参考教程
前期工作
使用labelimg标注
- 选择图片所在文件夹,并选择标注文件保存的文件夹。
- 灵活使用快捷键,有些快捷键可以在菜单栏查看。
W:生成框,按住鼠标左键拖动(或者右键点击生成矩形框),
A/D:前/后一张图片,
空格:高亮已经标注的图片,
Ctrl+鼠标滚轮:放大缩小图片,
Ctrl+F:把图片缩放到原来的大小,
Ctrl+E:点击边界框之后按下Ctrl+E,编辑标签,
Ctrl+S:保存,
还可以在菜单栏改变边界框的颜色,
左侧选项栏可以选择保存的标签文件模式,VOC模式就是xml,YOLO模式就是txt,还有json模式。 - 在view里修改标注模式,选中auto save mode,这样标注完一张直接点下一张(或者按D)就自动保存。
把文件放在对应位置
- 把使用的图片放在yolov7-pytorch-master\VOCdevkit\VOC2007\JPEGImages文件夹下;
- 把用labelimg标注产生的标签文件(格式为xml)的放在yolov7-pytorch-master\VOCdevkit\VOC2007\Annotations文件夹下;
- 在yolov7-pytorch-master\model_data中增加一个txt文件,写入要预测的类别都是什么;

- 修改voc_annotation.py文件中的classes_path为上一条中txt文件的路径,根据数据集规模修改trainval_percent和train_percent,运行voc_annotation.py文件,生成下面的文件

至此,准备工作完成。注意看里面的有些其他参数有可能也是需要改的,基本就改那些参数,每个参数都写了含义,根据情况选择修改。
训练
准备工作
装载云盘:
from google.colab import drive
drive.mount('/content/drive')
显示当前工作路径:
!pwd
修改路径:
%cd /content/drive/MyDrive/yolov7-pytorch-master
并更改运行时的类型使用GPU训练:
修改train.py文件中的几个参数,主要是:
- model_path:对应你预测时使用的权重参数;
