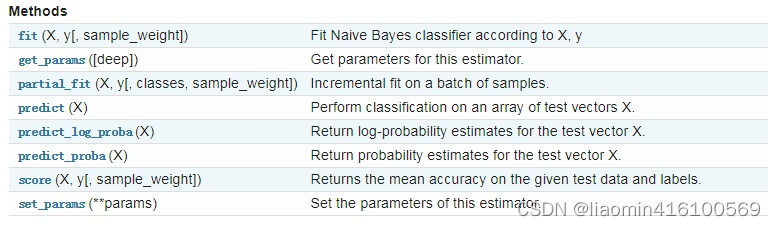
MultinomialNB一个重要的功能是有partial_fit方法,这个方法的一般用在如果训练集数据量非常大,一次不能全部载入内存的时候。这时我们可以把训练集分成若干等分,重复调用partial_fit来一步步的学习训练集,非常方便。GaussianNB和BernoulliNB也有类似的功能。 在使用MultinomialNB的fit方法或者partial_fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。predict方法就是我们最常用的预测方法,直接给出测试集的预测类别输出。predict_proba则不同,它会给出测试集样本在各个类别上预测的概率。容易理解,predict_proba预测出的各个类别概率里的最大值对应的类别,也就是predict方法得到类别。predict_log_proba和predict_proba类似,它会给出测试集样本在各个类别上预测的概率的一个对数转化。转化后predict_log_proba预测出的各个类别对数概率里的最大值对应的类别,也就是predict方法得到类别。具体细节不再讲解,可参照官网手册。
使用skearn分类新浪新闻
数据加载
例子来源于:https://cuijiahua.com/blog/2017/11/ml_5_bayes_2.html
以下是新闻分类的类别
C000008 财经
C000010 IT
C000013 健康
C000014 体育
C000016 旅游
C000020 教育
C000022 招聘
C000023 文化
C000024 军事
文章数据位于每个分类目录下的多篇文章
数据集下载:https://github.com/lzeqian/machinelearntry/tree/master/sklearn_bayes/%E6%96%B0%E9%97%BB%E5%88%86%E7%B1%BB%E6%95%B0%E6%8D%AE
加载数据集(文章中的单词需要单独作为特征,需要分词,这里使用jieba)
分词整理
数据集已经准备好,接下来,让我们直接进入正题。切分中文语句,编写如下代码:
import os
import jieba
'''
判断字符串是否为数字,清理包括:1,1.5,023,34%等特别的数字字符串
'''
def isNumber(num):
if(num.isdigit() or num.isnumeric() or num.isdecimal()):
return True
if num.endswith('%'):
num_str = num[:-1] # 去掉百分号
return isNumber(num_str)
try:
_ = float(num)
return True
except ValueError:
return False
return False
'''
将某个字符串通过jieba分词后通过空格拼接,因为CountVectorizer统计词频传入的是带空格的字符串
'''
def wordToVec(word):
word_cut = jieba.cut(word, cut_all = False)
filtered_words = filter(lambda w: w is not None and len(w.strip()) > 0 and not isNumber(w.strip()), list(word_cut)) # 过滤掉空字符串
word_list=" ".join(filtered_words)
return word_list
'''
读取新闻分类数据/Sample目录下的所有数据
'''
def TextProcessing(folder_path):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #训练集
class_list = []
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_list=wordToVec(raw)
data_list.append(word_list)
class_list.append(folder)
j += 1
print("词条行:",data_list)
print("分类:",class_list)
return data_list,class_list
使用CountVectorizer向量化,并且打印出现次数最多的此的前50
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
if __name__ == '__main__':
#文本预处理
folder_path = './新闻分类数据/Sample' #训练集存放地址
data_list1,class_list1=TextProcessing(folder_path)
stop_words="";
with open(os.path.join("./新闻分类数据", "stopwords_cn.txt"), 'r', encoding = 'utf-8') as f: #打开txt文件
stop_words = f.read()
stop_words_array=stop_words.split("\n")
#除了停止词外,单个字母的都会被自动过滤掉
vectorizer = CountVectorizer(stop_words=stop_words_array)
X = vectorizer.fit_transform(data_list1)
fn=np.array(vectorizer.get_feature_names())
print("特征列:",fn)
v=np.array(X.toarray())
print("词条向量:\n",v)
top=50
wordcount=v.sum(axis=0)[0:top]
print("获取单词出现次数:",wordcount)
print("排序索引:",np.argsort(wordcount)[::-1])
print("排序特征:",fn[np.argsort(wordcount)[::-1]])
print("排序词频:",wordcount[np.argsort(wordcount)[::-1]])
输出:
特征列: ['04vs' '110min' '125min' ... '龙岗' '龙江' '龙珠']
词条向量:
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
获取单词出现次数: [ 1 1 1 1 1 1 2 1 1 1 1 1 3 2 1 2 6 6 5 1 1 1 1 1
3 1 1 1 1 2 4 2 1 1 1 7 2 1 1 1 2 1 1 1 1 1 1 1
10 5]
排序索引: [48 35 16 17 49 18 30 12 24 40 6 15 13 31 29 36 4 5 3 7 44 8 9 10
11 47 2 14 1 46 45 20 19 39 38 37 41 34 33 32 42 28 27 26 25 43 23 22
21 0]
排序特征: ['ceo' 'bbc' 'ak' 'an' 'cfo' 'and' 'ax' 'ac' 'armed' 'bittorrent' '3g'
'ah' 'academic' 'a股' 'aw' 'bbn' '3d' '3dmax' '16i' '5140i' 'brings'
'80mb' '95min' 'ab' 'abc' 'cbs' '125min' 'adj' '110min' 'career'
'brothers' 'anti' 'answer' 'bennett' 'begins' 'be' 'bjeea' 'band' 'b09'
'b06' 'bot' 'availwidth' 'availheight' 'assessment' 'army' 'bravo' 'area'
'are' 'applications' '04vs']
排序词频: [10 7 6 6 5 5 4 3 3 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1]
将数据拆分成训练集和测试集(注意数据集要先打乱,因为现在的数据集都是通过分类读取的,就是按分配来排序的,可能抽取的20%的数据集把某个分类下的所有数据都抽走了,就导致这个分类下没有训练,导致准确性不高)
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
X, y = shuffle(v, class_list1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
测试下 该训练器的准确率
classifier = MultinomialNB().fit(X_train, y_train)
test_accuracy = classifier.score(X_test, y_test)
print(test_accuracy)
输出:0.7222222222222222
随便输入一个某个字符串预测下
v1=vectorizer.transform([wordToVec("身体是革命的本钱")]).toarray();
print(classifier.predict(v1))
输出:[‘C000020’] 也就是:教育