最近在做实验的时候,需要计算两个向量之鉴的相似性,该如何实现呢?
文章目录
计算两个向量之间的相似性是数据分析和机器学习中的常见任务。相似性度量可以用于比较文本、图像、用户偏好等各种类型的数据。以下是一些常用的方法来计算两个向量之间的相似性:
一、余弦相似性(Cosine Similarity)
余弦相似性(Cosine Similarity)是一种用于度量两个向量之间相似性的方法,通常在多维空间中使用。它衡量了两个向量之间夹角的余弦值,从而提供了一种评估它们之间关系的方式。余弦相似性通常用于文本处理、信息检索、推荐系统和聚类分析等领域。
1.1 理论
余弦相似性的计算公式如下:
cosine_similarity(A, B) = (A dot B) / (||A|| * ||B||)
其中:
- A 和 B 是两个要比较的向量。
- dot 表示向量的点积,也称为内积,它是两个向量对应元素的乘积之和。
- ||A|| 和 ||B|| 表示向量的模(或长度),它可以通过计算每个向量元素的平方和然后取平方根来得到。
余弦相似性的值范围在-1到1之间:
- 当余弦相似性等于1时,表示两个向量在多维空间中的方向完全相同,即它们是完全相似的。
- 当余弦相似性等于0时,表示两个向量之间不存在线性关系,它们是不相关的。
- 当余弦相似性等于-1时,表示两个向量在多维空间中的方向正好相反,即它们是完全不同的。
余弦相似性的特点:
- 不受向量长度影响:余弦相似性不受向量的绝对大小影响,只受方向影响,因此适用于任何维度的向量比较。
- 忽略零元素:余弦相似性可以有效地处理稀疏向量,因为它忽略了两个向量中的零元素。
- 范围有界:余弦相似性的范围始终在-1到1之间,易于解释和比较。
应用领域:
- 文本处理:在自然语言处理中,可以使用余弦相似性来比较文档、句子或词向量,以确定它们之间的相似性,用于信息检索、文本分类和推荐系统。
- 图像处理:在计算机视觉中,可以使用余弦相似性来比较图像特征向量,用于图像检索和相似图像查找。
- 推荐系统:在推荐系统中,可以使用余弦相似性来比较用户与商品之间的偏好向量,从而提供个性化的推荐。
- 聚类分析:在聚类分析中,余弦相似性可用于度量样本之间的相似性,从而将相似的样本聚集在一起。
1.2 实践
1.2.1 文本处理
在文本处理中,余弦相似性常用于比较文档、句子或词向量之间的相似性。以下是使用Python的示例代码,演示如何计算两个文本向量的余弦相似性。在这个示例中,我们将使用scikit-learn库来进行向量化和相似性计算。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 示例文本
text1 = "This is the first document."
text2 = "This document is the second document."
text3 = "And this is the third one."
text4 = "Is this the first document?"
# 创建TfidfVectorizer对象,用于将文本转换为TF-IDF向量
vectorizer = TfidfVectorizer()
# 将文本向量化
tfidf_matrix = vectorizer.fit_transform([text1, text2, text3, text4])
# 计算余弦相似性
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
# 打印相似性矩阵
print("相似性矩阵:")
print(cosine_sim)
# 打印文本之间的相似性
print("\n文本之间的相似性:")
print("文本1与文本2的相似性:", cosine_sim[0][1])
print("文本1与文本3的相似性:", cosine_sim[0][2])
print("文本1与文本4的相似性:", cosine_sim[0][3])
我们的输出结果为:
相似性矩阵:
[[1. 0.64692568 0.30777187 1. ]
[0.64692568 1. 0.22523955 0.64692568]
[0.30777187 0.22523955 1. 0.30777187]
[1. 0.64692568 0.30777187 1. ]]
文本之间的相似性:
文本1与文本2的相似性: 0.6469256761082494
文本1与文本3的相似性: 0.30777186787740496
文本1与文本4的相似性: 1.0
这个代码示例首先将文本向量化为TF-IDF(Term Frequency-Inverse Document Frequency)向量,然后使用cosine_similarity函数计算文本之间的余弦相似性。最后,打印出相似性矩阵以及不同文本之间的相似性。
1.2.2 图像处理
余弦相似性通常用于图像处理中的图像相似性比较。在图像处理领域,我们通常将图像表示为像素值、颜色直方图或特征向量,然后使用余弦相似性来比较不同图像之间的相似性。以下是一个示例代码,演示如何使用 Python 和 OpenCV 库计算两个图像之间的余弦相似性。
import cv2
import numpy as np
# 读取两个图像
image1 = cv2.imread('./cropped_(0, 0, 8, 12)_obj365_val_000000595783.jpg')
