一、原理

从文档处理角度来看,实现流程如下:
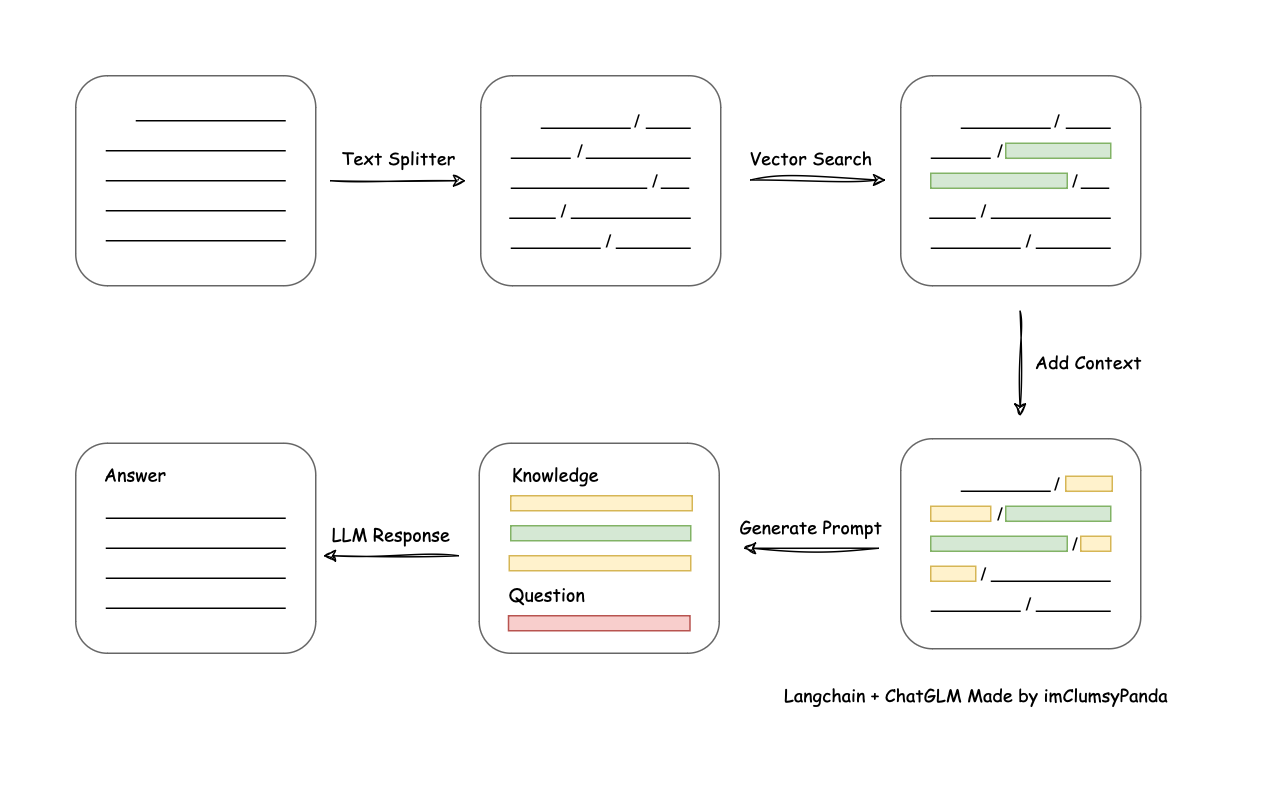
二、 环境准备
1. python package 包
!pip install -U langchain unstructured nltk sentence_transformers faiss-gpu2. nltk的punkt手动安装
安装nltk的punkt模块(因为下载速度很慢,所以这里我们手动下载)
-
先在root目录下,建一个文件夹:/root/nltk_data/tokenizers
-
到这个网址:http://www.nltk.org/nltk_data/,找到punkt的包
-
下载包:wget https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/packages/tokenizers/punkt.zip
-
解压包:unzip punkt.zip
3、下载并部署embedding模型
先进到数据盘 cd /root/autodl-tmp
执行:git lfs install
执行:git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
如果有大文件下载不下来,就需要用wget 下载
wget https://huggingface.co/GanymedeNil/text2vec-large-chinese/resolve/main/pytorch_model.bin
wget https://huggingface.co/GanymedeNil/text2vec-large-chinese/resolve/main/model.safetensors
三、设置知识库
1. 导入相关包
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS2. 知识库其实本质上就是一段文本。这里我们使用unstructured这个包,把带格式的文本,读取为无格式的纯文本
knowledge.txt
大美有两个儿子,一个是小白,另一个是小黑。
小白的父亲是张三。
小黑的父亲是张四。
filepath="/root/autodl-tmp/knowledge.txt"
loader=UnstructuredFileLoader(filepath)
docs=loader.load()
#打印一下看看,返回的是一个列表,列表中的元素是Document类型
print(docs)3. 对上面读取的文档进行chunk。chunk的意义在于,可以把长文本拆分成小段,以便搜索召回
chunk-size是文本最大的字符数。chunk-overlap是前后两个chunk的重叠部分最大字数。
text_splitter=RecursiveCharacterTextSplitter(chunk_size=20,chunk_overlap=10)
docs=text_splitter.split_documents(docs)4、使用text2vec-large-chinese模型,对上面chunk后的doc进行embedding。然后使用FAISS存储到向量数据库
import os
embeddings=HuggingFaceEmbeddings(model_name="/root/autodl-tmp/text2vec-large-chinese", model_kwargs={'device': 'cuda'})
#如果之前没有本地的faiss仓库,就把doc读取到向量库后,再把向量库保存到本地
if os.path.exists("/root/autodl-tmp/my_faiss_store.faiss")==False:
vector_store=FAISS.from_documents(docs,embeddings)
vector_store.save_local("/root/autodl-tmp/my_faiss_store.faiss")
#如果本地已经有faiss仓库了,说明之前已经保存过了,就直接读取
