项目介绍:
Firefly(流萤) 是yangjianxin开发的开源的中文大语言模型项目,本文主要实现将此模型部署到http服务器上,语言实现:python,本项目为双创项目后端部分代码(本人根据firefly训练代码修改+微调的模型暂不方便开源),样例模型改用firefly1b4模型
项目环境:
1.pytorch:2.0.1+cpu
2.transformers:4.29.1
3.httpserver库
例外:requests库(如果不接其他api不需要)
模型下载:YeungNLP (YeungNLP) (huggingface.co)
下载后新建model文件夹将下载的所有文件放入文件夹,如下图所示

打开config.json,将torch_dtype的值改为int8,可以有效降低卡顿(尤其适用于cpu版本)
硬件环境:
由于是模型的使用,除了推理的时候不会很吃Cpu/Gpu,加载模型比较吃内存,目前经过测试发现实际运行,8G可以勉强运行模型,但是有大概率导致整机卡死,建议至少达到12G内存
项目开发环境:Cpu:i58400,内存:16G(此配置下运行模型再跑androidstudio+非androidstudio自带的模拟器也是搓搓有余的)
代码部分:
1.导入包:
print("导入requests库中...")
import requests
print("导入http库中...")
import http.server
print("导入json库中...")
import json
print("导入os库中...")
import os
print("导入time库中...")
import time
print("导入urllib库中...")
import urllib
import random
from urllib import parse
print("导入transformers库中...")
from transformers import BloomTokenizerFast, BloomForCausalLM
print("导包完成=====================")2.RequestHandlerImpl类部分(httpserver)
class RequestHandlerImpl(http.server.BaseHTTPRequestHandler):
def do_GET(self):
get_str=""
get_cmd=self.requestline[5:self.requestline.find("HTTP/1.1")]
self.send_response(200)
self.send_header("Content-Type", "text/html; charset=utf-8")
self.end_headers()
get_str=checkget(get_cmd,self.headers)
if get_str=="":get_str= "Hello World\n"
self.wfile.write(get_str.encode("utf-8"))
def do_POST(self):
req_body = self.rfile.read(int(self.headers["Content-Length"])).decode()
self.send_response(200)
self.send_header("Content-Type", "text/html; charset=utf-8")
self.end_headers()
get_str=checkpost(self.path,req_body)
self.wfile.write(get_str.encode("utf-8"))3.项目函数部分(由于是app后端有接入其他接口):
def get_answer(text):
print("得到新问题",text)
input_ids = tokenizer(text, return_tensors="pt").input_ids
input_ids = input_ids.to(device)
outputs = model.generate(input_ids, max_new_tokens=200, do_sample=True, top_p=0.85, temperature=0.35,repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id)
rets = tokenizer.batch_decode(outputs)
output = rets[0].strip().replace(text, "").replace('</s>', "")
return format(output)
def get_list(parm): #新闻类接口,可以发布
parm=parm[1:]
get_tx=parm.split("&")
name="福州"
page="0"
for i in range(0, len(get_tx)):
if get_tx[i][0:5]=="name=":
name=get_tx[i][5:]
if get_tx[i][0:5]=="page=":
page=get_tx[i][5:].replace(' ', '')
url = "https://v.api.aa1.cn/api/api-tplist/go.php/api/News/local_news?name=" + name + "&page=" + page
print(url)
response = requests.get(url)
content = response.text
return content
def get_top(): #百度热搜接口
url ='https://v.api.aa1.cn/api/topbaidu/index.php'
response = requests.get(url)
content = response.text
return content
def get_weather(): #天气类接口(付费的)
url ='http://apis.juhe.cn/simpleWeather/query?city=%E7%A6%8F%E5%B7%9E&key=需要自己加上'
response = requests.get(url)
content = response.text
return content
def login(up): #登录接口
get_tx=up.split("&")
un=""
pw=""
code=0
for i in range(0, len(get_tx)):
if get_tx[i][0:5]=="user=":
un=get_tx[i][5:]
if get_tx[i][0:5]=="pass=":
pw=get_tx[i][5:].replace(' ', '')
print(un)
print(pw)
f=open('libaray/uw', encoding='gbk') #加载type字符库
for line in f:
get_tx=line.split(",")
if un==get_tx[0] and pw==get_tx[1].replace('\n', ''):
dic = {'code': 200, 'msg': "登录成功","token":token}
break
else:
dic = {'code': 201, 'msg': "用户名或密码错误"}
f.close()
print(dic)
return json.dumps(dic, sort_keys=True,ensure_ascii= False,indent=4, separators=(',', ':'))
def register(up): #登录接口
get_tx=up.split("&")
uw=""
pw=""
code=0
for i in range(0, len(get_tx)): #这里和登录类似,可以封装起来,目的是获取传来的用户,密码
if get_tx[i][0:5]=="user=":
un=get_tx[i][5:]
if get_tx[i][0:5]=="pass=":
pw=get_tx[i][5:].replace(' ', '')
print(un)
print(pw)
#加载uw密码库,后续可以写成load函数,在加载时候开启
f=open('libaray/uw', encoding='gbk')
for line in f:
get_tx=line.split(",")
if un==get_tx[0]:
dic = {'code': 201, 'msg':"用户已存在"}
return json.dumps(dic, sort_keys=True,ensure_ascii= False,indent=4, separators=(',', ':'))
f.close()
f=open('libaray/uw','a+')
f.write(un+","+pw+"\n")
dic = {'code': 200, 'msg':"注册成功"}
f.close()
return json.dumps(dic, sort_keys=True,ensure_ascii= False,indent=4, separators=(',', ':'))
def checkpost(path,get_cmd): #查看post进来的数据
if path=="/login":
return login(get_cmd)
if path=="/register":
return register(get_cmd)
def checkhead(head): #检查需要加密的接口,传进来的头
print(token == head.get("Authorization"))
if token == head.get("Authorization"):
return True
else:
return False
def checkget(get_cmd="",head=""): #查看get进来的数据
if get_cmd[0:9]=="question=":
if checkhead(head):
dic = {'code': 200, 'msg':get_answer(parse.unquote(get_cmd[9:])),"prompt":urllib.parse.unquote(get_cmd[9:])}
return json.dumps(dic, sort_keys=True,ensure_ascii= False,indent=4, separators=(',', ':'))
else:
dic = {'code': 401, 'msg':"没有权限"}
return json.dumps(dic, sort_keys=True,ensure_ascii= False,indent=4, separators=(',', ':'))
if get_cmd[0:4]=="list":
if checkhead(head):
return get_list(get_cmd[4:])
else:
dic = {'code': 401, 'msg':"没有权限"}
return json.dumps(dic, sort_keys=True,ensure_ascii= False,indent=4, separators=(',', ':'))
if get_cmd[0:6]=="gettop":
if checkhead(head):
return get_top()
else:
dic = {'code': 401, 'msg':"没有权限"}
return json.dumps(dic, sort_keys=True,ensure_ascii= False,indent=4, separators=(',', ':'))
if get_cmd[0:7]=="weather": #免费api接口
return get_weather()
if get_cmd[0:6]=="login?":
gcmd=get_cmd[6:]
return login(gcmd)main:
print("加载tokenizer中")
tokenizer = BloomTokenizerFast.from_pretrained('model/') #路径以文件夹下的model为例
print("加载model中")
model = BloomForCausalLM.from_pretrained('model/')
model.eval()
device="cpu"
model = model.to(device) #用cuda或者cpu
print("tlc机器人已启动")
token=''.join(random.sample('abcdefghijklmnopqrstuvwxyzABCDEGHIJKLMNOPQRSTWVUXYZ!@#$%&',39))
print("加密为token=" + token) #这句加入是方便测试
local_ip="10.1.136.73" #local ip为服务器ip
server_address = (local_ip, 19999)
httpd = http.server.HTTPServer(server_address, RequestHandlerImpl)
httpd.serve_forever()
接口测试:
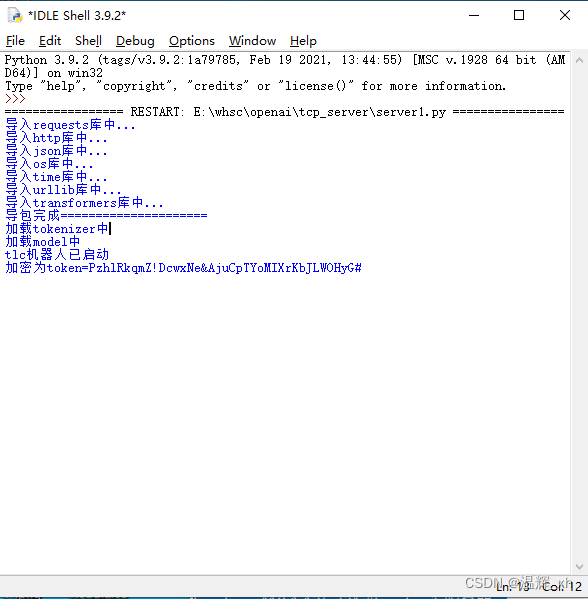
1.运行代码:
运行代码后,如果提示如下图所示就是没有问题的了,可以看到有一个token=xxxx的参数,这个参数是随机生成的临时token,目前设定是每次启动服务端生成一次,这里为了方便演示打印出来,实际需要登录接口来获取,后续可以注释掉
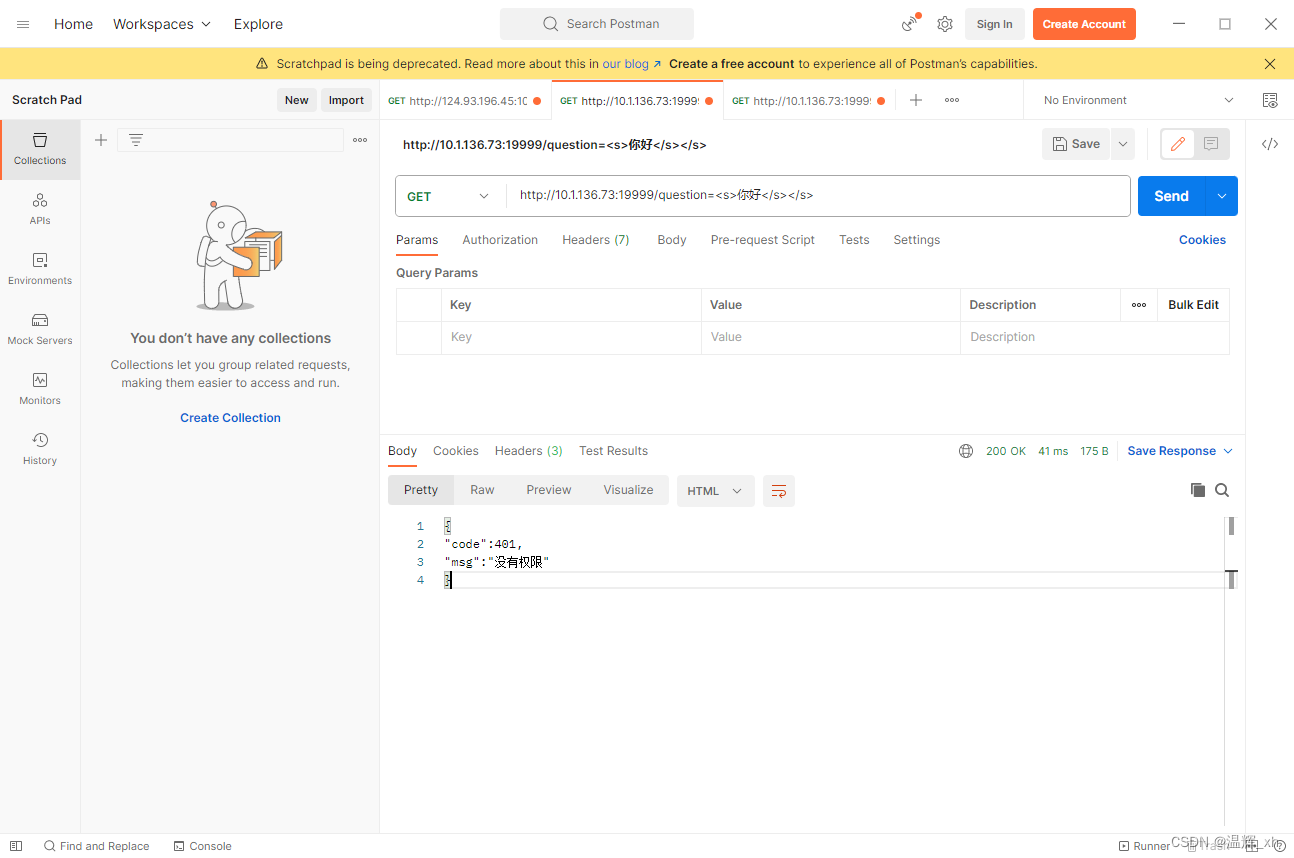
2.测试接口是否可用:
如下图所示在postman输入http://10.1.136.73:19999/question=<s>你好</s></s>
由于输出到模型的数据被格式化成<s></s>的形式,为方便客户端传递历史对话作为promat,我没有在python格式化字符串,而是在客户端里实现。
弹出401的提示是我们加入头,无法通过验证,但是可以证明http服务端可以正常跑起来
3.加入头继续验证:
在head加入参数名为Authorization,参数值为临时生成的token的head再次运行。发现已可行,如下图所示,发现客户端正常返回json

code参数:为200时正常,其他不正常,prompt是传入的值,msg是出来的值。
多轮对话:
在实际测试中发现Firefly1b4的版本也是可以支持多轮对话的,但是效果的确会差些,我们只需要在外部把数据格式化成以下的形式:
<s>问题1</s></s>回答1</s></s>问题2</s></s>回答2</s></s>问题3</s></s>回答3</s></s>
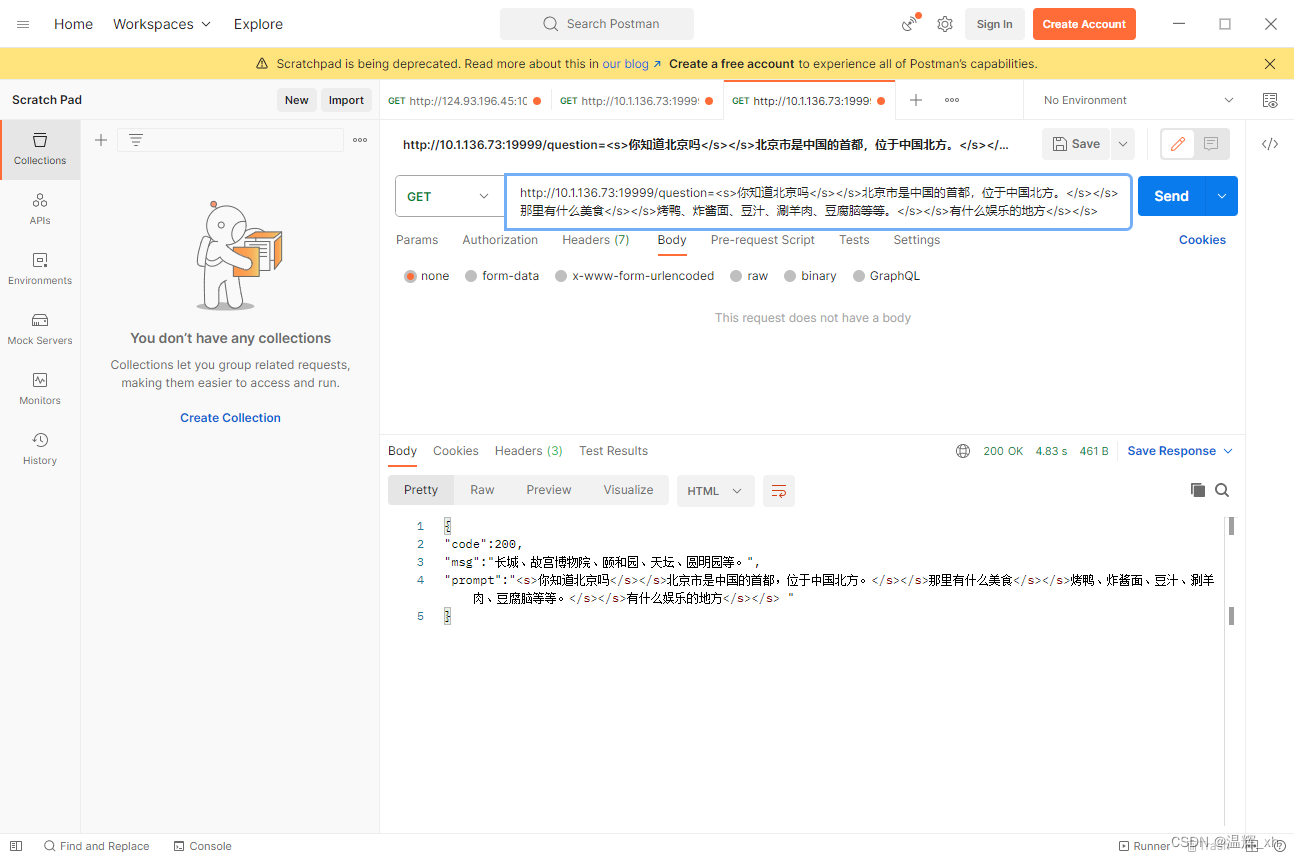
以下是效果案例:
传入的promat为<s>你知道北京吗</s></s>北京市是中国的首都,位于中国北方。</s></s>那里有什么美食</s></s>烤鸭、炸酱面、豆汁、涮羊肉、豆腐脑等等。</s></s>有什么娱乐的地方</s></s>
输出为长城、故宫博物院、颐和园、天坛、圆明园等。
Developed by 福州机电工程职业技术学校 wh
邮箱联系方式:[email protected]
qq联系方式:2151335401、3135144152