- classes_path:对应你要预测类别存放的txt文件;
- epoch和batch:根据训练集规模设置,一般要求step>50000,step=dataset_size/batch_size*epoch。
- input_shape:输入图片的大小。
- 大概就改这几个。
防止掉线
听说可以通过自动点击来减少掉线频率。
在Google colab的按F12,点击网页的控制台Console,粘贴如下代码回车即可:
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);
开始训练
运行train.py文件。
运行了3个多小时。
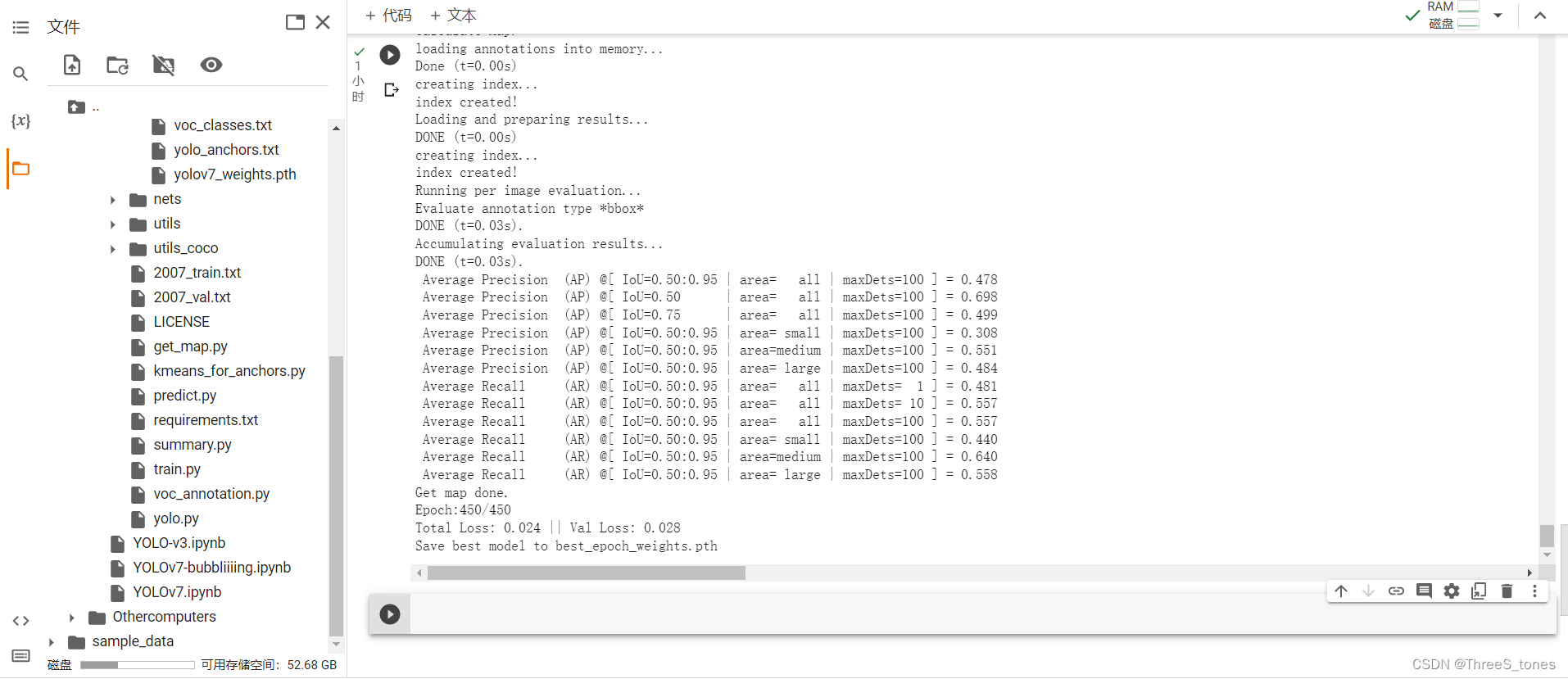
预测
修改yolo.py文件中的几个参数,主要是下面几个:
- model_path:对应你预测时使用的权重参数,就是logs文件夹下我们自己训练好的权值文件;
- classes_path:对应数据集所区分的类别对应的txt文件;
- input_shape:输入图片的大小,与train.py中的一致;
- letterbox_images:通过对图像添加灰条的方式保证图像的主体不发生失真;
- nms_iou:nms(非极大值抑制)筛选一定区域内预测同一种类得分最大的框。
nms设置得越小,筛选的越严格,最后的框数越少。
运行predict.py文件,
输入图片路径,

查看结果。
如果想预测一个文件夹下面的所有文件:
修改predict.py文件中的mode参数,默认遍历img文件夹,保存在img_out文件夹。
使用YOLOv7断点后继续训练
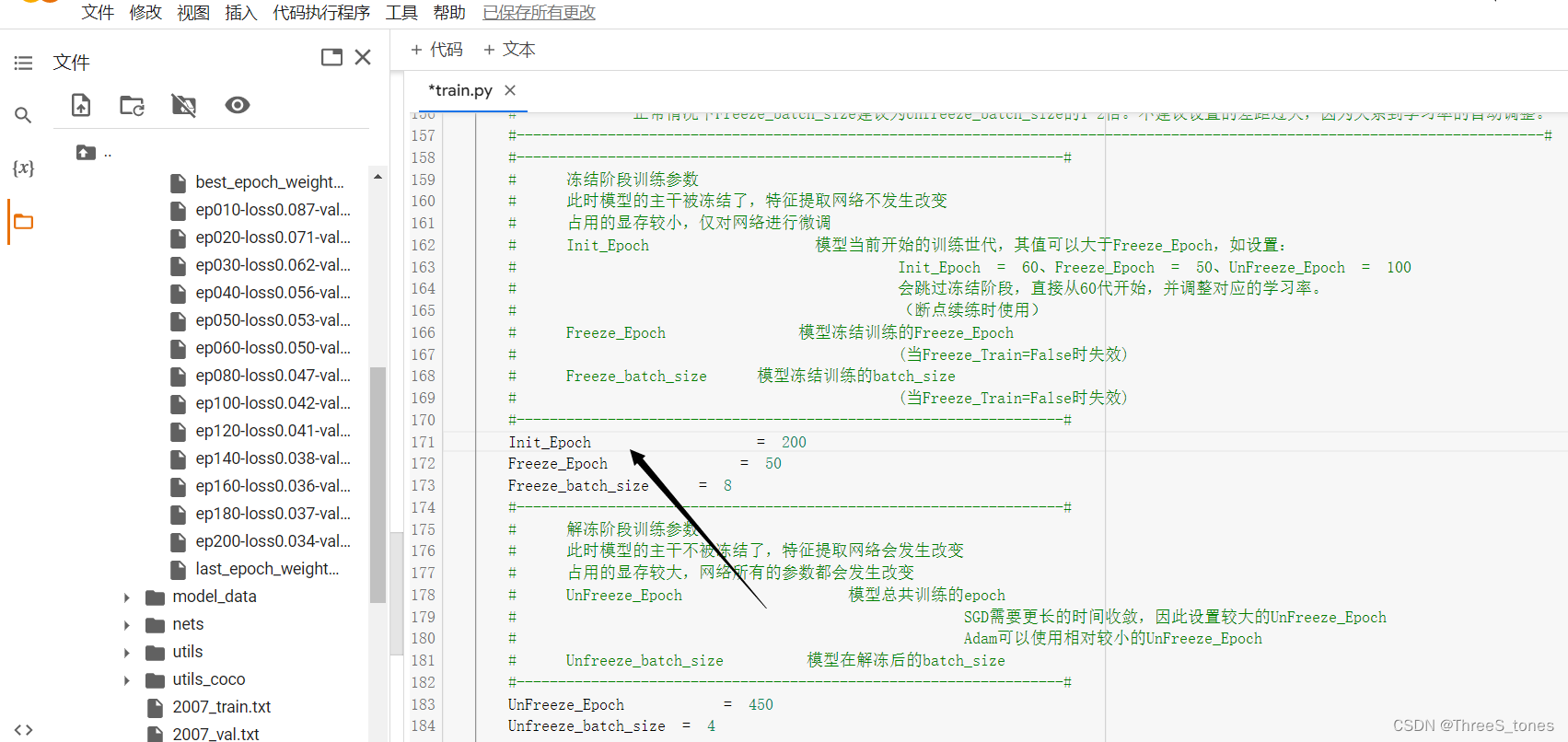
修改train.py中的两个参数:
-
model_path:

-
init_epoch:
使用colab调试
在第一行输入:
import pdb; pdb.set_trace() # debug mode
b / break 设定断点
c / continue 执行至断点
若无断点则直接全部执行
l / list 查看现在执行的程式码
s / step 进入函式
r / return 执行程式码直到从当前函式返回
