第三方商业大型语言模型(LLM)提供商,如OpenAI的GPT4,通过简单的API调用使LLM的使用更加容易。然而,由于数据隐私和合规等各种原因,我们可能仍需要在企业内部部署或私有模型推理。
开源LLM的普及让我们私有化部署大语言模型称为可能,从而减少了对这些第三方提供商的依赖。
当我们将开源模型托管在本地或云端时,专用的计算能力成为一个关键考虑因素。虽然GPU实例可能是最佳选择,但成本也很容易一飞冲天, 再加上现在一卡难求, 想跑模型也变成了一个不简单的事情。
在这个指南中,我们将探讨如何使用CPU在本地Python中运行开源并经过轻量化的LLM模型,用于检索增强生成(Retrieval-augmented generation, 也称为Document Q&A)。而且我们将在这个项目中利用最新、高性能的Llama 2聊天模型。
Quantization(量化)简介
虽然LLM展现了出色的能力,但其运行所要求的计算和内存资源较高。为了应对这一问题,我们可以使用Quantization来压缩这些模型,以减少内存占用并加速推理计算过程,同时保持模型的性能和效果。
Quantization是一种将用于表示数字或值的位数减少的技术。在LLM的上下文中,它涉及通过将权重存储在较低精度的数据类型中来减少模型参数的精度。
由于它减小了模型大小,量化有助于在资源受限的设备上部署模型,例如仅有CPU但没有GPU的设备或嵌入式系统。
一种常见的方法是将模型权重从原始的16位浮点数值量化为较低精度的8位整数值。
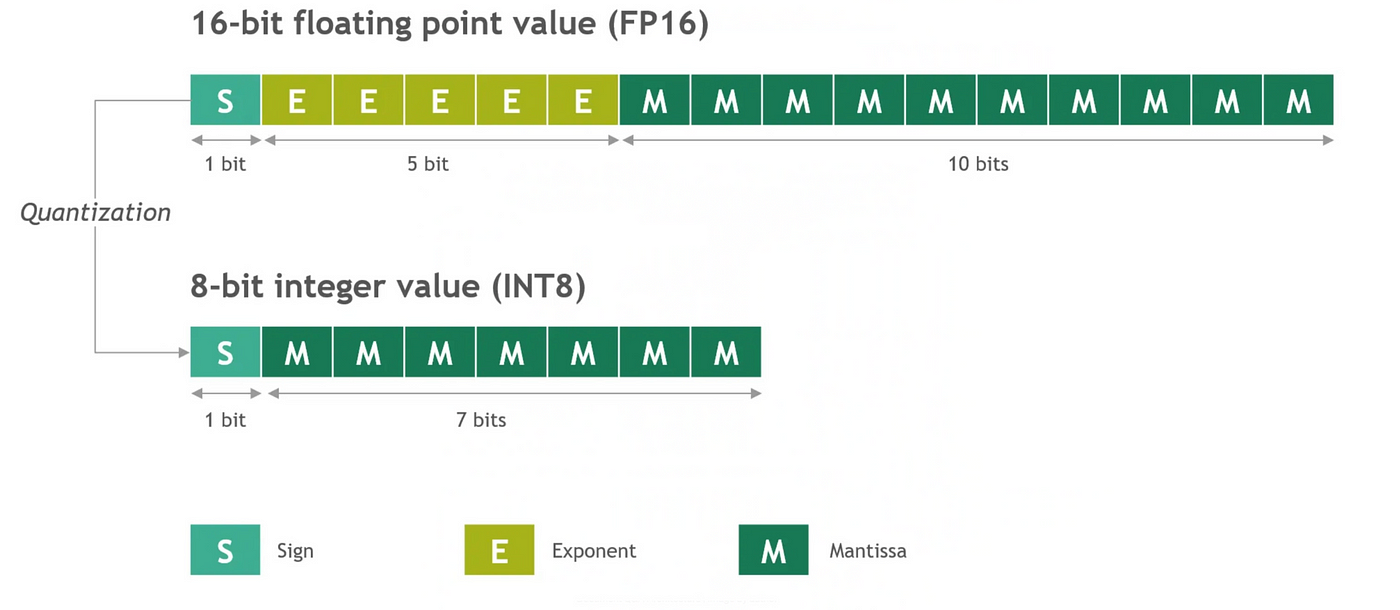
从16位浮点到8位整数的权重Quantization
工具和数据
下图展示了我们将在本项目中构建的Document Q&A应用程序的架构。
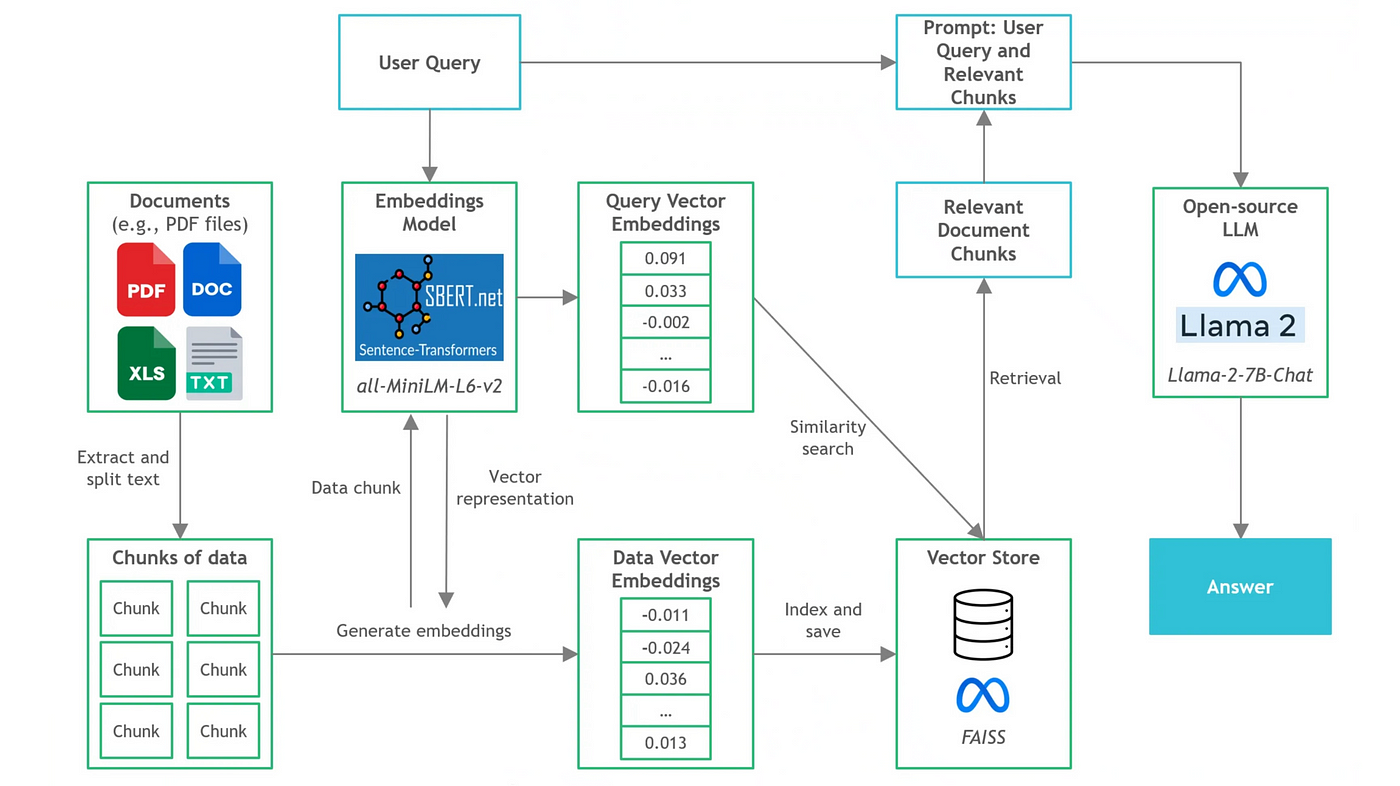
Document Q&A 架构
我们将在此项目中运行Document Q&A的文件是曼联足球俱乐部的2022年公开年度报告,共177页。
数据来源:Manchester United Plc (2022). 2022 Annual Report 2022 on Form 20-F. https://ir.manutd.com/~/media/Files/M/Manutd-IR/documents/manu-20f-2022-09-24.pdf (CC0: Public Domain, as SEC content is public domain and free to use)