else:
vector_store=FAISS.load_local("/root/autodl-tmp/my_faiss_store.faiss",embeddings=embeddings)
#注意!!!!
#如果修改了知识库(knowledge.txt)里的内容
#则需要把原来的 my_faiss_store.faiss 删除后,重新生成向量库四、加载模型
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
#先做tokenizer
tokenizer = AutoTokenizer.from_pretrained('/root/autodl-tmp/Llama2-chat-13B-Chinese-50W',trust_remote_code=True)
#加载本地基础模型
#low_cpu_mem_usage=True,
#load_in_8bit="load_in_8bit",
base_model = AutoModelForCausalLM.from_pretrained(
"/root/autodl-tmp/Llama2-chat-13B-Chinese-50W",
torch_dtype=torch.float16,
device_map='auto',
trust_remote_code=True
)
model=base_model.eval()五、知识库的使用 和 构造prompt_template
1、通过用户问句,到向量库中,匹配相似度高的【知识】
query="小白的父亲是谁?"
docs=vector_store.similarity_search(query)#计算相似度,并把相似度高的chunk放在前面
context=[doc.page_content for doc in docs]#提取chunk的文本内容
print(context)2、编写prompt_template;把查找到的【知识】和【用户的问题】都输入到prompt_template中
my_input="\n".join(context)
prompt=f"已知:\n{my_input}\n请回答:{query}"
print(prompt)六、把prompt输入模型进行预测
inputs = tokenizer([f"Human:{prompt}\nAssistant:"], return_tensors="pt")
input_ids = inputs["input_ids"].to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":1024,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3
}
generate_ids = model.generate(**generate_input)
new_tokens = tokenizer.decode(generate_ids[0], skip_special_tokens=True)
print("new_tokens",new_tokens)
其它
1. DirectoryLoader
from langchain.document_loaders import TextLoader, DirectoryLoader
loader = DirectoryLoader('../documents')
raw_documents = loader.load()2. TensorflowHubEmbeddings
如果替换tensorflowhub中的Embedding模型,可以。
from langchain.embeddings import TensorflowHubEmbeddings
url = "https://tfhub.dev/google/universal-sentence-encoder/4"
s_embedding = TensorflowHubEmbeddings(model_url=url)参考