q / exit 中止并退出 (跳出debug模式)
n /next 执行下一行
pp 列印变数的值
help 帮助
在(Pdb)后面输入这些命令去操作。
改变数据集之后需要修改的东西
1.把图片,标签和通过voc_annotation.py生成的ImageSets\Main都放在VOCdevkit\VOC2007文件夹下相应位置。
2.修改类别对应的文件,一般存放在model_data文件夹下,是个txt文件。
3.注意修改train.py中的冻结和解冻阶段的参数。
4.大致看一下train.py中的参数是否需要修改,其他就是参考前面训练时候的准备工作进行。
训练中的问题
问题:
训练几次都是开始不到3分钟就自动停止,几个报错都存在^C符号。
Epoch 1/450: 23% 6/26 [00:58<01:30, 4.51s/it, loss=10.3, lr=0.000125]^C
原因:
这种情况通常表示在训练过程中发生了一些错误或异常,导致程序被强制停止。在你提供的信息中,我看到了一个 “^C” 的符号,这通常表示程序被中断或强制终止。
可能的原因有很多,例如计算机资源不足,代码中存在错误或异常,数据集出现问题等等。下面是一些可能的解决方法:
-
检查代码是否存在错误或异常。可以查看程序的输出或日志文件,寻找异常或错误信息,或者使用调试工具来定位问题。
-
检查计算机资源是否充足。训练模型需要大量的计算资源,包括CPU、内存、显卡等。如果计算机资源不足,可能会导致程序运行缓慢或崩溃。可以尝试减少批处理大小、减小模型规模、使用更高效的算法等方式来减少计算资源的消耗。
-
检查数据集是否存在问题。数据集中可能存在缺失值、异常值、重复值等问题,这些问题可能会导致程序出现异常。可以对数据集进行预处理,例如填充缺失值、剔除异常值等。
-
尝试使用更稳定的训练方法。例如使用更小的学习率、更小的批处理大小、使用正则化等方式来提高模型的稳定性。
总之,这种情况可能是由于多种原因导致的,需要仔细检查程序和数据集,寻找问题所在,并尝试使用更稳定的训练方法来避免程序的崩溃。
解决:
train.py代码中的input_shape我设置的太大了,可能导致处理过程中计算资源不够,设置为[1120,1120],修改到[800,800]就好了。