此示例的运行环境配备了AMD Ryzen 5 5600X 6核CPU,16GB 内存(DDR4 3600)。虽然它还装了一块RTX 3060TI 8G显卡,但在本示例中不会使用它,因为我们将讨论如何仅使用CPU来运行模型。
一下是构建这个后端应用时将使用的工具:
LangChain:
LangChain是一个目前流行的用于开发LLM驱动的应用程序框架,它提供了各种集成接口和数据连接接口,允许我们链式编排不同的模块,以创建高级用例,如聊天机器人、数据分析和Document Q&A。
C Transformers:
C Transformers是提供一个Transformer模型的Python库,它使用GGML库C/C++绑定。说到这点,让我们首先了解一下GGML是什么。
ggml.ai团队开发的GGML库是一个为机器学习设计的Tensor Library,它可以在消费级硬件上高性能运行大模型。这是通过整数量化支持和内置优化算法实现的。
因此,LLM的GGML版本(以二进制格式量化过的模型)可以在CPU上高效地运行。鉴于我们在本项目中使用Python,我们将使用C Transformers库,其为GGML模型提供了Python绑定。
C Transformers支持一些常见的开源模型,包括目前流行的一些模型,如Llama、GPT4All-J、MPT和Falcon。
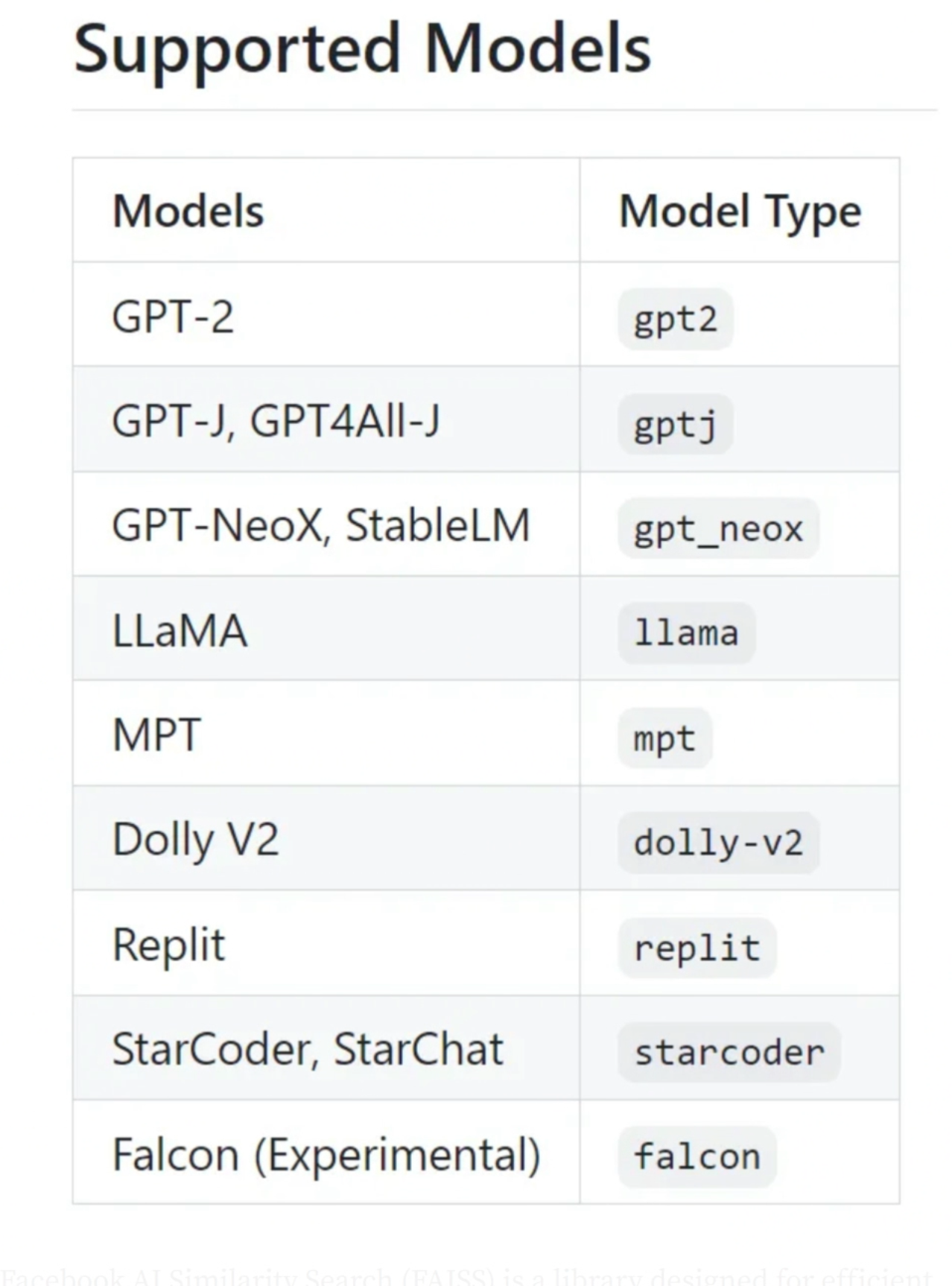
C Transformers支持的大语言模型
Sentence-Transformers嵌入模型
Sentence-transformers是一个Python库,提供了生成语句、文本和图像的嵌入(稠密向量表示 Dense Vector Representations)的简便方法。
它使用户能够生成100多种语言的关联语句,然后可以进行比较,找到具有相似含义的句子。
在这个项目中,我们将使用开源的all-MiniLM-L6-v2模型,因为它具有最佳的速度和出色的通用生成质量。
FAISS
Facebook AI Similarity Search (FAISS) 是一个专为高效的稠密向量(Dense Vector)相似性搜索和聚和类而设计的库。
给定一组输入,我们可以使用FAISS对它们进行索引,并利用其强大的语义搜索算法在索引内搜索最相似的向量。
虽然它在传统意义上不是一个完整的向量存储(像数据库管理系统),但它以优化的方式处理向量的存储,以实现高效的相邻搜索。
Poetry
在这个项目中,我们将使用Poetry来设置virtualenv并处理Python包管理,因为它易于使用且一致性较好。
之前使用过venv的话,我强烈推荐切换到Poetry,因为它可以使依赖管理更加高效和无缝。
开源LLM选择
