在机器学习中,所有的机器学习算法都或多或少的依赖于对目标函数最大化或者最小化的过程,我们常常把最小化的函数称为损失函数,它主要用于衡量机器学习模型的预测能力。在寻找最小值的过程中,我们最常用的方法是梯度下降法。
虽然损失函数可以让我们看到模型的优劣,并且为我们提供了优化的方向,但是我们必须知道没有任何一种损失函数适用于所有的模型。损失函数的选取依赖于参数的数量、异常值、机器学习算法、梯度下降的效率、导数求取的难易和预测的置信度等若干方面。这篇文章将介绍各种不同的损失函数,并帮助我们理解每种损失函数的优劣和适用范围。
由于机器学习的任务不同,损失函数一般分为分类和回归两类,回归会预测给出一个数值结果而分类则会给出一个标签。这篇文章主要集中于回归损失函数的分析。本文中所有的代码和图片都可以在这个地方找到!
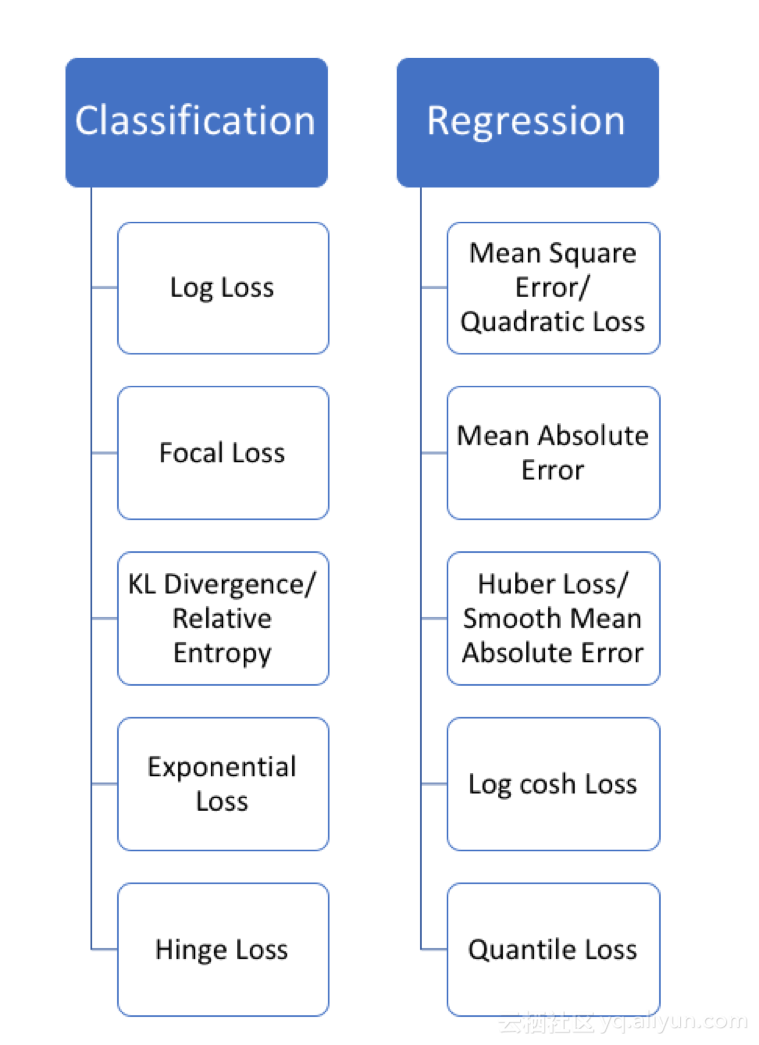
回归函数预测数量,分类函数预测标签
回归损失函数
1.均方误差、平方损失——L2损失:
均方误差(MSE)是回归损失函数中最常用的误差,它是预测值与目标值之间差值的平方和,其公式如下所示:
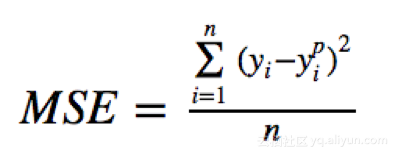
下图是均方根误差值的曲线分布,其中最小值为预测值为目标值的位置。我们可以看到随着误差的增加损失函数增加的更为迅猛。
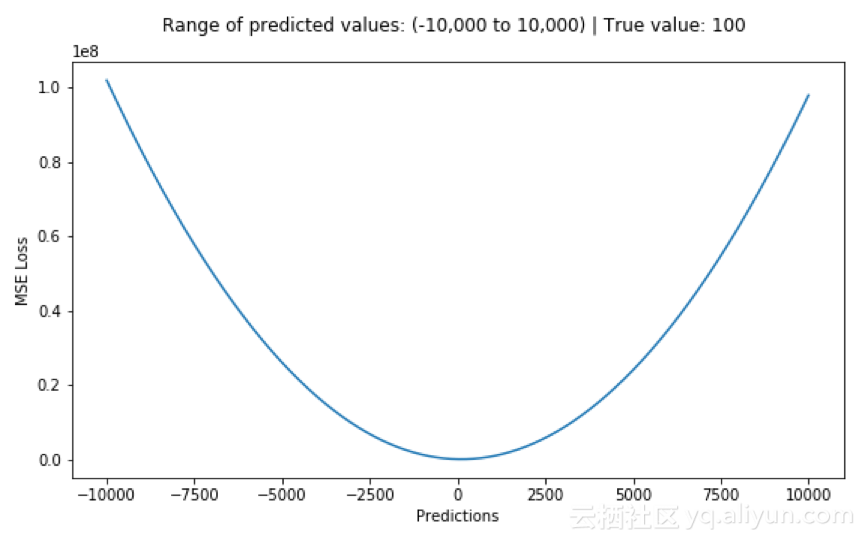
MSE损失(Y轴)与预测(X轴)的关系图
2.平均绝对误差——L1损失函数:
平均绝对误差(MAE)是另一种常用的回归损失函数,它是目标值与预测值之差绝对值的和,表示了预测值的平均误差幅度,而不需要考虑误差的方向(注:平均偏差误差MBE则是考虑的方向的误差,是残差的和),范围是0到∞,其公式如下所示: