一、时间模块
1、常用时间模块
import time # 时间分为三种格式 #1、时间戳---------------------以秒计算 # start= time.time() # time.sleep(3) # stop= time.time() # print(stop - start) #2、格式化的字符串形式------------格式化的时间格式是字符串形式的 print(time.strftime('%Y-%m-%d %X')) print(time.strftime('%Y-%m-%d %H:%M:%S %p')) #3、 结构化的时间/时间对象-------------结构化的时间格式, t1=time.localtime() #与世界标准时间超前8个小时 print(t1) #time.struct_time(tm_year=2018, tm_mon=6, tm_mday=20, tm_hour=19, tm_min=53, tm_sec=42, tm_wday=2, tm_yday=171, tm_isdst=0) # print(type(t1.tm_min)) # print(t1.tm_mday) #通过对象里的属性可以直接进行取值 t2=time.gmtime() #世界标准时间 # print(t1) print(t2) #time.struct_time(tm_year=2018, tm_mon=6, tm_mday=20, tm_hour=11, tm_min=53, tm_sec=42, tm_wday=2, tm_yday=171, tm_isdst=0) print(t2.tm_hour)
2、时间转换
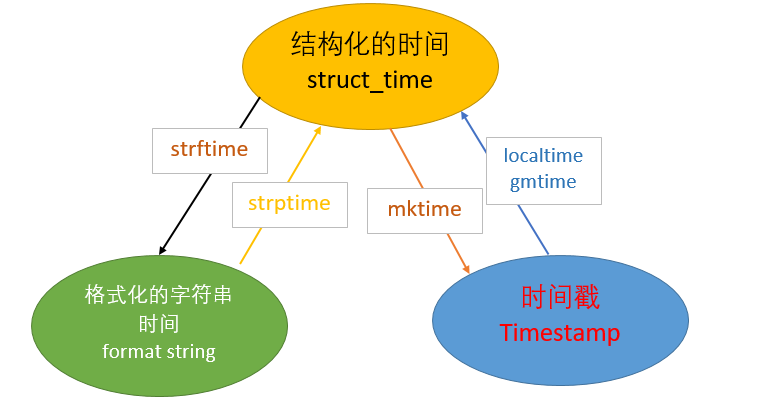
# 时间转换 # print(time.localtime(123123123)) # print(time.gmtime(123123123)) # print(time.mktime(time.localtime())) # print(time.strftime('%Y',time.localtime())) # print(time.strptime('2011-03-07','%Y-%d-%m')) # print(time.asctime()) # print(time.ctime()) # print(time.strftime('%a %b %d %H:%M:%S %Y')) # print(time.asctime(time.localtime())) # print(time.ctime(123123123)) # print(time.strftime('%Y-%m-%d %X')) # 获取格式化字符串形式的时间麻烦 # 时间戳与格式化时间之间的转换麻烦 # 获取之前或者未来的时间麻烦
解决以上问题见下文
3、datetime模块
import datetime # print(datetime.datetime.now()) # print(datetime.datetime.fromtimestamp(1231233213)) # print(datetime.datetime.now() + datetime.timedelta(days=3)) # print(datetime.datetime.now() + datetime.timedelta(days=-3)) # s=datetime.datetime.now() # print(s.replace(year=2020))
二、random模块
import random # print(random.random()) #只能随机取0到1之间的小数 # print(random.randint(1,3)) #随机取1或2或3中的一个 # print(random.randrange(1,3)) #顾头不顾尾,随机取1或2中的一个 print(random.choice([1,'egon',[1,2]])) #随机从列表中取一个 # print(random.sample([1, 'aa', [4, 5]], 2))#随机从列表中任意取两个,可以指定随机取的个数 # print(random.uniform(1,3)) #可以指定随机取的小数的区间 # item=['a','b','c','d'] # random.shuffle(item) #打乱重新进行洗牌 # print(item)
三、json与pickle模块
基本概念
01 什么是序列化/反序列化 序列化就是将内存中的数据结构转换成一种中间格式存储到硬盘或者基于网络传输 发序列化就是硬盘中或者网络中传来的一种数据格式转换成内存中数据结构 02 为什要有 1、可以保存程序的运行状态 2、数据的跨平台交互 03 怎么用 json 优点: 跨平台性强 缺点: 只能支持/对应python部分的数据类型 pickle 优点: 可以支持/对应所有python的数据类型 缺点: 只能被python识别,不能跨平台
1、json的注意点
# json格式不能识别单引号,全都是双引号 import json with open('db1.json','rt',encoding='utf-8') as f: json.load(f) json.loads('{"name":"egon"}') import json print(json.loads("{'name':'egon'}")) #会报错,json文件里不存在单引号。反序列化对象里面不能有单引号 with open('db.json','wt',encoding='utf-8') as f: l=[1,True,None] json.dump(l,f) # 用json反序列化---------------------load或loads with open('db.json','rt',encoding='utf-8') as f: l=json.load(f) print(l) # 用eval反序列化:eval只是单纯的将文件里的字符串运行变成对应的数据类型,而不会把json文件里卖弄的true,null转换成True,None with open('db.json','rt',encoding='utf-8') as f: s=f.read() #s ='[1, true, null]' dic=eval(s) #eval('[1, true, null]') print(dic['name'])
2、json的反序列化
import json dic={'name':'egon','age':18,'sex':'male'} #反序列化:中间格式json-----》内存中的数据类型 #1、从文件中读取json_str with open('db.json','rt',encoding='utf-8') as f: json_str=f.read() #2、将json_str转成内存中的数据类型-------------------反序列化:loads dic=json.loads(json_str) # loads的对象必须是字符串 #1和2可以合作一步 with open('db.json','rt',encoding='utf-8') as f: dic=json.load(f) # 文件对象 print(dic['sex'])
3、json的序列化
import json dic={'name':'egon','age':18,'sex':'male'} #序列化:内存中的数据类型------>中间格式json # 1、序列化得到json_str 序列化以后的数据类型就变成字符串-------------序列化:dumps json_str=json.dumps(dic) # 2、把json_str写入文件 with open('db.json','wt',encoding='utf-8') as f: f.write(json_str) #1和2合为一步 with open('db.json','wt',encoding='utf-8') as f: json.dump(dic,f) # 序列化对象 目标文件 print(json_str,type(json_str)) # json格式不能识别单引号,全都是双引号
4、pickle的反序列化
import pickle # #1、从文件中读取pickle格式 with open('egon.json','rb') as f: pkl=f.read() #2、将json_str转成内存中的数据类型---------------反序列化:loads dic=pickle.loads(pkl) print(dic['a']) #1和2可以合作一步 with open('db.pkl','rb') as f: dic=pickle.load(f) print(dic['a']) # pickle 的序列化 import json,pickle s={1,2,3} # json.dumps(s)------------------序列化:dumps pickle.dumps(s) import pickle dic={'a':1,'b':2,'c':3} # 1 序列化 pkl=pickle.dumps(dic) # 字典序列化后变成字节,不是字符串------------序列化:dumps print(pkl,type(pkl)) # #2 写入文件 with open('db.pkl','wb') as f: # 对应的写入文件就应该是wb模式写入 f.write(pkl) # 1和2可以合作一步 with open('db.pkl','wb') as f: pickle.dump(dic,f)
5、pickle的序列化
import pickle dic={'a':1,'b':2,'c':3} #1 序列化 pkl=pickle.dumps(dic) # print(pkl,type(pkl)) #2 写入文件 with open('db.pkl','wb') as f: f.write(pkl) # 1和2可以合作一步 with open('db.pkl','wb') as f: pickle.dump(dic,f)