开源LLM目前取得了巨大的进展,并且可以在Hugging Face的Open LLM排行榜上找到许多LLM。
基于以下考虑,我选择了最新的开源Llama-2–7B-Chat模型(GGML 8-bit)用于这个项目:
Model Type(Llama 2)
- C Transformers支持的开源模型。
- 根据Open LLM排行榜的排名(截至2023年7月),目前是多个指标中表现最好的模型。
- 相比早期的Llama模型,在之前的基准测试中表现出了巨大的改进。
- 在社区中被广泛提及和下载。
Model Size(7B)
- 考虑到我们执行的是Document Q&A任务,LLM主要用于对文档块进行相对简单的摘要。因此,7B模型大小符合我们的需求,因为在这个任务中我们技术上不需要过于庞大的模型(例如65B及以上)。
Find-tuned Version(Llama-2–7B-Chat)
- Llama-2–7B基本模型是用于文本补全的,因此缺乏在Document Q&A场景中实现最佳性能所需的微调。
- Llama-2–7B-Chat模型是我们目标场景的理想选择,因为它专为对话和问答而设计。
- 该模型包含了部分用于商业用途的授权。这是因为经过微调的Llama-2-Chat模型使用了公开可用的指令数据集和超过100万个人的注释。
Quantized Format(8-bit)
- 考虑到内存限制,8-bit GGML版本是合适的,因为它只需要9.6GB的内存大小。
- 8-bit格式的响应质量与16-bit相当。
- 原始的未量化16-bit模型需要约15GB的内存,这太接近16GB RAM限制了。
- 其他较小的量化格式(如4-bit和5-bit)也可用,但它们会以精度和响应质量为代价。
实现步骤
既然我们了解了各种组件,让我们逐步介绍如何构建Document Q&A应用程序。文中相关代码可以在此GitHub Repo中找到,所有依赖项都可以在requirements.txt文件中找到。
注意:由于已经有许多教程可供参考,我们不会展开讨论Document Q&A组件(例如文本分块、向量存储设置)的复杂性和细节。本文将专注于开源LLM和CPU推理方面。
第一步 — 处理数据并构建向量存储
在这一步骤中,将执行三个任务:
- 数据导入和将文本拆为文本块(Chunks)
- 加载嵌入模型(sentence-transformers)
- 对块进行索引,并将其存储在FAISS向量存储中。
# File: db_build.py
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader, DirectoryLoader
