使用的云GPU是恒源云,帮助文档很详细,后面如果有时间的话,我再写一篇云GPU怎么用,希望能帮助没有显卡想用云GPU的同学。接下来就进入正题吧
使用的是云GPU+pycharm专业版(社区版无法远程链接,如果是学生的话可以使用教育邮箱申请专业版,我申请时当天就回复我了)
首先,先贴上YOLOv7的代码链接(官方):
https://github.com/WongKinYiu/yolov7
不过访问github经常不稳定,深有体会。所以,也贴上网盘链接(虽然某度的速度也慢),权重文件是.zip格式,下载下来后改成.pt后缀就可以了。代码下载的时间大概是7.17。
权重链接链接:https://pan.baidu.com/s/18FyZKy1u4QOUnAH0nGkjrg
提取码:oxle
代码链接:https://pan.baidu.com/s/13wwiix8q75fHDZzEULc9yw
提取码:rto5
pycharm的解释器配置:

train.py的参数设置
其中weights cfg data hyp是需要设置的,batch-size过大可能会报错显卡显存不足,workers可以参考https://blog.csdn.net/flamebox/article/details/123011129

weights
权重文件就用上面的链接下载即可,上传到服务器上。我只使用了yolo7.pt,有兴趣可以试试别的权重文件,不过可能会用到train_aux.py。

cfg和hyp
yolov7模型文件使用代码里的yaml文件,不过需要修改nc为自己数据集的类别数。超参数也是默认文件。

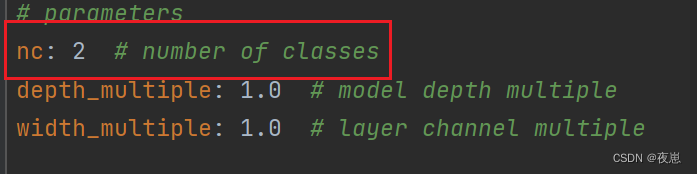
data
数据集文件,复制data文件下的coco.yaml一份命名为mydata.yaml。其中train_list.txt是自己数据集images/train的绝对路径,val_list.txt是images/val的绝对路径。这里我写的是相对路径,注意这个相对路径是相对于train.py文件的,不是相对于mydata.yaml文件。当然绝对路径是不会出错的,我是看见一个博主说相对路径报错了,我就试了一下,结果使用../train_list.txt出错,程序找不到文件。
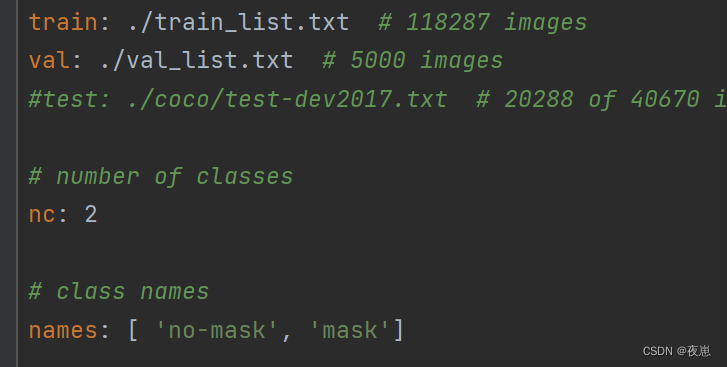
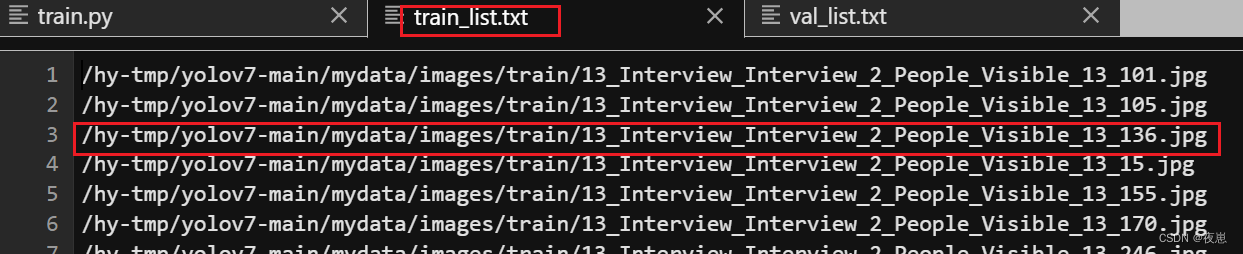

