近些时间电脑重装,所以顺便做一些环境搭建的笔记,方便以后查阅。
安装anaconda
这里有过记录,跳过。
anaconda 可以创建不同的虚拟环境,安装不同的 python 版本,我这里新建了一个虚拟环境专门用来运行 yolov5 。
配置GPU和pytorch
CUDA (Compute Unified Device Architecture,统一计算设备架构),是显卡厂商NVIDIA在2007年推出的并行计算平台和编程模型。
Pytorch 是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。
// 这里插个眼,似乎不需要下 CUDA ,下 pytorch 好像是会附带的。
安装 nvidia 驱动
官网:https://www.nvidia.cn/geforce/drivers/ ,进入安装下载。
安装pytorch
查看 CUDA 版本:
命令行输入:nvidia-smi,会有一个CUDA Version,记住它。
进入 官网,选择对应的命令下载,我的版本时 CUDA 11.6 的,所以我用这个。
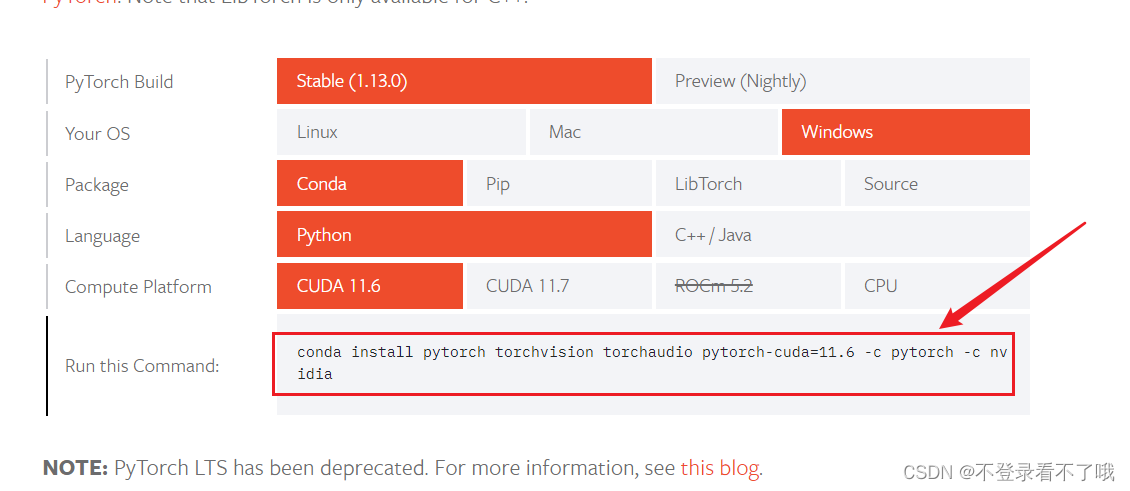
-c pytorch -c nvidia 可以不加,这表示从pytorch和nvidia下载,不加的话,则使用你配置的国内镜像源下载,但我使用国内镜像源出了点问题,而使用国外源下载的速度并不是太慢,因此我就使用官方的命令了。
检验
打开命令行,进入你配置的 python 环境中(默认是base环境)。输入python,会进入python交互模式,在这里是要写 python 代码的,而非 cmd 指令,输入以下代码。
import torch # 导入torch
print(torch.cuda.is_available()) # 检验是否可以使用GPU