from langchain.embeddings import HuggingFaceEmbeddings
# Load PDF file from data path
loader = DirectoryLoader('data/',
glob="*.pdf",
loader_cls=PyPDFLoader)
documents = loader.load()
# Split text from PDF into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,
chunk_overlap=50)
texts = text_splitter.split_documents(documents)
# Load embeddings model
embeddings = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2',
model_kwargs={'device': 'cpu'})
# Build and persist FAISS vector store
vectorstore = FAISS.from_documents(texts, embeddings)
vectorstore.save_local('vectorstore/db_faiss')运行上述Python脚本后,向量存储将在本地目录中生成并保存为’vectorstore/db_faiss’,已准备好进行语义搜索和检索。
第二步 — 设置Prompt Template
考虑到我们使用的是Llama-2–7B-Chat模型,我们必须注意在这里使用的Prompt Template。
例如,OpenAI的GPT模型是为对话输入和消息输出而设计的。这意味着Prompt Template应该是类似于对话记录的格式(例如,分系统消息和用户消息)。
然而,在这里这样的模板就不适用用,因为我们的Llama 2模型没有专门针对这种类型的对话接口进行优化。相反,更适合使用经典的Prompt Template,如下所示:
# File: prompts.py
qa_template = """Use the following pieces of information to answer the user's question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Context: {context}
Question: {question}
Only return the helpful answer below and nothing else.