image2 = cv2.imread('./cropped_(0, 0, 121, 168)_obj365_val_000000105931.jpg')
# 将图像转换为灰度图像
gray_image1 = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)
gray_image2 = cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY)
# 计算图像的直方图
hist1 = cv2.calcHist([gray_image1], [0], None, [256], [0, 256])
hist2 = cv2.calcHist([gray_image2], [0], None, [256], [0, 256])
# 将直方图转换为归一化的直方图
hist1 /= hist1.sum()
hist2 /= hist2.sum()
# 计算余弦相似性
cosine_similarity = np.dot(hist1.T, hist2) / (np.linalg.norm(hist1) * np.linalg.norm(hist2))
# 打印相似性分数
print("余弦相似性:", cosine_similarity)
输出结果为:
余弦相似性: [[0.4896353]]
这个代码示例首先读取两个图像,然后将它们转换为灰度图像。接下来,使用 cv2.calcHist 计算图像的直方图,并将其归一化,以便进行余弦相似性计算。最后,计算两个图像的余弦相似性,并打印出相似性分数。
1.2.3 推荐系统
余弦相似性在推荐系统中常用于计算用户或物品之间的相似性,以便为用户提供个性化的推荐。以下是一个简单的 Python 示例代码,演示如何使用余弦相似性计算用户之间的相似性并进行基于用户的推荐。
在这个示例中,我们使用字典来表示用户评分的数据,其中键是用户ID,值是一个表示该用户对不同物品的评分的字典。我们将计算不同用户之间的余弦相似性,并基于相似性为用户生成物品推荐。
import numpy as np
# 用户评分数据,每个用户对不同物品的评分
user_ratings = {
'User1': {
'Item1': 4, 'Item2': 5, 'Item3': 3, 'Item4': 2},
'User2': {
'Item1': 2, 'Item2': 4, 'Item3': 5, 'Item4': 3},
'User3': {
'Item1': 5, 'Item2': 2, 'Item3': 3, 'Item4': 4},
'User4': {
'Item1': 1, 'Item2': 3, 'Item3': 2, 'Item4': 5},
}
# 计算用户之间的余弦相似性
def cosine_similarity(user1, user2):
common_items = set(user1.keys()) & set(user2.keys())
if len(common_items) == 0:
return 0.0 # 无共同评分的情况下相似性为0
vector1 = [user1[item] for item in common_items]
vector2 = [user2[item] for item in common_items]
dot_product = np.dot(vector1, vector2)
norm1 = np.linalg.norm(vector1)
norm2 = np.linalg.norm(vector2)
similarity = dot_product / (norm1 * norm2)
return similarity
# 为指定用户生成基于用户的推荐
def user_based_recommendation(target_user, user_ratings):
# 计算目标用户与其他用户的相似性
similarities = {
}
for user, ratings in user_ratings.items():
if user != target_user:
similarity = cosine_similarity(user_ratings[target_user], ratings)
similarities[user] = similarity
# 推荐未被目标用户评分的物品
recommendations = {
}
for item in user_ratings[target_user]:
if user_ratings[target_user][item] == 0: # 用户未评分的物品
weighted_sum = 0
similarity_sum = 0
for user, similarity in similarities.items():
if user_ratings[user][item] > 0: # 用户已评分的物品
weighted_sum += user_ratings[user][item] * similarity
similarity_sum += abs(similarity)
if similarity_sum > 0:
recommendations[item] = weighted_sum / similarity_sum
