《Facial Landmark Detection with Tweaked Convolutional Neural Networks》
思路:对CNN提取的特征进行聚类,将各簇对应的样本进行分析,最后发现同一簇表现出“相同属性”(姿态,微笑,性别)的人脸。对此,设计了K个FC5和K个FC6层,用以对不同“面部属性”的人脸进行关键点检测。
Vanilla CNN网络结构:

输入是一张40*40*3的彩色照片,经过4个卷积层(CL1…CL4),每个卷积层后利用池化层(stride=2)抽取特征,再进入全连接层FC5,最后进入FC6输出2*m(m个标记点,m=5)个值:P=(p1,p2…p5)=(x1,y1,x2,y2……x5,y5)。
其中红色弧标记的地方就是TCNN进行改进的地方。
损失函数使用双目距离进行标准化:
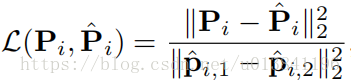
1.The Tweaked CNN model:
为了提高精度,在最后的网络层次中进行了微调:每一层仅使用类似的中间层网络特征代表的图像来进行训练;因为相似的特征代表相似的特征点,这被认为可以让网络能在特定的姿势和表情中有针对性一点。
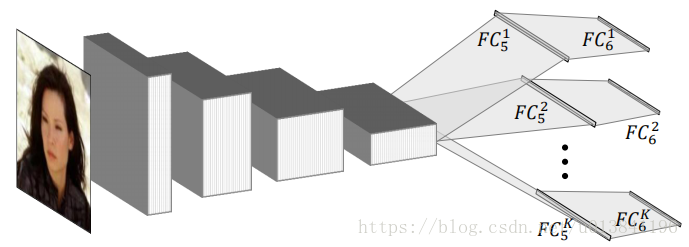
在全连接层之前,网络结构和Vanilla CNN是一致的。在训练完成之后,便从前面训练的结果中抽离出特征,将其作为FC5的输入。微调最后一层FC5,使用具有相似特征的图片训练对应的回归器。
特征使用GMM聚合成K个类,并显示每一个聚类中心(相同类别脸的平均)。接下来微调权重,对于每一个聚类,只使用其图像集进行微调。这里还是用了early stopping来微调每一个子网;它的作用就是,在50个周期里,如果验证损失没有提升的话,就停止微调该簇。
2、Alignment-sensitive data augmentation:
当数据集不同的时候,一般为防止过拟合,都会通过增加数据量来减少误差。最流行的方法包括有过采样,实质上就是通过裁剪不同偏移量的输入图片来增加训练数据,有的也通过镜像图片获得。但是如果应用到这里的话却不能成功,因为每个调整好的微调网络是在来自一个相同的簇的代表上进行训练的。过采样和镜像都会引入不对其的图片到每一个簇中,会增加标记点位置的变异性从而破坏了我们微调的目标。
所以我们没有用上述的方法来增加数据集,而是建议用一种alignment-sensitive的方法来增加用于微调调整网络的图像数据集。在相同的簇中,随机取两训练图片,然后估计一下它们的非反射相似性变换进行处理。