Helpful answer:
"""注意:较小的LLM,如7B模型,对格式要求较为敏感。例如,当我修改Prompt Template的空格和缩进时,输出会稍有不同。
第三步 — 下载Llama-2–7B-Chat GGML二进制文件
由于我们将在本地运行LLM,我们需要下载量化的Llama-2–7B-Chat模型的二进制文件。
我们可以访问TheBloke的Llama-2–7B-Chat GGML页面,该页面托管在Hugging Face上,然后下载名为llama-2–7b-chat.ggmlv3.q8_0.bin的GGML 8-bit量化文件。
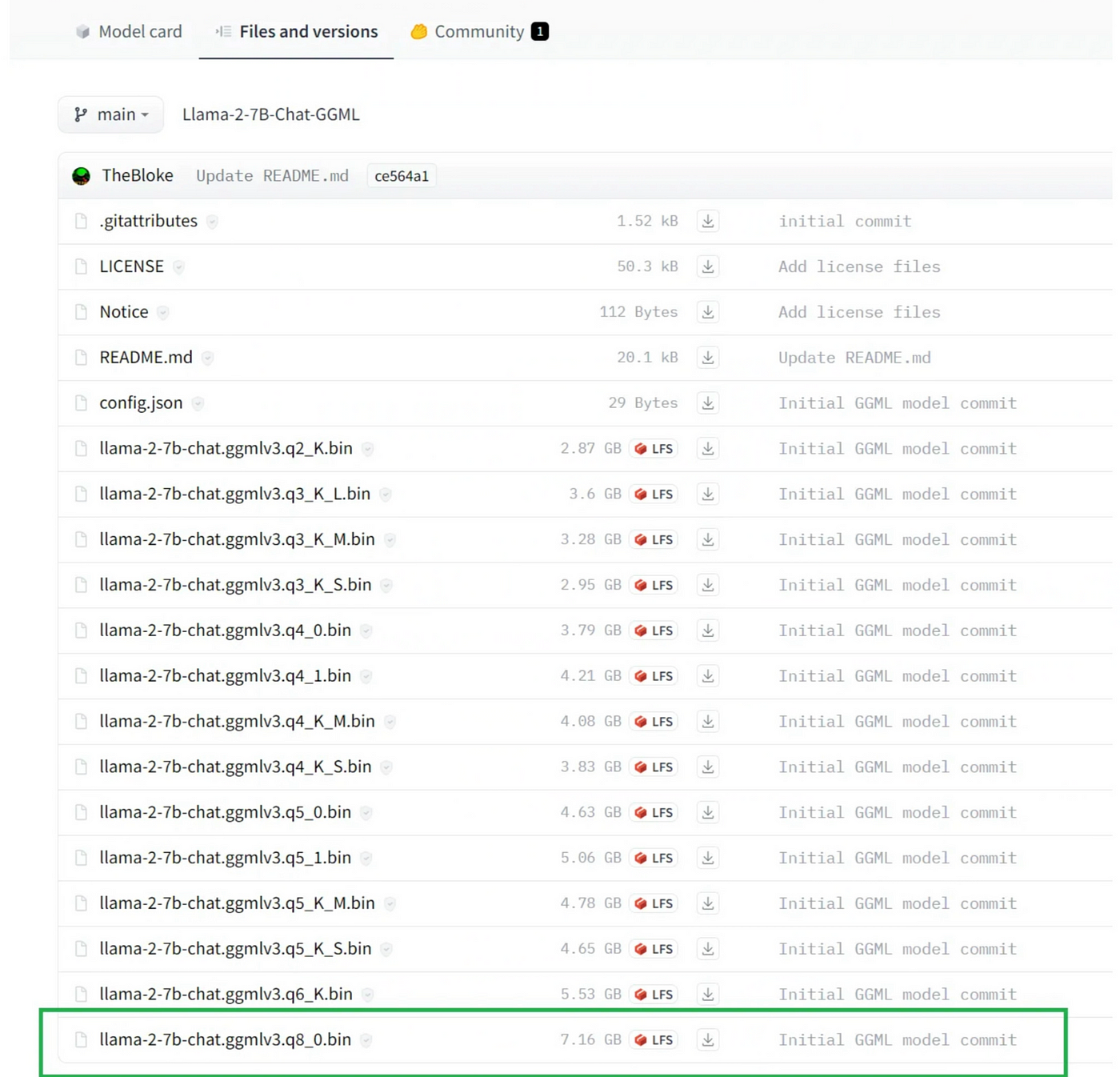
HuggingFace上的Llama-2–7B-Chat-GGML page的文件和版本信息
下载的8-bit量化模型的.bin文件可以保存在项目的某个子文件夹下,例如/models。
模型卡页面还显示了每种量化格式的更多信息和详细说明:
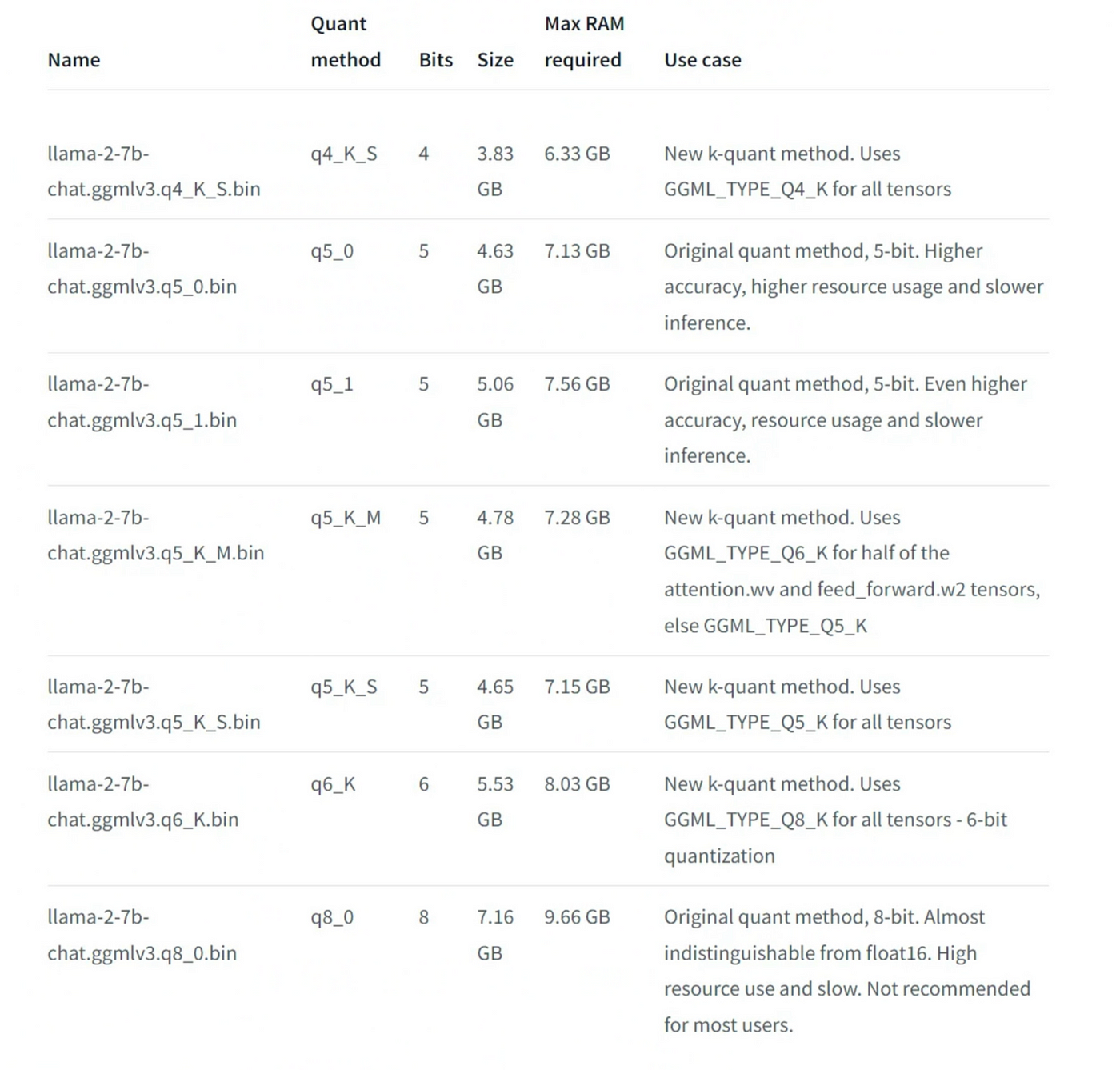
Different quantized formats with details
注意:要下载C Transformers支持的其他GGML量化模型,请访问HuggingFace上TheBloke的主页,搜索您想要的模型,并查找名称以“-GGML”结尾的链接。
第四步 — 设置LLM
为了使用我们下载的GGML模型,我们将用C Transformers和LangChain之间的集成。具体来说,我们将使用LangChain中的C Transformers LLM Wrapper,该Wrapper为GGML模型提供了统一的接口。
# File: llm.py
from langchain.llms import CTransformers
# Local CTransformers wrapper for Llama-2-7B-Chat
llm = CTransformers(model='models/llama-2-7b-chat.ggmlv3.q8_0.bin', # Location of downloaded GGML model
model_type='llama', # Model type Llama
config={'max_new_tokens': 256,
'temperature': 0.01})我们可以为LLM定义许多配置选项,例如最大Token数、top k、Temperature和Repetition penalty。
