理论
理论部分可以借鉴上面的链接,非常浅显易懂,此处介绍层次分析法的实际案例——南京市土地价值指数评估。
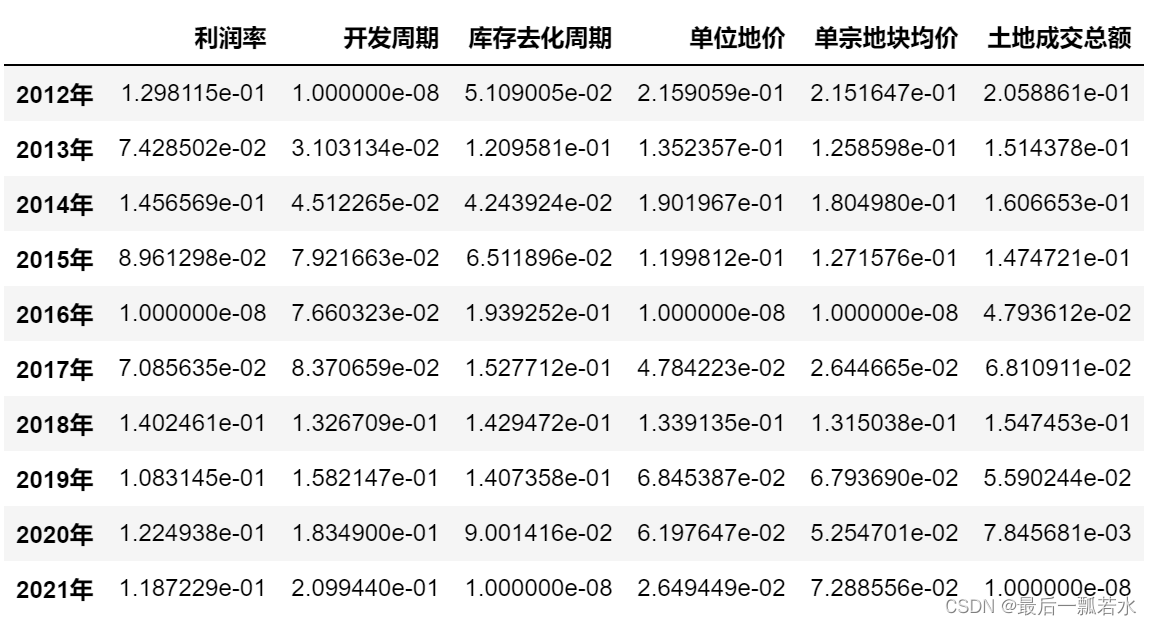
第一步:数据标准化
通过pandas读取数据,看看原始数据的本来面目,再根据数据的正向性(越大越好)或负向性(越小越好)进行0-1标准化,注意标准化的方法有很多,此处使用的标准化方法并不是唯一的,也不一定是最好的,更不是层次分析法要求的,标准化的方法要根据实际情况选择相对合理的。可以参考这篇文章的三种标准化方法。
(21条消息) sklearn库三种标准化与反标准化方法介绍_sklearn 标准化_最后一瓢若水的博客-CSDN博客
#读取数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
datas=pd.read_excel(r'C:\Users\1003\Desktop\土地指标\层次分析法所用指标.xlsx',index_col=0)#读取数据时把第一列当作索引
datas=datas.iloc[:,:-2]
datas
#数据标准化
columns=datas.columns.tolist()
#正向指标标准化
for col in columns[:1]:
datas[col]=(datas[col]-datas[col].min())/(datas[col].max()-datas[col].min())#(x-最小值)/(最大值-最小值)
datas[col]=datas[col]/datas[col].sum()#x/一列总和
#负向指标标准化
for col in columns[1:]:
datas[col]=(datas[col].max()-datas[col])/(datas[col].max()-datas[col].min())##(最大值-最x)/(最大值-最小值)
datas[col]=datas[col]/datas[col].sum()#x/一列总和
datas=datas.replace({0.000000:0.00000001})##此处把0值用一个极小值代替,可避免后续0作为分母报错注意:因为0-1标准化的最小值为0,但是后续计算经常会把标准化后的值放在分母位置导致报错,所以代码中把0用一个极小值代替。
第二步:构造判断矩阵
这是最关键、最核心的部分同时也是层次分析法饱受诟病的部分,通过主观比较每两个指标之间的相对重要性构造出判断矩阵,实质上就是在为每个指标赋权重。
判断依据借用文章开头链接里的内容,供参考。

结合判断依据由行业专家讨论上述有关房地产6大主要指标的重要性,构造出如下的判断矩阵。

#判断矩阵
a=np.array([[1,2,3,3,4,5],
[1/2,1,2,3,4,5,],
[1/3,1/2,1,2,3,5],
[1/3,1/3,1/2,1,2,3],
[1/4,1/4,1/3,1/2,1,2],
[1/5,1/5,1/5,1/3,1/2,1]])
a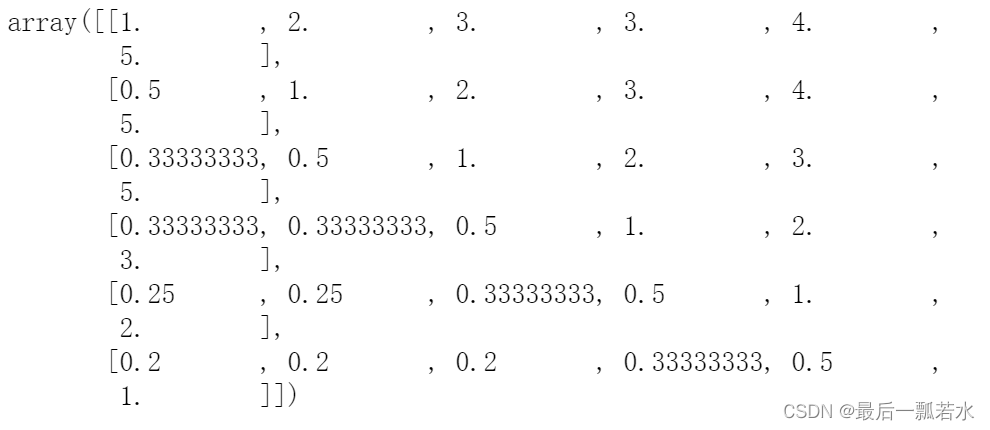
第三步:一致性检验
1、计算一致性指标CI
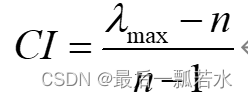
根据n(指标数量,此处n=6)查找相应的平均随机一致性指标RI,对n=1,2...9有对应的RI值:

2、计算一致性比例CR
CR=CI/RI
当CR<0.1时,通过一致性检验,说明判断矩阵可用,反之则需修改判断矩阵。
第四步:计算权重和得分
1、计算最大特征值组成的特征向量
![]()
a=np.array([[1,2,3,3,4,5],[1/2,1,2,3,4,5,],[1/3,1/2,1,2,3,5],[1/3,1/3,1/2,1,2,3],[1/4,1/4,1/3,1/2,1,2],[1/5,1/5,1/5,1/3,1/2,1]])
w=np.linalg.eig(a) #np.linalg.eig(matri)返回特征值和特征向量
max_feature=np.max(w[0]) #最大特征值
t=np.argwhere(w[0]==max_feature) #寻找最大特征值所在的行和列
vector=w[1][::-1,t[0]] #最大特征值组成的特征向量
print(vector)
2、计算权重向量

3、加权计算每一年的得分
S=P*W
得到历年南京市土地价值指数:

最后我们画个折线图看一下趋势:
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.plot([x for x in range(2012,2022)],land_value1[:],marker='o')
plt.title('南京市2012-2021年土地价值指数评价')
plt.xlabel('年份')
plt.ylabel('土地价值指数')
plt.grid()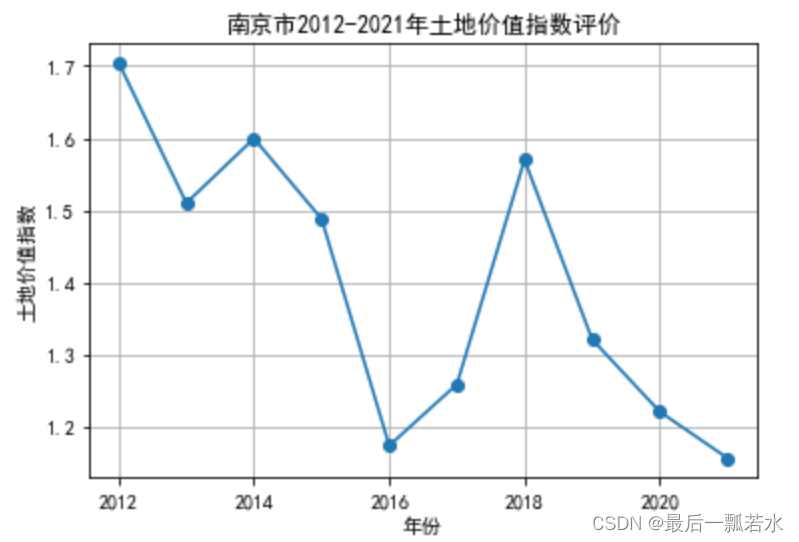
python 完整代码如下:
#数据标准化
columns=datas.columns.tolist()
for col in columns[:1]:#正向指标标准化
datas[col]=(datas[col]-datas[col].min())/(datas[col].max()-datas[col].min())
datas[col]=datas[col]/datas[col].sum()
#负向指标标准化
for col in columns[1:]:
datas[col]=(datas[col].max()-datas[col])/(datas[col].max()-datas[col].min())
datas[col]=datas[col]/datas[col].sum()
datas=datas.replace({0.000000:0.00000001})
#层次分析法
import matplotlib.pyplot as plt
land_value1=[]#存储每个评价对象的评价值,即土地价值指数
#计算特征向量和最大特征值
#a为自己构造的输入判别矩阵
a=np.array([[1,2,3,3,4,5],[1/2,1,2,3,4,5,],[1/3,1/2,1,2,3,5],[1/3,1/3,1/2,1,2,3],[1/4,1/4,1/3,1/2,1,2],[1/5,1/5,1/5,1/3,1/2,1]])
w=np.linalg.eig(a) #np.linalg.eig(matri)返回特征值和特征向量
max_feature=np.max(w[0]) #最大特征值
t=np.argwhere(w[0]==max_feature) #寻找最大特征值所在的行和列
vector=w[1][::-1,t[0]] #最大特征值组成的特征向量
print(vector)
#一致性检验
RILIST=[0,0,0.58,0.9,1.12,1.24,1.32,1.41,1.45,1.49,1.52,1.54,1.56,1.58,1.59]
n=a.shape[0]
RI=RILIST[n-1]#n是指标个数,n=6对应RILIST索引值为5的元素
CI=(max_feature-n)/(n-1)
CR=CI/RI
print(CR)
print("通过一致性检验") if CR<0.1 else print("没有通过一致性检验")
P=np.array(datas.values.tolist())#每一行代表一个对象的指标评分
#赋权重
power=np.zeros((n,1));
power=vector/sum(vector)
print(power)
Q=power
#显示出所有评分对象的评分值
score1=np.dot(P,Q) #矩阵乘法
score=score1*4+1
for i in range(len(score1)):
print('{}价值指数:{}'.format(2012+i,score[i,0].real))
land_value1.append(score[i,0].real)
#[1,2,3,3,4,5],[1/2,1,2,3,4,5,],[1/3,1/2,1,2,3,5],[1/3,1/3,1/2,1,2,3],[1/4,1/4,1/3,1/2,1,2],[1/5,1/5,1/5,1/3,1/2,1]
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.plot([x for x in range(2012,2022)],land_value1[:],marker='o')
plt.title('南京市2012-2021年土地价值指数评价')
plt.xlabel('年份')
plt.ylabel('土地价值指数')
plt.grid()层析分析法是非常经典的赋权方法,但是考虑到层次分析法赋权时的主观性比较强所以我们在建模时会更多用到熵权法,一种客观赋权方法,下一篇基于同样的数据用熵权法试试,需要数据的可私聊或者评论,我把数据分享给需要的同学一起学习。