数据结构-栈(C语言版)
目录
1.栈的基础知识
简介:
栈是后进先出,逻辑上相当于一个桶,只能从顶端操作。
1.入栈,出栈的排列组合
情景一:已知入栈序列,求出栈序列的可能。
方法:先看出栈序列最左边,之后按个排序,拿着这个出栈的数,取入栈序列找它前面的可能,之后再回到选择取对比。
例如:a,b,c,d,e,f依次进栈,求出栈的可能不是哪个:一般为选择题,从选项中的出栈序列最左边开始找,如fedcba,若f先出栈,则f后面的次序一定是...e..d..c..b..a,发现符合,再看第二个fe,e出栈后,后面出栈的可能为d..c..b..a..f符合,再看第三个fed,d出栈后,可能出栈的有:c..b..a..,符合,直到最后都符合。所以这个出栈对。又例如:出栈序列cabdef,先c,c先出栈,后面可能..b..a,结果选项出栈为..a..b,次序反了,所以这个就不是,
情景二:Catalan函数(计算不同出栈的总数)
n个元素依次进栈,可以得到多少种不同的出栈序列?
Catalan函数公式:,别问为啥,问就是,记着就行了。代入,即可得到结果,
2.栈的基本操作
简介:按照不同存储方式,分为顺序存储和链式存储。
1.顺序存储
简介:顺序存储即定义一个结构体,里面有一个存储数据的数组,和一个记录栈顶的变量top。
如图:

(1)顺序栈-定义:
#define MaxSize 50 //最大容量
typedef struct
{
int data[MaxSize];//存储栈数据的一维数组
int top; //表示栈顶的变量top
}SqStack;(2)顺序栈-栈空
简介:要看清楚栈空时,top指向哪里,不同的指向,进栈出栈的操作就不一样,不过,一般画图,就明白了。
初始化:InitStack(&s) 即栈空
//初始化
//因为想要改变结构体内的值,实参形参都变化,所以传栈s的地址进来,栈*S指针接收
void InitStack(SqStack *s)
{
s->top=-1;
}
要看清top栈空的条件时什么,再进行相应的初始化。
初始化之后,便是验证是否栈空StackEmpty(s)
//判断是否栈空
void StackEmpty(SqStack s)
{
if(s.top== -1)
return 1;
}(1)s.top==-1,表示栈空
此时,我的数组要想赋值,肯定需要top先加1,定位到数组第一个元素,随后再赋值。因此当top==-1表示空时,top先++,随后再赋值,top始终指向栈顶位置
(2)s.top==0,表示栈空

此时,我的数组要想赋值,top已经指向数组第一个位置,可以直接赋值,之后再top++。因此当top==0表示空时,先赋值,再top++,top始终指向栈顶位置的下一个位置
(3)顺序栈-入栈
入栈即从外边,进桶里,此时要考虑上溢情况,避免数组容量不够。上溢可通过一定的策略优化,减少上溢的情况
代码如下:SqPush(&s,x);
//入栈
void SqPush(SqStack *s,int x)
{
if(s->top == MaxSize-1)
{
exit(-1);//栈满,退出
}
s->top++;
s->data[s->top]=x;