注意:我将Temperature设置为0.01而不是0,因为当Temperature恰好为零时,我得到了奇怪的返回(例如,一长串重复的字母E)。
第五步 — 构建和初始化RetrievalQA
有了Prompt Template和准备好的C Transformers LLM,我们编写三个函数来构建LangChain的RetrievalQA对象,以便我们能够执行Document Q&A任务。
# File: utils.py
from langchain import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
# Wrap prompt template in a PromptTemplate object
def set_qa_prompt():
prompt = PromptTemplate(template=qa_template,
input_variables=['context', 'question'])
return prompt
# Build RetrievalQA object
def build_retrieval_qa(llm, prompt, vectordb):
dbqa = RetrievalQA.from_chain_type(llm=llm,
chain_type='stuff',
retriever=vectordb.as_retriever(search_kwargs={'k':2}),
return_source_documents=True,
chain_type_kwargs={'prompt': prompt})
return dbqa
# Instantiate QA object
def setup_dbqa():
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={'device': 'cpu'})
vectordb = FAISS.load_local('vectorstore/db_faiss', embeddings)
qa_prompt = set_qa_prompt()
dbqa = build_retrieval_qa(llm, qa_prompt, vectordb)
return dbqa第六步 — 将组件合并到启动脚本中
接下来的步骤是将前面的各个组件合并到main.py脚本中。我们使用argparse模块,因为我们将从命令行传入用户查询到应用程序中。