# 按推荐分数降序排序
sorted_recommendations = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)
return sorted_recommendations
# 为指定用户生成推荐
target_user = 'User1'
recommendations = user_based_recommendation(target_user, user_ratings)
# 打印推荐结果
print(f"为用户 {
target_user} 生成的推荐物品:")
for item, score in recommendations:
print(f"{
item}: 推荐分数 {
score}")
1.2.4 聚类分析
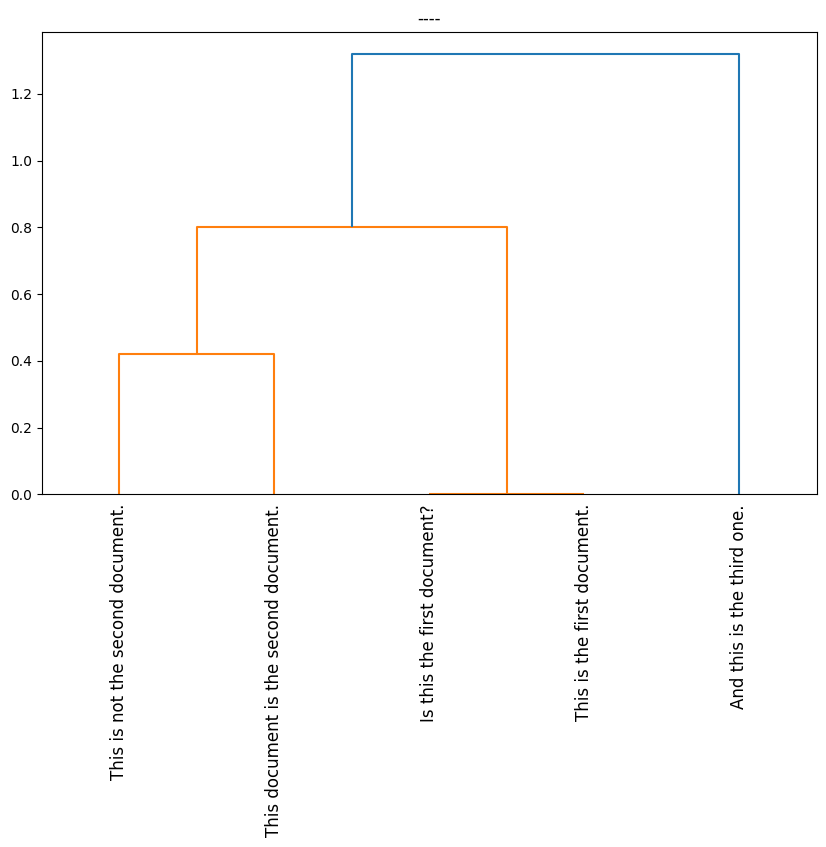
余弦相似性在聚类分析中常用于计算样本之间的相似性,特别是在文本聚类和高维数据聚类中。以下是一个简单的 Python 示例代码,演示如何使用余弦相似性计算文本数据的相似性并进行层次聚类分析(Hierarchical Clustering)。
在这个示例中,我们将使用 scikit-learn 库来执行层次聚类分析,并使用余弦相似性来计算样本之间的相似性。
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt
# 示例文本数据
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
"This is not the second document."
]
# 使用TF-IDF向量化文本数据
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(documents)
# 计算余弦相似性矩阵
cosine_similarities = cosine_similarity(tfidf_matrix)
# 使用层次聚类进行聚类分析
linkage_matrix = linkage(1 - cosine_similarities, method='average') # 使用相似性距离,method可根据需要更改
# 绘制树状图
plt.figure(figsize=(10, 6))
dendrogram(linkage_matrix, labels=documents, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.xticks(rotation=90)
plt.title('----')
plt.show()
这个示例代码首先使用 TF-IDF 向量化文本数据,然后计算文本之间的余弦相似性矩阵。接下来,使用层次聚类分析 (linkage 函数) 来聚类样本,并绘制树状图 (dendrogram) 以可视化聚类结果。
二、Jaccard相似性(Jaccard Similarity)
2.1 理论
Jaccard相似性(Jaccard Similarity),也称为Jaccard系数或Jaccard指数,是一种用于度量两个集合之间相似性的指标。它通常用于比较两个集合之间的重叠程度。Jaccard相似性是一个介于0和1之间的值,其中0表示两个集合没有共同元素,1表示两个集合完全相同。
Jaccard相似性的计算公式如下:
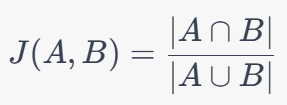

Jaccard相似性的特点和应用:
- 范围在0到1之间:Jaccard相似性的值始终在0到1之间,使其易于解释和比较。
- 对集合大小不敏感:Jaccard相似性不受集合大小的影响,只取决于两个集合的交集和并集。
- 用于文本和集合比较:Jaccard相似性常用于文本比较、推荐系统、社交网络分析和信息检索等领域,用于比较文档、用户兴趣等。
注意缺点:Jaccard相似性忽略了元素之间的数量信息,只关注是否存在重叠元素。这可能导致某些情况下的误导,特别是当集合的大小差异很大时。
总之,Jaccard相似性是一种用于比较两个集合之间相似性的有用指标,特别适用于集合或文本数据的比较任务。根据问题的特性,它可以用来衡量重叠程度,例如在推荐系统中衡量用户兴趣的相似性或在文本处理中衡量文档之间的相似性。
2.2 实践
在文本处理中衡量文档之间的相似性,可以使用Jaccard相似性来计算文档之间的重叠程度。
# 定义计算Jaccard相似性的函数
def jaccard_similarity(doc1, doc2):
# 将文本分割为单词并转换为集合
words1 = set(doc1.lower().split())
words2 = set(doc2.lower().split())
# 计算Jaccard相似性
intersection = len(words1.intersection(words2))
union = len(words1.union(words2))
similarity = intersection / union
return similarity
# 示例文档
document1 = "This is a sample document about text similarity."
document2 = "Text similarity is measured using Jaccard index."