print(torch.__version__) #输出torch版本
如果都正常运行并且输出结果是自己想要的话,基本上 pytorch 就安装成功了。
安装依赖包
进入yolov5 目录下,打开命令行,输入pip install -r requirements.txt 安装所需要的模块。
下载预训练权重
预训练模型是在大型基准数据集上训练的模型,用于解决相似的问题。
由于训练这种模型的计算成本较高,因此,导入已发布的成果并使用相应的模型是比较常见的做法。在训练一个目标检测模型时,可以使用这些神经网络的预训练权重来将backbone的参数初始化,这样在一开始就能提取到比较有效的特征,也就是说不是从0开始的。
这样一方面可以提高速度,另一方面可以提高精度。
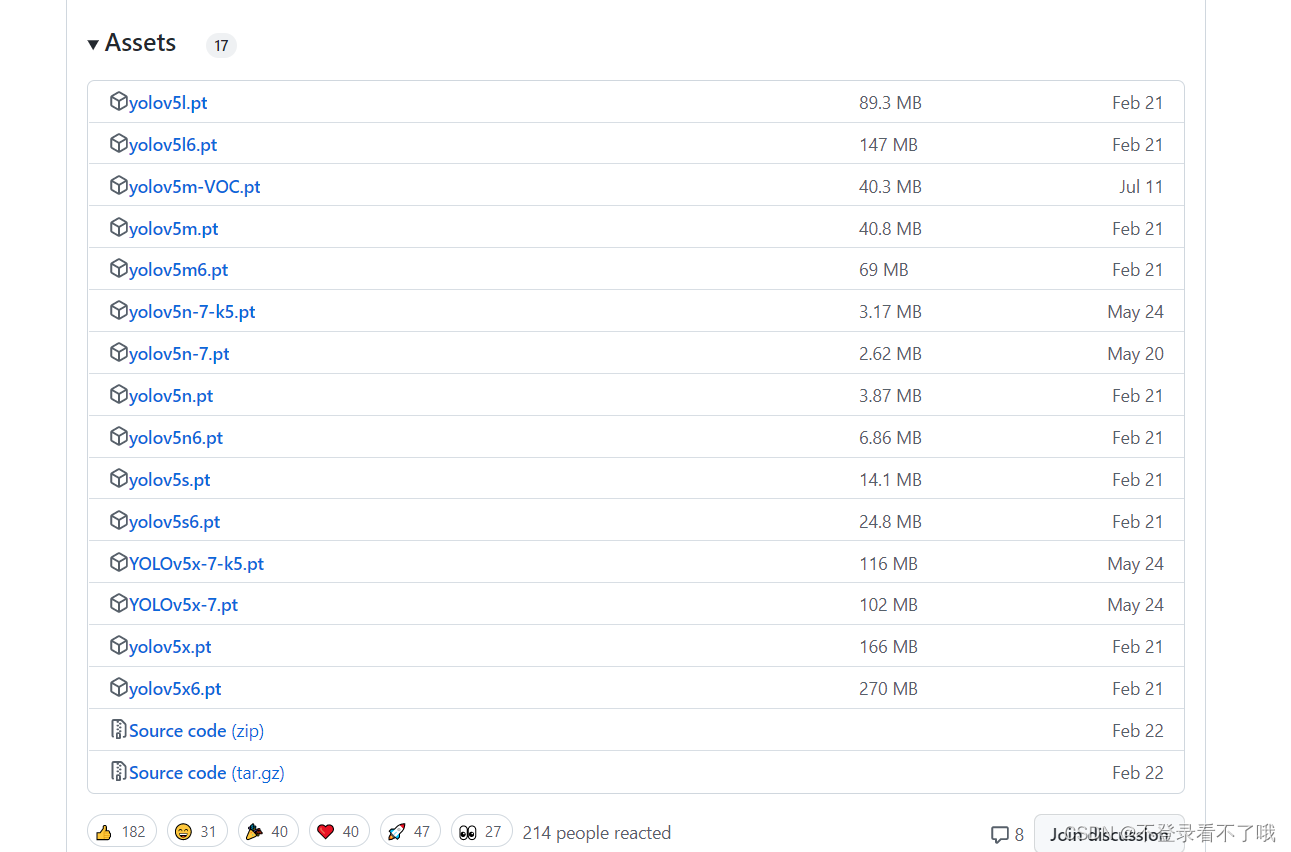
下载地址:https://github.com/ultralytics/yolov5/releases
往下滑,在 Assets 下,下载以 .pt 结尾的文件即可,(不同版本下发布了不同的模型,或许可以根据文件大小判断这些权重的效果)
detect
现在差不多是配置好了,可以运行 detect 检验一下。
打开 detect.py 文件,在大概 200 多行,设置参数。
– weights :训练权重
– source:要预测的图片
– data:数据集配置文件

运行 detect.py 文件,这里会联网下载数据集,等待程序运行结束 …
(你也可以在对应的
.yaml文件中查看下载地址,自行下载,并按照要求分配好文件夹的存放目录。)
终端会显示运行结果保存路径(从 yolov5 作为根目录,开始算起)
比如下面这是我的目录:
Results saved to runs\detect\exp1
默认使用的是 coco128 训练集,里面标注有 80 个类别。