} (4)顺序栈-出栈以及取值
出栈则是从顶部出取,只可操作一端。出栈时考虑下溢,下溢时逻辑错误,不取决于策略的优化
代码如下:
//出栈
void Sqpush(SqStack *s,int *n)
{
if(s->top==-1)
exit(-1);
*n=s->data[s->top];
s->top--;
} (5)共享栈
简介:当顺序栈一次性申请的数组空间太大时,会造成空间浪费,最后还有好多空间没有用。因此对于两个类型相同的栈,我们可以让他们在同一个栈中,进行存取。分别从左右两端进行入栈,中间为栈底。
共享栈的好处:节省存储空间,降低发生上溢的可能
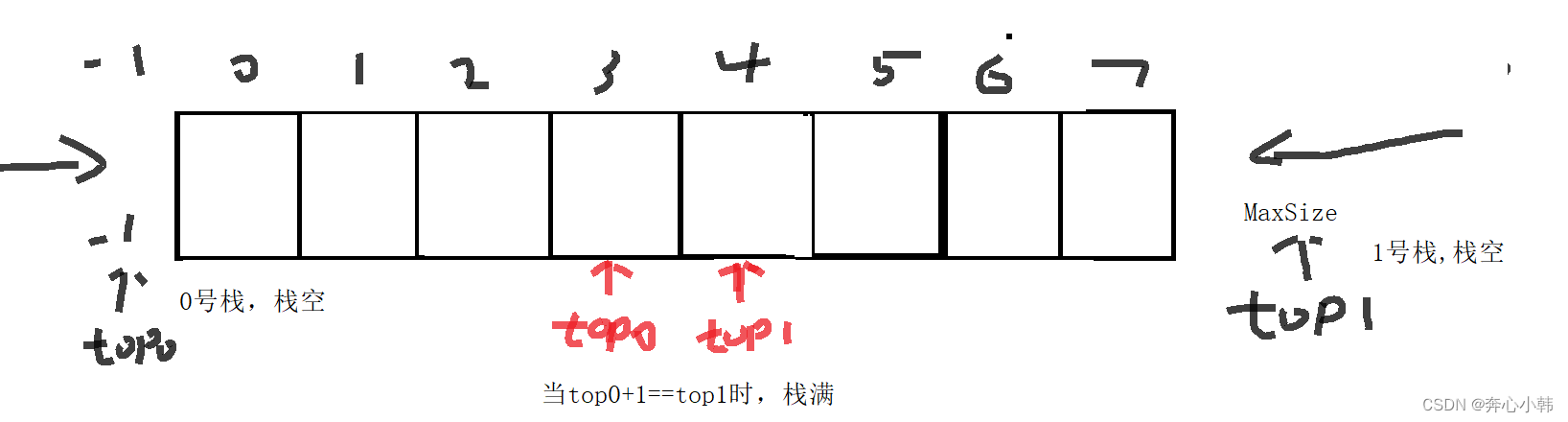
栈空:top0==-1,top1==MaxSize
栈满:他俩碰头了,top0+1=top1
共享栈了解思想即可。
2.链式存储
简介:采取单链表形式实现的栈,为栈的链式存储,只不过这里的单链表,只能从表头进行插入和删除。
采用链栈的优点:便于多个栈共享存储空间,提高效率,不存在上溢情况,插入删除更方便。
特殊约定:采用单链表实现的栈,默认没有头节点,头指针直接指向第一个实际结点,都在表头进行操作。
(1)链栈-定义:
//栈的链式存储
typedef struct StackNode
{
int data;
struct StackNode *next;
}StackNode; (2)链栈-入栈
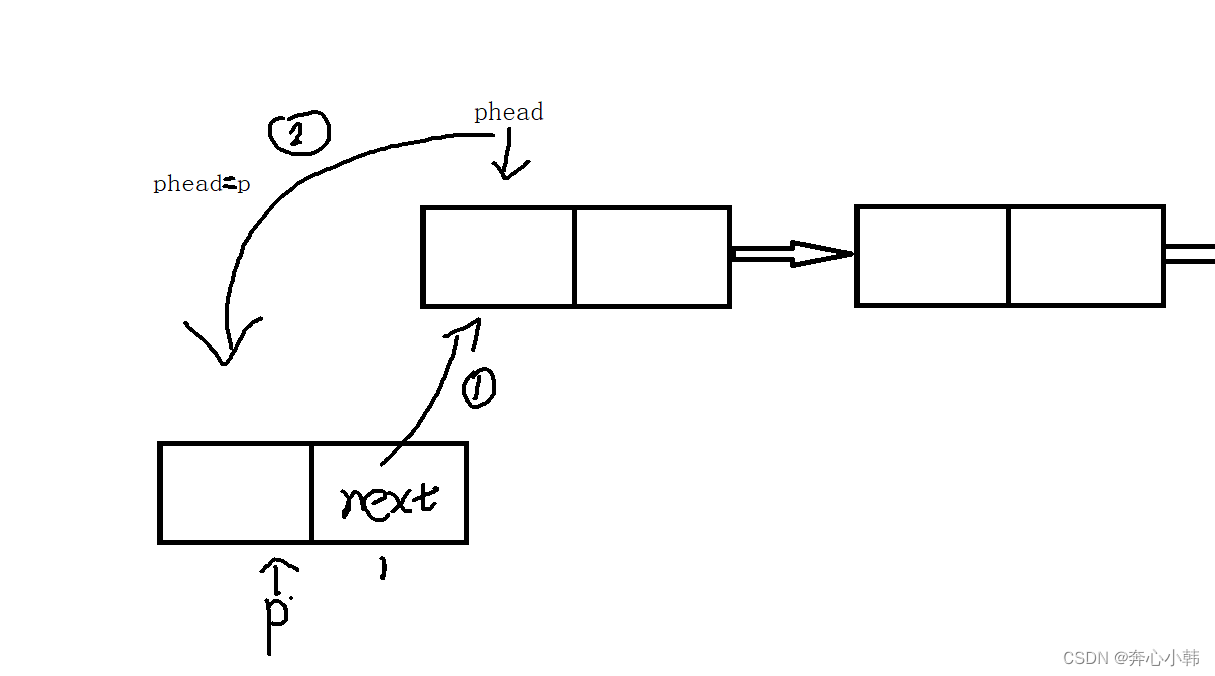
思路:插入结点,插入结点先主动,P结点的指针与,存储原第一个结点的地址,即头节点所存的地址。之后更新头指针,把p结点地址赋值给头指针phead
代码如下:
//入栈
StackNode* StackNodepush(StackNode *phead,int x)
{
StackNode* p=(StackNode*)malloc(sizeof(StackNode));
p->data=x;
p->next=NULL;
if(phead==NULL)
{
phead=p;
}
else
{
p->next=phead;
phead=p;
}
return phead;
}(3)链栈-出栈
出栈,即用一个变量接收出栈的值,随后再定义一个临时指针,指向需要出的结点,用来最后释放掉,之后移动头指针,更新头指针为第二个结点地址,最后释放掉出栈结点即可。
代码如下:
//出栈
StackNode* StackNodepop(StackNode* phead,int x)
{ //单链表可能为空,所以需要先判断非法情况
if(phead==NULL)
return NULL;
//取第一结点的值
x=phead->data;
//另外赋值第一个结点 ,为了后面找到它并释放
StackNode *p=phead;
//直接更新头节点
phead=p->next;
free(p);
return phead;
} (4)链栈-打印栈
void StackPrint(StackNode* phead)
{
StackNode* pos =phead;
while(pos!=NULL)
{