# 计算文档之间的Jaccard相似性
similarity_score = jaccard_similarity(document1, document2)
# 打印相似性分数
print("文档之间的Jaccard相似性:", similarity_score)
在这个示例中,我们首先定义了一个名为 jaccard_similarity 的函数,该函数接受两个文本文档作为输入,并计算它们之间的Jaccard相似性。然后,我们提供了两个示例文档 document1 和 document2,并计算它们之间的Jaccard相似性。
请注意,为了计算Jaccard相似性,我们将文本拆分为单词,并将这些单词转换为小写字母,以确保大小写不敏感。然后,我们计算两个文档单词集合的交集和并集,并使用Jaccard公式计算相似性。
我们的输出结果为:
文档之间的Jaccard相似性: 0.15384615384615385
三、欧几里德距离(Euclidean Distance)
3.1 理论
欧几里德距离(Euclidean Distance),也称为欧式距离,是用于测量空间中两点之间的直线距离的度量。它是最常用的距离度量之一,通常用于欧几里德空间(Euclidean Space)中的点之间的距离计算。在二维平面上,欧几里德距离就是我们通常所说的两点之间的直线距离。

大家对此都比较熟悉,不再详细介绍。
欧几里德距离可以应用于计算两个向量之间的相似性。在这种情况下,欧几里德距离用于度量向量之间的差异或相似性,通常是在多维空间中的点或数据向量之间进行比较。
这种应用欧几里德距离计算相似性的方法可以用于许多应用中,例如:
- 推荐系统:用于计算用户或物品之间的相似性,以便为用户提供个性化的推荐。
- 文本分析:用于比较文档、文本段落或单词向量之间的相似性。
- 图像处理:用于比较图像特征向量,例如图像检索和相似图像查找。
- 聚类分析:用于聚类算法中的数据点之间的相似性度量。
- 数据降维:用于降维算法中的特征选择和特征权重计算。
需要根据具体的应用场景和数据类型来选择合适的相似性度量方法,欧几里德距离是其中之一,但不一定适用于所有情况。
3.2 实践
欧几里德距离通常不是首选的文本相似性度量方法,因为它不考虑文本的语义内容,而只是比较文本向量之间的距离。更常见的文本相似性度量方法之一是余弦相似性,因为它能够考虑文本向量的方向,适用于文本分析和文本挖掘任务。不过,如果你想尝试使用欧几里德距离来计算文本之间的相似性,可以将文本数据转换为向量表示,然后计算它们之间的距离。
以下是一个示例Python代码,演示如何使用欧几里德距离计算两个文本之间的相似性。在这个示例中,我们使用词袋模型将文本转换为向量,并计算它们之间的欧几里德距离。
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from scipy.spatial import distance
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
"This is not the second document."
]
# 创建词袋模型向量化器
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# 将文本向量表示转换为稀疏矩阵并计算欧几里德距离
document1_vector = X[0].toarray().ravel() # 使用ravel()方法展平向量
document2_vector = X[1].toarray().ravel()
euclidean_distance = distance.euclidean(document1_vector, document2_vector)
print("文档之间的欧几里德距离:", euclidean_distance)
输出结果为:
文档之间的欧几里德距离: 1.7320508075688772
四、曼哈顿距离(Manhattan Distance)
4.1 理论
曼哈顿距离(Manhattan Distance),也称为城市街区距离或L1距离,是一种用于测量空间中两点之间的距离的度量方法。与欧几里德距离不同,曼哈顿距离是通过计算两点之间在水平和垂直方向上的距离之和来衡量的。它通常用于在网格状或坐标轴对齐的空间中度量距离,例如城市街区的距离。

4.2 理论
在这种情况下,曼哈顿距离用于度量向量之间的差异或相似性,通常是在多维空间中的点或数据向量之间进行比较。
import cv2
import numpy as np
# 读取两个灰度图像
image1 = cv2.imread('./cropped_(0, 0, 121, 168)_obj365_val_000000105931.jpg', cv2.IMREAD_GRAYSCALE)
image2 = cv2.imread('./cropped_(0, 0, 135, 268)_obj365_val_000000433336.jpg', cv2.IMREAD_GRAYSCALE)
# 检查图像是否成功加载
if image1 is None or image2 is None:
print("无法加载图像")
else:
# 调整图像的大小为相同尺寸
if image1.shape != image2.shape:
image1 = cv2.resize(image1, (image2.shape[1], image2.shape[0]))
# 转换图像为 NumPy 数组
array1 = np.array(image1)
array2 = np.array(image2)
# 计算曼哈顿距离
manhattan_distance = np.sum(np.abs(array1 - array2))
# 打印曼哈顿距离
print("曼哈顿距离:", manhattan_distance)
输出结果为:
曼哈顿距离: 3715237