基于图像匹配的消防通道障碍物检测
技术背景
消防通道是指在各种险情发生时,用于消防人员实施营救和被困人员疏散的通道。消防法规定任何单位和个人不得占用、堵塞、封闭消防通道。事实上,由于消防通道通常缺乏管理,导致各种垃圾,物品以及车辆等障碍物常常出现在消防通道中,堵塞消防通道,当险情发生时,将对人们的生命财产带来巨大危害。因此,对消防通道的障碍物进行检测就显得尤为重要。
传统的消防通道障碍物检测主要依靠人工安全检查,指定专门工作人员定期到特定消防通道查看消防通道是否堵塞,此种方法虽然简单易行,不需要依靠复杂设备,但是该方法的缺点一是不能及时发现消防通道是否堵塞,受人工检查的周期影响大;二是较大地依赖工作人员的专业素质和工作态度,主观性强。
消防通道障碍物检测属于图像处理和智能安防领域。
采用固定摄像头,获取清空消防通道障碍物时的背景场景图像与实时监测场景图像,将背景场景图像作为匹配的模板图像,通过对模板图像与实时监测场景图像之间在指定区域内进行图像匹配,判断指定区域内是否存在障碍物,并予以报警。如下图,红色框内不能方有堆积物。有的话就报警提示

系统按一定时间间隔采集消防通道内指定监测区域的实时场景图像并进行匹配,既能保障系统能够实时检测到障碍物并予以报警,及时保障通道的畅通性,同时也降低了系统开销;另外基于特征的图像匹配用于消防通道障碍物检测,使得通道堵塞判定更加准确有效。
整体的流程图:
为了实现上述流程,需要执行一下几个重要步骤:
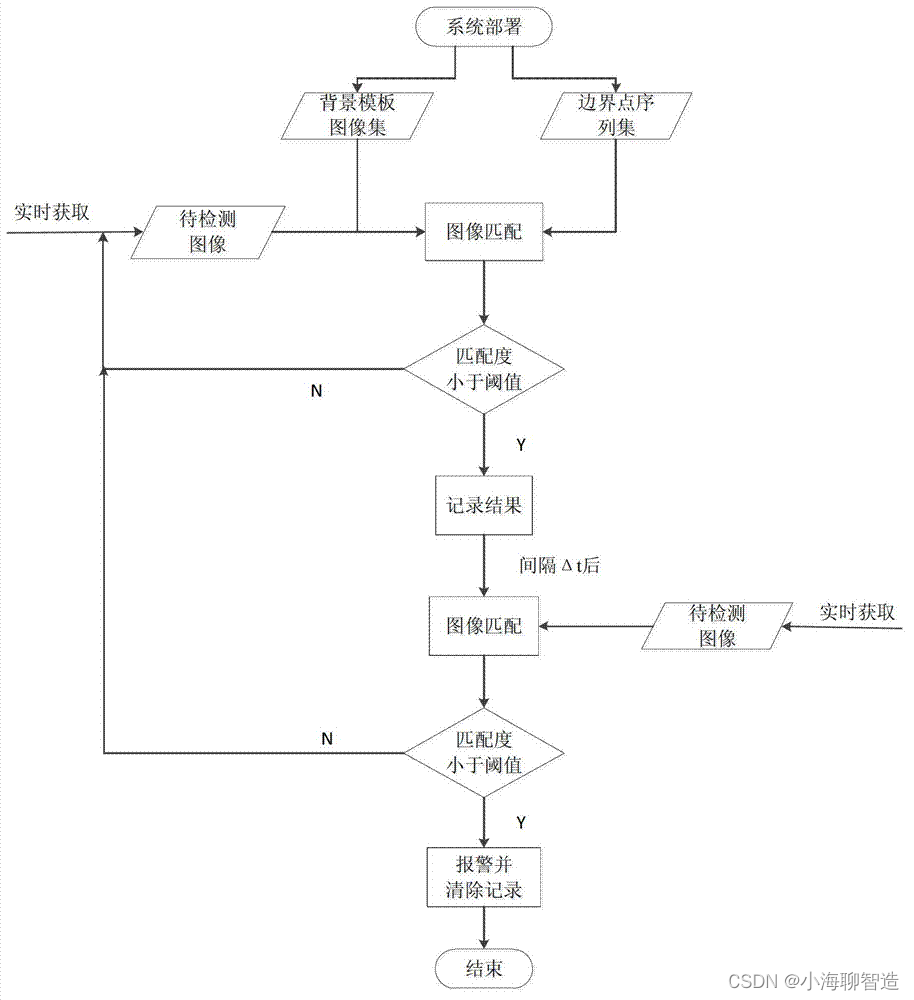
步骤1,在需要检测的通道架设摄像头,通过摄像头采集通道场景图像;
步骤2,摄像头检测通道系统部署过程中,保存背景模板图像形成背景模板图像集,并设置通道的重点检测区域;
步骤3,对背景模板图像集以及待匹配图像进行降噪预处理;
步骤4,计算每张背景模板图像集中的背景模板图像与待匹配图像的匹配度;
步骤5,计算待匹配图像与背景模板图像集的匹配度,根据背景模板图像集的匹配度与阈值的比较结果,判断当次检测待匹配图像中障碍物是否存在,障碍物存在则报警。
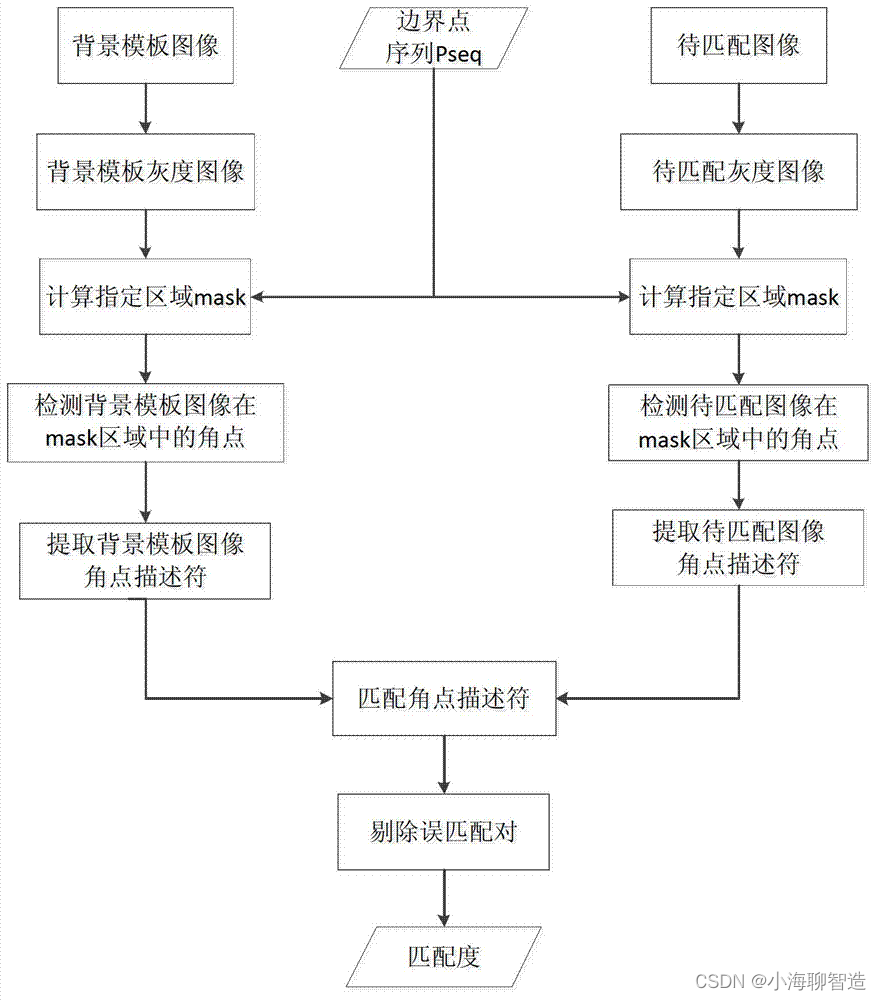
单张背景模板图像同待匹配图像之间的匹配主要包括如下过程:
首先需要在背景模板图像和待匹配图像的指定区域中进行特征点的提取。考虑到消防通道场景中光线问题,采用对光照变化具有一定抗干扰性的Harris角点作为特征点,该类特征点是有灰度图像的二阶导数计算而来,通常存在于图像中像素邻域内出现多个方向上的灰度变化的像素点上,因此能够很好的表示图像中的灰度值的变化范围,而光照变化对图像灰度值的影响在邻域范围内通常很小,因此Harris角点对光照具有一定的稳定性。
图像中像素点x的邻域指的是以x为中心,上下左右相邻的若干的像素组成的像素集。根据S2中获得的指定区域的边界点序列PSeq,在背景模板图像和待匹配图像中生成mask区域(即边界点包围的区域)。在背景模板图像和待匹配图像中的mask区域中分别提取出角点集BackCornerSet(背景角点集)和TestCornerSet(测试角点集)。其中BackCornerSet中有Nb个角点,而TestCornerSet中有Nt个角点。角点的个数根据图像内容不同会有较大变化,因此暂用Nb和Nt表示。角点集中包含各个角点的坐标,用于对各角点在图像中进行定位。
其次需要对背景模板图像和待匹配图像中的各个角点进行特征描述符的提取。所谓特征描述符是指对各个特征点所在像素点的特性进行描述的属性。各像素点最基本的属性是灰度值,但使用灰度值作为特征描述符不仅表示过于简单,而且忽略了该像素点同相邻像素点的关系,使得它并不能有效的表示特征的属性。通常采用特征点所在像素点的邻域内的特性来作为特征描述符。本发明采用以特征点所在像素点为中心的15×15大小的邻域,能够很好地涵盖特征点与影响较大的相邻像素点。对邻域内的像素点计算一阶梯度构成的向量作为特征点的特征描述符,一阶梯度能够减弱光照影响,使得该特征描述符对于光照也有一定的稳定性。部署过程结束后,图像匹配的场景便固定了,因此指定区域内的背景通常不会出现较为明显的旋转和尺度变化,因此一阶梯度作为特征描述符基本能够满足要求。针对的是根据角点集BackCornerSet和TestCornerSet中各角点的坐标分别在背景模板图像和待匹配图像中定位出各个角点,并根据各角点的邻域可计算得到背景模板图像和待匹配图像的特征描述符集BackDescriptorSet(背景特征描述符集)和TestDescriptorSet(测试特征描述符集)。