printf("%d->",pos->data);
pos = pos->next;
}
printf("NULL\n");
} 总代码如下:(可运行)
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
//顺序栈
#define MaxSize 50
typedef struct
{
int data[MaxSize];
int top;
}SqStack;
//初始化
void InitStack(SqStack *s)
{
s->top=-1;
}
//判断是否栈空
int StackEmpty(SqStack s)
{
if(s.top== -1)
return 1;
}
//入栈
void SqPush(SqStack *s,int x)
{
if(s->top == MaxSize-1)
{
exit(-1);//栈满,退出
}
s->top++;
s->data[s->top]=x;
}
//出栈
void Sqpush(SqStack *s,int *n)
{
if(s->top==-1)
exit(-1);
*n=s->data[s->top];
s->top--;
}
//栈的链式存储
typedef struct StackNode
{
int data;
struct StackNode *next;
}StackNode;
//入栈
StackNode* StackNodepush(StackNode *phead,int x)
{
StackNode* p=(StackNode*)malloc(sizeof(StackNode));
p->data=x;
p->next=NULL;
if(phead==NULL)
{
phead=p;
}
else
{
p->next=phead;
phead=p;
}
return phead;
}
//出栈
StackNode* StackNodepop(StackNode* phead,int x)
{ //单链表可能为空,所以需要先判断非法情况
if(phead==NULL)
return NULL;
//取第一结点的值
x=phead->data;
//另外赋值第一个结点 ,为了后面找到它并释放
StackNode *p=phead;
//直接更新头节点
phead=p->next;
free(p);
return phead;
}
void StackPrint(StackNode* phead)
{
StackNode* pos =phead;
while(pos!=NULL)
{
printf("%d->",pos->data);
pos = pos->next;
}
printf("NULL\n");
}
int main()
{
StackNode *phead;
phead=StackNodepush(phead,0);
phead=StackNodepush(phead,1);
phead=StackNodepush(phead,2);
phead=StackNodepush(phead,3);
StackPrint(phead);
return 0;
}