系列文章目录
文章目录
前言
【 第8章 Spark MLlib 】
8.1 Spark MLlib简介
8.1.1 什么是机器学习
- 机器学习可以看做是一门人工智能的科学,该领域的主要研究对象是人工智能。
- 机器学习利用数据或以往的经验,以此优化计算机程序的性能标准。
- 机器学习强调三个关键词:算法、经验、性能
8.1.2 基于大数据的机器学习
- 机器学习算法涉及大量迭代计算
- 基于磁盘的MapReduce不适合进行大量迭代计算
- 基于内存的Spark比较适合进行大量迭代计算
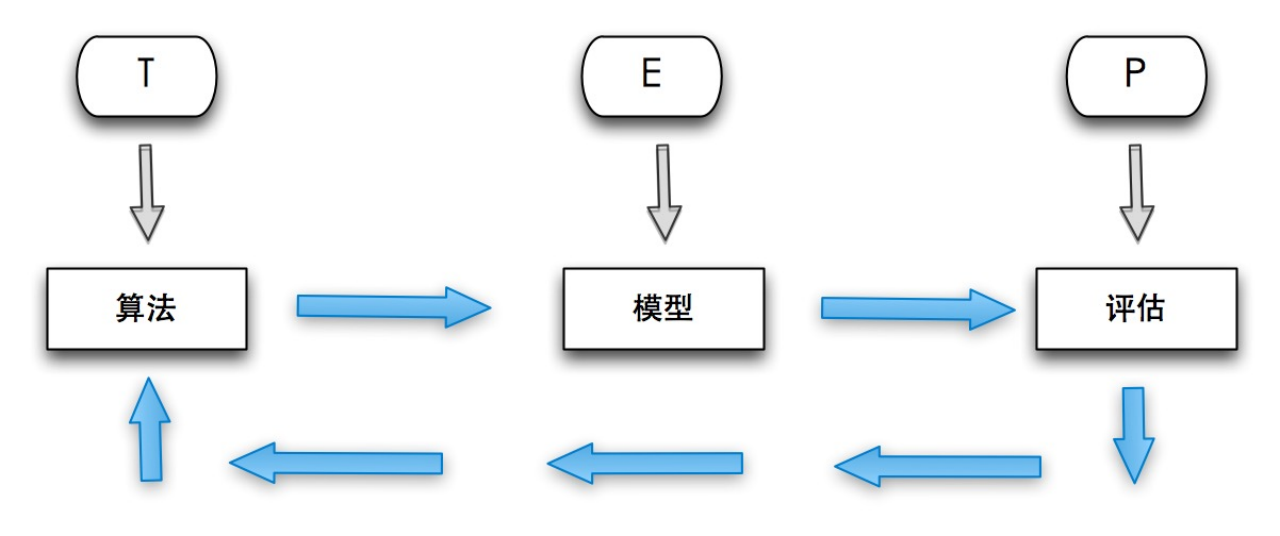
8.1.3 Spark 机器学习库MLLib
- Spark提供了一个基于海量数据的机器学习库,它提供了常用机器学习算法的分布式实现
- 开发者只需要有 Spark 基础并且了解机器学习算法的原理,以及方法相关参数的含义,就可以轻松的通过调用相应的 API 来实现基于海量数据的机器学习过程
- pyspark的即席查询也是一个关键。算法工程师可以边写代码边运行,边看结果
- 需要注意的是,MLlib中只包含能够在集群上运行良好的并行算法,这一点很重要
- 有些经典的机器学习算法没有包含在其中,就是因为它们不能并行执行
- 相反地,一些较新的研究得出的算法因为适用于集群,也被包含在MLlib中,例如分布式随机森林算法、最小交替二乘算法。这样的选择使得MLlib中的每一个算法都适用于大规模数据集
- 如果是小规模数据集上训练各机器学习模型,最好还是在各个节点上使用单节点的机器学习算法库(比如Weka)
- MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作
- MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的流水线(Pipeline)API,具体如下:
- 算法工具:常用的学习算法,如分类、回归、聚类和协同过滤;
- 特征化工具:特征提取、转化、降维和选择工具;
- 流水线(Pipeline):用于构建、评估和调整机器学习工作流的工具;
- 持久性:保存和加载算法、模型和管道;
- 实用工具:线性代数、统计、数据处理等工具。
- Spark 机器学习库从1.2 版本以后被分为两个包:
- spark.mllib
- 包含基于RDD的原始算法API
- Spark MLlib 历史比较长,在1.0 以前的版本即已经包含了,提供的算法实现都是基于原始的 RDD
- spark.ml
- 提供了基于DataFrames 高层次的API,可以用来构建机器学习工作流(PipeLine)
- ML Pipeline 弥补了原始 MLlib 库的不足,向用户提供了一个基于 DataFrame 的机器学习工作流式 API 套件
- spark.mllib
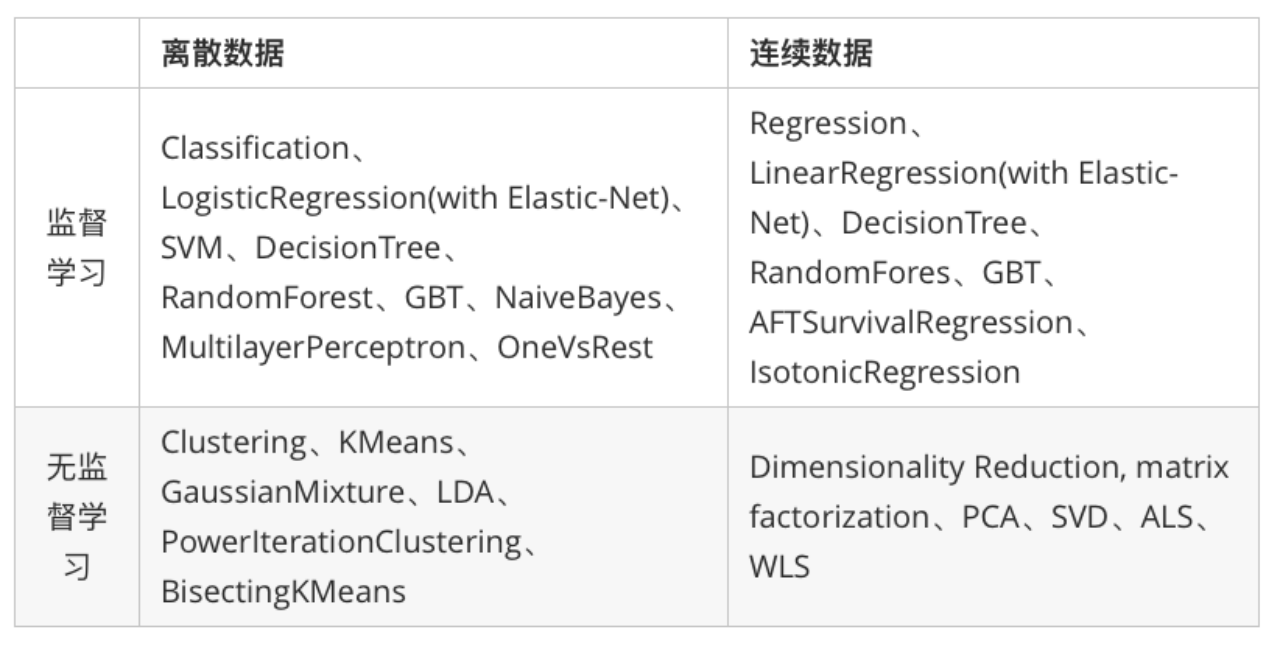
- MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤
8.2 机器学习工作流
8.2.1 机器学习流水线概念
在介绍流水线之前,先来了解几个重要概念:
- DataFrame
- 使用Spark SQL中的DataFrame作为数据集,它可以容纳各种数据类型。
- 较之RDD,DataFrame包含了schema 信息,更类似传统数据库中的二维表格。
- 它被ML Pipeline用来存储源数据。例如,DataFrame中的列可以是存储的文本、特征向量、真实标签和预测的标签等
- Transformer:
- 翻译成转换器,是一种可以将一个DataFrame转换为另一个DataFrame的算法。
- 比如一个模型就是一个 Transformer。
- 它可以把一个不包含预测标签的测试数据集 DataFrame 打上标签,转化成另一个包含预测标签的 DataFrame。
- 技术上,Transformer实现了一个方法transform(),它通过附加一个或多个列将一个DataFrame转换为另一个DataFrame
- Estimator:
- 翻译成估计器或评估器,它是学习算法或在训练数据上的训练方法的概念抽象。