然后对背景模板图像和待匹配图像中提取出的特征描述符集进行匹配。匹配过程中,本发明采用欧式距离来计算两个特征描述符之间的相似度。对BackCornerSet和假设A为BackCornerSet中的任意一角点,B为TestCornerSet中的任意一角点,计算A到B1、B2、…、BNt各角点对应的特征描述符的相似度,选出相似度最大的角点Bj(j的可能取值为1到Nt之中任意整数),则A角点至Bj角点单向匹配;计算B到A1、A2、…、ANb各角点对应的特征描述符的相似度,选出相似度最大的角点Aj(j的可能取值为1到Nb之中任意整数),则B角点至Aj角点单向匹配。当且仅当A角点至B角点单向匹配的同时B角点至A角点也单向匹配的时候,A角点和B角点匹配,则A角点与B角点为一个匹配对。对BackCornerSet和TestCornerSet中角点进行匹配后,得到包含Q个匹配成功的匹配集MatchPairs。
最后需要对匹配对进行修正。匹配成功的匹配集MatchPairs中可能存在有同一角点同时匹配上多个角点的情况,同时也可能存在误匹配的焦点对,因此我们需要对MatchPairs进行修正。由于摄像头固定的情况下,获取的图像中指定区域内的背景内容不会发生较大变化,因此可以认为背景模板图像中的检测到的角点与在待匹配图像中的相应位置的匹配的角点之间的相对位移应该很小。基于这个原理,计算MatchPairs中各匹配对的两个角点的相对位移,如果位移偏差大于阈值Δs,则认为该匹配对为误匹配对。Δs的阈值可以设为5个像素(以适应物理环境的变化如摄像头抖动造成的图像内容偏移)。
对MatchPairs中的误匹配对进行删除操作,完成MatchPairs的修正。修正后的MatchPairs中含有Q*个匹配对。
基于深度学习的障碍物检测研究
YOLO是一种端到端的图像检测框架,其核心过程就是将整张图片作为网络的输入,可以在输出层直接得到物体的检测边界框,并标注其检测到得所属类别。YOLO使用了网格而非传统的滑动窗口,首先将一幅图片分成S * S个网格,每个网格需要预测一个中心点落在这个网格当中的物体;每个网格需要预测B个边界框(boundingbox),每个边界框都要回归一个位置信息,包括x,y,w,h,分别代表坐标信息和尺寸信息,同时还要再输出一个置信度值(confidencescore)。
效果如下图所示:

基于深度检测比opencv 的效率和准确度要高,但是深度安全通道检测有一个弊端 就是 必须要提前明确通道里会放哪些障碍物,这个就很容易被吐槽了,意味着你的模型到实际生产过程中需要不断对新的障碍物去训练识别。当然,这个也要看你自己的业务场景了。如果你的障碍物是固定的,那深度检测肯定是你的不二选择了。