自动获取数据集train和val的images文件夹中图片的绝对路径,参考https://blog.csdn.net/qq_58355216/article/details/125677147
下面是生成train_list.txt的代码,如果要生成val_list.txt,将path和with open('./train_list.txt', 'w') as f:中的train换val
# From Mr. Dinosaur https://blog.csdn.net/qq_58355216/article/details/125677147
import os
def listdir(path, list_name):
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
else:
list_name.append(file_path)
list_name = []
path = '/hy-tmp/yolov7-main/mydata/images/train' # 训练集图像所在文件夹的绝对路径
listdir(path, list_name)
print(list_name)
with open('./train_list.txt', 'w') as f: # 在当前目录下生成train_list.txt文件
write = ''
for i in list_name:
write = write + str(i) + '\n'
f.write(write)不过mydata.yaml也可以设置成和YOLOv5中data参数的值一样,也是可以开始训练的。(所以这两种方法有什么区别?有知道的可以评论区告诉我)

训练
基本上需要设置的参数已经ok了,可以开始训练了。记得将修改后的项目与云端同步,就可以运行train.py文件了。

因为只是试试能不能跑,所以epoch设置为30。训练结果保存在runs/train/exp。
报错
1、使用恒源云GPU训练的时候,会出现(不知道是不是环境问题)
ImportError: libgthread-2.0.so.0: cannot open shared object file: No such file or directory在终端输入下面代码
apt-get install libglib2.0-dev 2、batch size设置过大出现RuntimeError: CUDA out of memory.
3、报错,参考https://blog.csdn.net/qq_36944952/article/details/124683408
AttributeError:module ‘distutils’ has no attribute 'version使用如下代码
pip uninstall setuptools
pip install setuptools==59.5.0 //需要比你之前的低 测试
测试文件的参数设置
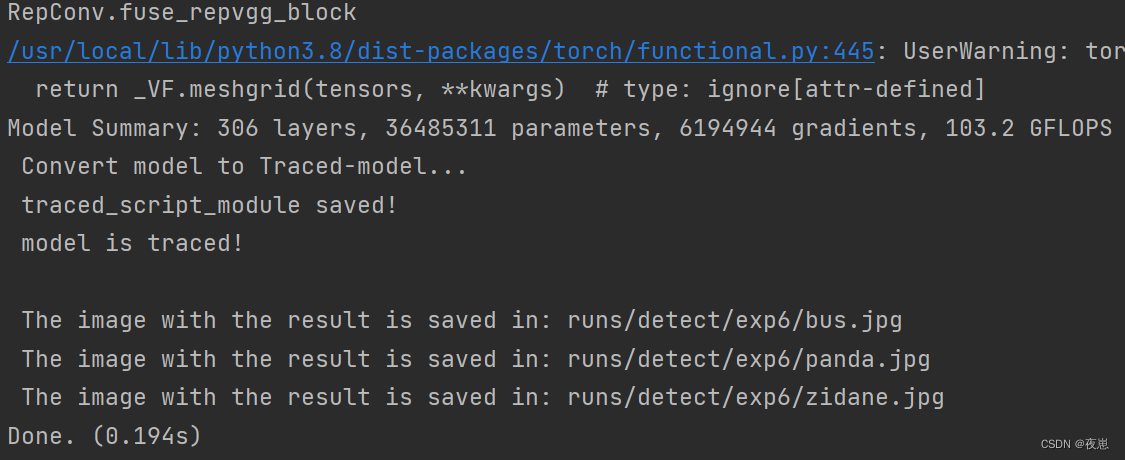
权重使用训练30次的best.pt文件,预测图片文件夹inference/images,注意路径写对。--view-img参数默认false,设置为true可以展示预测结果窗口(不过使用云端运行detect.py文件,展示会报错,找了很多教程都没解决(教程都说用mobaxterm),如果有知道解决方法的可以评论区告诉我)。project和name是结果保存路径runs/detect/exp。

结果


报错
1、忘了上传detect.py到服务器,导致一直运行失败。报下面的错
subprocess.CalledProcessError: Command ‘git tag’ returned non-zero exit status 128也有可能是参数设置出问题了,可以仔细检查一下
ps 以上只是简单地训练yolov7,如果文章有错误或者你有更好的见解请不吝赐教