考虑到我们将返回源文档,附加的代码将用于处理文档块,以获得更好的可视化显示。
为了评估CPU推理的速度,还使用了timeit模块。
# File: main.py
import argparse
import timeit
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('input', type=str)
args = parser.parse_args()
start = timeit.default_timer() # Start timer
# Setup QA object
dbqa = setup_dbqa()
# Parse input from argparse into QA object
response = dbqa({'query': args.input})
end = timeit.default_timer() # End timer
# Print document QA response
print(f'\nAnswer: {response["result"]}')
print('='*50) # Formatting separator
# Process source documents for better display
source_docs = response['source_documents']
for i, doc in enumerate(source_docs):
print(f'\nSource Document {i+1}\n')
print(f'Source Text: {doc.page_content}')
print(f'Document Name: {doc.metadata["source"]}')
print(f'Page Number: {doc.metadata["page"]}\n')
print('='* 50) # Formatting separator
# Display time taken for CPU inference
print(f"Time to retrieve response: {end - start}")第七步 — 运行示例查询
现在是时候对我们的应用程序进行测试了。在从项目目录加载virtualenv后,我们可以在命令行界面(CLI)中运行一个包含用户查询的命令。
例如,我们可以用以下命令询问阿迪达斯(曼彻斯特联全球技术赞助商)支付的最低保证金金额:
poetry run python main.py "How much is the minimum guarantee payable by adidas?"注意:如果我们没有使用Poetry,可以省略前缀的
poetry run。
结果
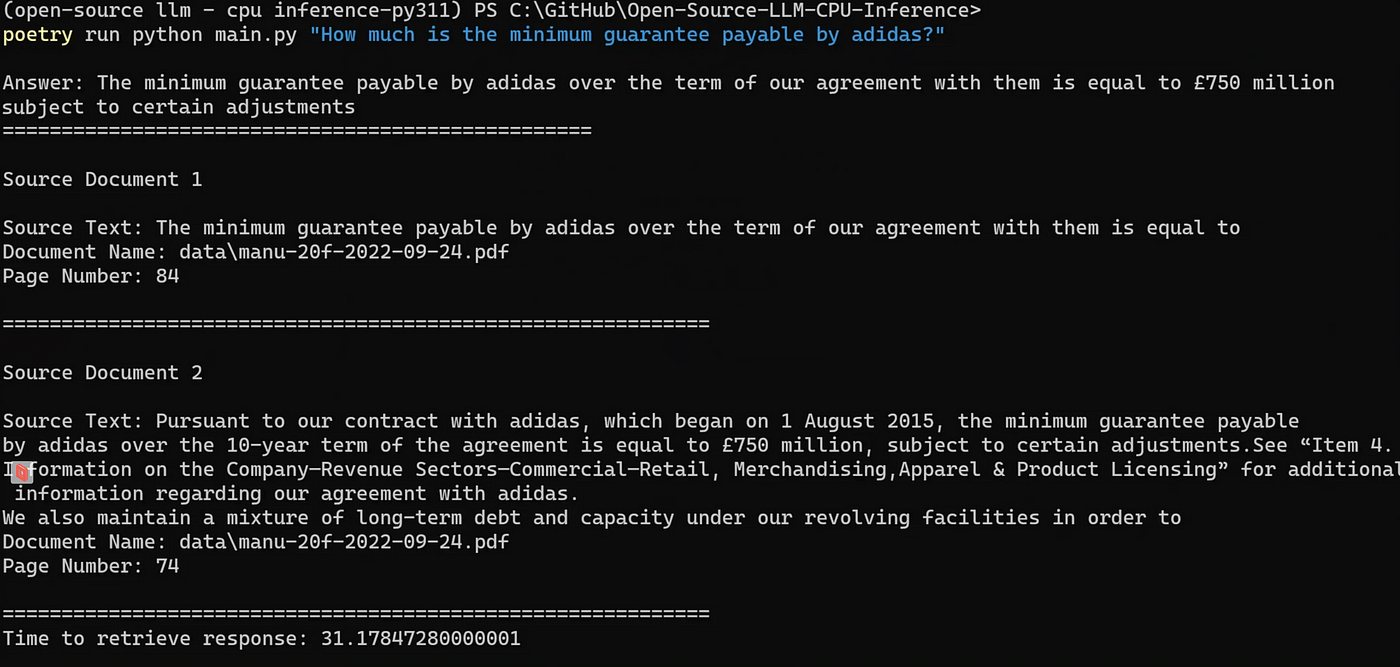
Output from user query passed into document Q&A application | Image by author
输出结果显示,我们成功地得到了对用户查询的正确响应(即7.5亿英镑),同时还显示了与查询语义相似的相关文档片段。
总共31秒的应用程序启动和生成响应时间相当不错,考虑到我们是在本地运行在AMD Ryzen 5600X上(虽然它是一款优秀的CPU,但目前并不是市场上最好的)。
考虑到在GPU上运行LLM推理(例如直接在HuggingFace上)也可能需要几十秒,这个结果更加令人印象深刻。
接下来的步骤
现在我们已经构建了一个在CPU推理上运行LLM的Document Q&A应用程序,我们可以采取许多激动人心的步骤来推进这个项目。
- 使用Streamlit构建前端聊天界面,特别是因为它最近有两个重要的公告:将Streamlit与LangChain集成,并推出Streamlit ChatUI,可以轻松构建强大的聊天机器人界面。
- 将应用程序Docker化并部署到云主机。虽然我们已经探索了本地推理,但应用程序很容易迁移到云端。我们还可以利用云上更强大的CPU实例来加速推理(例如,计算优化型的AWS EC2实例,如c5.4xlarge)。
- 尝试使用稍大的LLM,如Llama 13B Chat模型。由于我们已经使用过7B模型,评估稍大型模型的性能是一个不错的想法,因为理论上它应该更准确,同时仍然保持占用适量内存。
- 尝试较小的量化格式,如4位和5位(包括使用新的k-quant方法),以客观评估推理速度和响应质量的差异。
- 利用本地GPU加速推理。如果我们想在C Transformers模型上测试使用GPU,可以通过在GPU上运行一些模型来实现。这应该是有用的,因为目前只有Llama模型类型支持GPU。
- 评估使用vLLM,一个高吞吐量和内存高效的LLM推理和服务引擎。然而,使用vLLM需要使用GPU。
我将在未来的几周内致力于撰写关于上述想法的文章和项目,所以请继续关注更多富有洞察力的生成式AI内容!