- 在 Pipeline 里通常是被用来操作 DataFrame 数据并生成一个 Transformer。
- 从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。
- 比如,一个随机森林算法就是一个 Estimator,它可以调用fit(),通过训练特征数据而得到一个随机森林模型。
- Parameter:
- Parameter 被用来设置 Transformer 或者 Estimator 的参数。
- 现在,所有转换器和估计器可共享用于指定参数的公共API。ParamMap是一组(参数,值)对
- PipeLine:
- 翻译为流水线或者管道。
- 流水线将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出
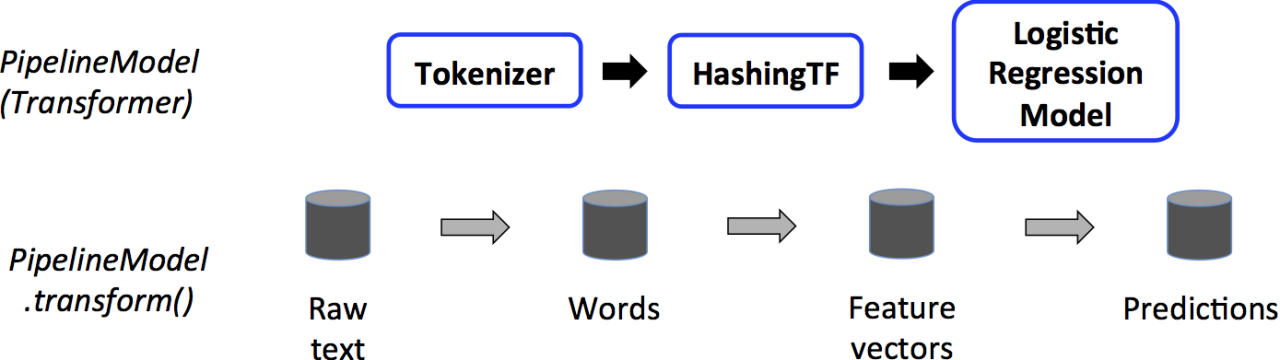
8.2.2 构建一个机器学习流水线
-
要构建一个 Pipeline流水线,首先需要定义 Pipeline 中的各个流水线阶段PipelineStage(包括转换器和评估器),比如指标提取和转换模型训练等。
-
有了这些处理特定问题的转换器和评估器,就可以按照具体的处理逻辑有序地组织PipelineStages 并创建一个Pipeline
-
pipeline = Pipeline(stages=[stage1,stage2,stage3]) -
然后就可以把训练数据集作为输入参数,调用 Pipeline 实例的 fit 方法来开始以流的方式来处理源训练数据。
-
这个调用会返回一个 PipelineModel 类实例,进而被用来预测测试数据的标签
-
流水线的各个阶段按顺序运行,输入的DataFrame在它通过每个阶段时被转换

-
值得注意的是,流水线本身也可以看做是一个估计器。
-
在流水线的fit()方法运行之后,它产生一个PipelineModel,它是一个Transformer。
-
这个管道模型将在测试数据的时候使用。 下图说明了这种用法。