目录
JSON
概念
JSON 是一种轻量级的数据交换格式。
理解
数据交换格式那么多,为啥还要学个 JSON?
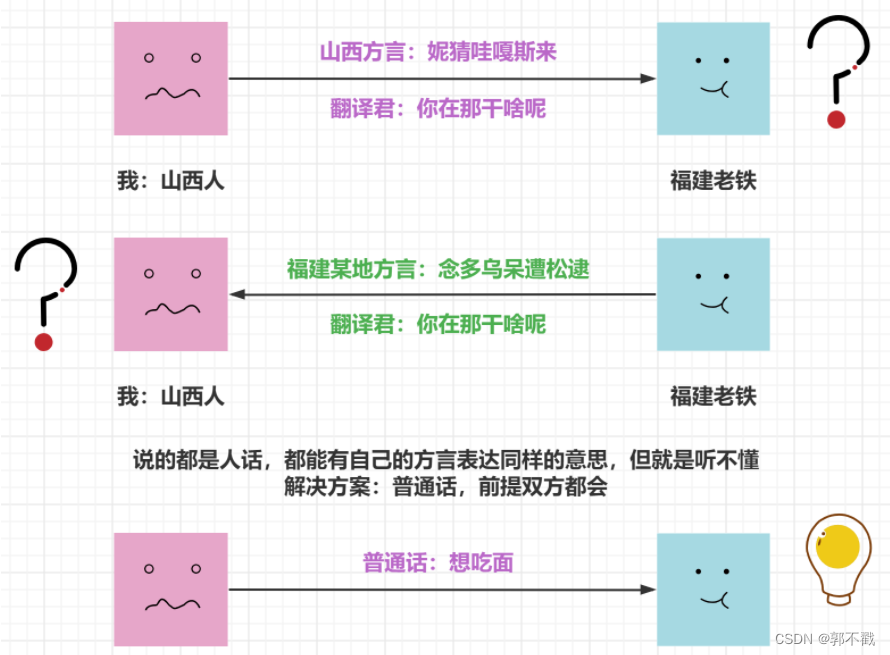
数据交换格式是不同平台、语言中进行数据传递的通用格式。比如 Python 和 Java 之间要对话,你直接传递给 Java 一个 dict 或 list 吗?Java 会问,这是什么鬼?虽然它也有字典和列表数据类型,但两种字典不是一个“物种”,根本无法相互理解。这个时候就需要用 Json 这种交换格式了,Python 和 Java 都能理解 Json。那么别的语言为什么能理解 Json 呢?因为这些语言都内置或提供了 Json 处理模块,比如 Python 的 json 模块。
基本用法
JSON格式: 在各种语言中,都可以被读取,被用作不同语言的中间转换语言【类似翻译器】
主要结构
-
“键/值” 对的集合;python 中主要对应 字典
-
值的有序列表;在大部分语言中,它被理解为 数组
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
常用函数
-
loads 方法:对编码后的 json 对象进行 decode 解密,得到原始数据,需要使用的 json.loads() 函数
-
**dumps 方法:**可以将原始数据转换为 json 格式
案例
[root@localhost xxx]# python3
>>> import json # 导入json模块
>>> adict = {
'user': 'tom', 'age': 20} # 定义字典adict
>>> data = json.dumps(adict) # dumps(),将字典转换为json格式【字符串类型】,赋值给变量data
>>> data # 查看变量的内容,字符串
>>> type(data) # 查看变量data的数据类型,为字符串类型
>>> jdata = json.loads(data) # l将json格式【字符串类型】转换为字典,赋值给变量jdata
>>> jdata # 查看变量data的值,字典
>>> type(jdata) # 查看jdata的数据类型,为字典类型
requests 模块
requests 简介
-
requests 是用 Python 语言编写的、优雅而简单的 HTTP 库
-
requests 内部采用来 urillib3
-
requests 使用起来肯定会比 urillib3 更简单便捷
-
requests 需要单独安装
GET 和 POST
- 通过 requests 发送一个 GET 请求,需要在 URL 里请求的参数可通过 params 传递
- 与 GET 不同的是,POST 请求新增了一个可选参数 data,需要通过 POST 请求传递 body 里的数据可以通过 data 传递
requests 发送 GET 请求
案例 1:处理文本数据
[root@localhost xxx]# pip3 install requests # 安装requests软件包
# 使用requests处理文本数据,使用text查看【get】
[root@localhost xxx]# python3
>>> import requests # 导入requests模块
>>> url = 'http://www.163.com' # 声明变量,定义要操作的网页
>>> r = requests.get(url) # 请求,获取网页内容,赋值给变量r
>>> r.text # 查看网页内容,因为是文本类型的,采用text查看
案例 2:处理图片视频音频等数据
>>> url2 = 'http://pic1.win4000.com/wallpaper/6/58f065330709a.jpg' # 声明变量,定义查看的图片
>>> r2 = requests.get(url2) # 请求,获取bytes类型的图片数据,赋值给变量r
>>> r2.content # 查看图片内容,因为是图片类型的,采用content查看
>>> with open('/tmp/aaa.jpg', 'wb') as fobj: # 将图片数据保存在文件aaa.jpg中
... fobj.write(r2.content)
[root@localhost xxx]# eog /tmp/aaa.jpg #在终端使用eog打开图片aaa.jpg
练习:下载新浪首页图片
import re,os,requests
def download(url, fname):
with open(fname, mode="wb") as fw:
fw.write(requests.get(url).content)
def get_url(fname, patt): # patt: 匹配图片正则 fname: 正则匹配文本的路径
result = [] # 定义存储图片url地址的列表
patt_obj = re.compile(patt) # 编译正则表达式 patt_obj: 正则对象,可用于匹配数据
with open(fname, mode="r") as fr:
for item in fr.readlines():
data = patt_obj.search(item) # 匹配图片链接
if data != None: # 匹配成功
result.append(data.group())
return result
if __name__ == '__main__':
if os.path.exists("/opt/myweb.html") == False: # 将网页源代码的数据存储到/opt/myweb.html
download("https://www.sina.com.cn/", "/opt/myweb.html")
if os.path.exists("/tmp/images") == False: # 指定图片下载的目录 /tmp/images
os.mkdir("/tmp/images")
pic_patt = "(http|https)://[\w\./-]+\.(jpg|jpeg|png)" # 匹配图片的正则表达式
res_list = get_url("/opt/myweb.html", pic_patt) # 返回图片url列表
for item in res_list:
download(item, "/tmp/images/"+os.path.basename(item))
案例 3:处理 json 格式的数据
天气预报查询
- 搜索 中国天气网 城市代码查询, 查询城市代码
- 城市天气情况接口
- 实况天气获取: http://www.weather.com.cn/data/sk/城市代码.html
>>> url3 = 'http://www.weather.com.cn/data/sk/101130101.html' # 声明变量,指定乌鲁木齐城市天气的网页路径
>>> r3 = requests.get(url3) # 请求,获取bytes类型的图片数据,赋值给变量r
>>> r3.json() # json(), 查看json类型的数据,乱码【字符集错误】
>>> r3.encoding # 查看获取网页数据的字符集
'ISO-8859-1'
>>> r3.encoding = 'utf8' # 将网页数据,转换为'utf8'格式
>>> r3.json() # json(), 查看json类型的数据【utf8】
设定头部
- 用户也可以自己设定请求头
- 获取网站的【User-Agent】请求头信息

# 用户自己设定请求头,查看Forbidden禁止访问的网站
[root@localhost xxx]# python3
>>> js_url = 'http://www.jianshu.com' #声明变量,指定简书的网站
>>> headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'} #声明访问网站的请求头
>>> r = requests.get(js_url, headers=headers) #获取简书网页数据, 自定义请求头
>>> r.text #以文本的方式,查看数据内容【Forbidden 简书网站进行了反爬虫设置】
pickle 模块
模块简介
- 把数据写入文件时,常规的文件方法只能把字符串对象写入。其他数据需先转换成字符串再写入文件
- python 提供了一个标准的模块,称为 pickle。使用它可以在一个文件中 存储任何 python 对象,之后又可以把它完整无缺地取出来
主要方法
| 方法 | 功能 |
|---|---|
| pickle.dump(obj, file) | 将 Python 数据转换并保存到 pickle 格式的文件内 |
| pickle.load(file) | 从 pickle 格式的文件中读取数据并转换为 python 的类型 |
基本使用
- 常规方法写入数据,只能是字符串类型,其他类型无法写入,例如:int,字典,列表等类型;
- pickle模块,可以在文件中存储任何类型的数据,也可以完整取出任何类型的数据;
pickle 模块方法
>>> f = open('/tmp/a.data', mode='wb') # 打开文件/tmp/a.data,以字节的方式写入
>>> user = {
'name': 'tom', 'age': 20} # 定义字典user
>>> import pickle # 导入模块pickle,可以写入和取出不同类型的数据
>>> pickle.dump(user,f) # pickle.dump(), 将字典user, 写入到对象f中【/tmp/a.data】
>>> f.close() # 关闭打开的文件
>>> f = open('/tmp/a.data', mode='rb') # 打开文件/tmp/a.data,【以字节的方式读取】
>>> adict = pickle.load(f) # 取出对象f中【/tmp/a.data】所有数据,赋值给变量adict
>>> adict # 查看字典adict中内容
案例:修改登录注册程序
import pickle
import os
def write_dict():
# 如果该文件不存在,才去初始化
if os.path.exists("/tmp/user.data") == False:
userdb = {
} # 用户存储用户信息
fw = open("/tmp/user.data", mode="wb")
pickle.dump(userdb, fw)
fw.close()
def register():
username = input("username:") # 接收用户从键盘输入的用户名
# 读取字典数据
fr = open("/tmp/user.data", mode="rb")
user = pickle.load(fr)
fr.close()
if username in user.keys():
print("用户名已存在")
else: # 用户名可用
password = input("password: ") # 提示用户输入密码
# 将用户信息添加到字典
user[username] = password
# 将修改后的user字典重新写入到文件当中
fw = open("/tmp/user.data", mode="wb")
pickle.dump(user, fw)
fw.close()
def login():
username = input("username:") # 接收用户从键盘输入的用户名
password = input("password:") # 用户输入的密码
# 读取字典数据
fr = open("/tmp/user.data", mode="rb")
user = pickle.load(fr)
fr.close()
if user.get(username) != password:
print("登陆失败")
else:
print("登陆成功")
def show_menu():
write_dict()
while True:
choice = input("1.register 2.login 3.退出 Please enter choice(1/2/3): ")
if choice not in ["1", "2", "3"]:
print("请正确输入(1/2/3)!!!!")
continue
elif choice == "3":
print("Byebye~")
break
elif choice == "1":
register() # 注册函数
else:
login() # 登陆函数
if __name__ == '__main__':
show_menu()