项目说明
数据是抖音9-21到10-30日间的交互记录,年份已做特殊处理(显示为2067) 具体字段说明如下:
·第一列没标(像是顺序ID,但是不连续,估计是数据集有被筛选处理过)
·uid:用户id
·user_city:用户所在城市
·item_id:作品id
·author id:作者id
·item_city:作品城市
·channel:观看到该作品的来源
·finish:是否浏览完作品
·like:是否对作品点赞
·music id:音乐id
·device:设备id
·time:作品发布时间
·duration time:作品时长s
分析目的:对网红、平台运营提出建议
数据处理
import pandas as pd
import numpy as np
import time
from pyecharts.charts import Line,Pie,Grid,Bar,Page
import pyecharts.options as opts
data=pd.read_table('douyin.txt',header=None)
#补充值字段名称
data.columns = ['uid','user_city','item_id','author_id','item_city','channel','finish','like','music_id','device','time','duration_time']
data.head()

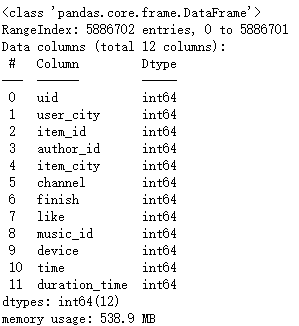
data.info()
缺失值处理
不存在缺失值
data.isnull().sum()

重复值处理
#删除重复值
print('重复值个数:',data.duplicated().sum())
data.drop_duplicates(inplace=True)
重复值个数: 4924
#数据是进行过脱敏的数据,无法观察原有情况,不过可以推断其中的-1是缺失值,转换后直接删除即可。
data[data==-1] = np.nan
data.dropna(inplace=True)
#本次分析中不会使用到device列,和多余Unnamed: 0列,删除
del data['device']
数据转换
#time列是时间戳,修改成正常时间
data.time=data.time.astype('str')\
.apply(lambda x:x[1:])\
.astype('int64')
#将时间戳转换为普通的日期格式
real_time = []
for i in data['time']:
stamp = time.localtime(i)
strft = time.strftime("%Y-%m-%d %H:%M:%S", stamp)
real_time.append(strft)
data['real_time'] = pd.to_datetime(real_time)
#time列无用了,删除
del data['time']
#为数据添加H:小时,和date:日期列
data['H'] = data.real_time.dt.hour
data['date']=data.real_time.dt.date
data=data[data.real_time>pd.to_datetime('2067-09-20')]
data.head()

数据分析
日播放量、用户量、作者量、投稿量
#日播放量
ids=data.groupby('date')['date'].count()
#日用户量
uids=data.groupby('date')['uid'].nunique()
#日作者量
author=data.groupby('date')['author_id'].nunique()
#日作品量
items=data.groupby('date')['item_id'].nunique()
#日播放量
line1 = (
Line()
.add_xaxis(ids.index.tolist())
.add_yaxis('日播放量', ids.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='日播放量变化趋势',pos_left="20%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='日播放量'),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
#日用户量
line2 = (
Line()
.add_xaxis(uids.index.tolist())
.add_yaxis('日用户量', uids.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='日用户量变化趋势',pos_right="20%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='日用户量'),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
#日作者量
line3 = (
Line()
.add_xaxis(author.index.tolist())
.add_yaxis('日作者量', author.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='日作者量变化趋势',pos_top="50%",pos_left="20%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='日作者量'),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
#日作品量
line4 = (
Line()
.add_xaxis(items.index.tolist())
.add_yaxis('日投稿量', items.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='日投稿量变化趋势',pos_top="50%", pos_right="20%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='日投稿量'),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
grid1 = (
Grid()
.add(line1, grid_opts=opts.GridOpts(pos_bottom="60%",pos_right="55%"))
.add(line2, grid_opts=opts.GridOpts(pos_bottom="60%",pos_left="55%"))
.add(line3, grid_opts=opts.GridOpts(pos_top="60%",pos_right="55%"))
.add(line4, grid_opts=opts.GridOpts(pos_top="60%",pos_left="55%"))
)
grid1.render_notebook()

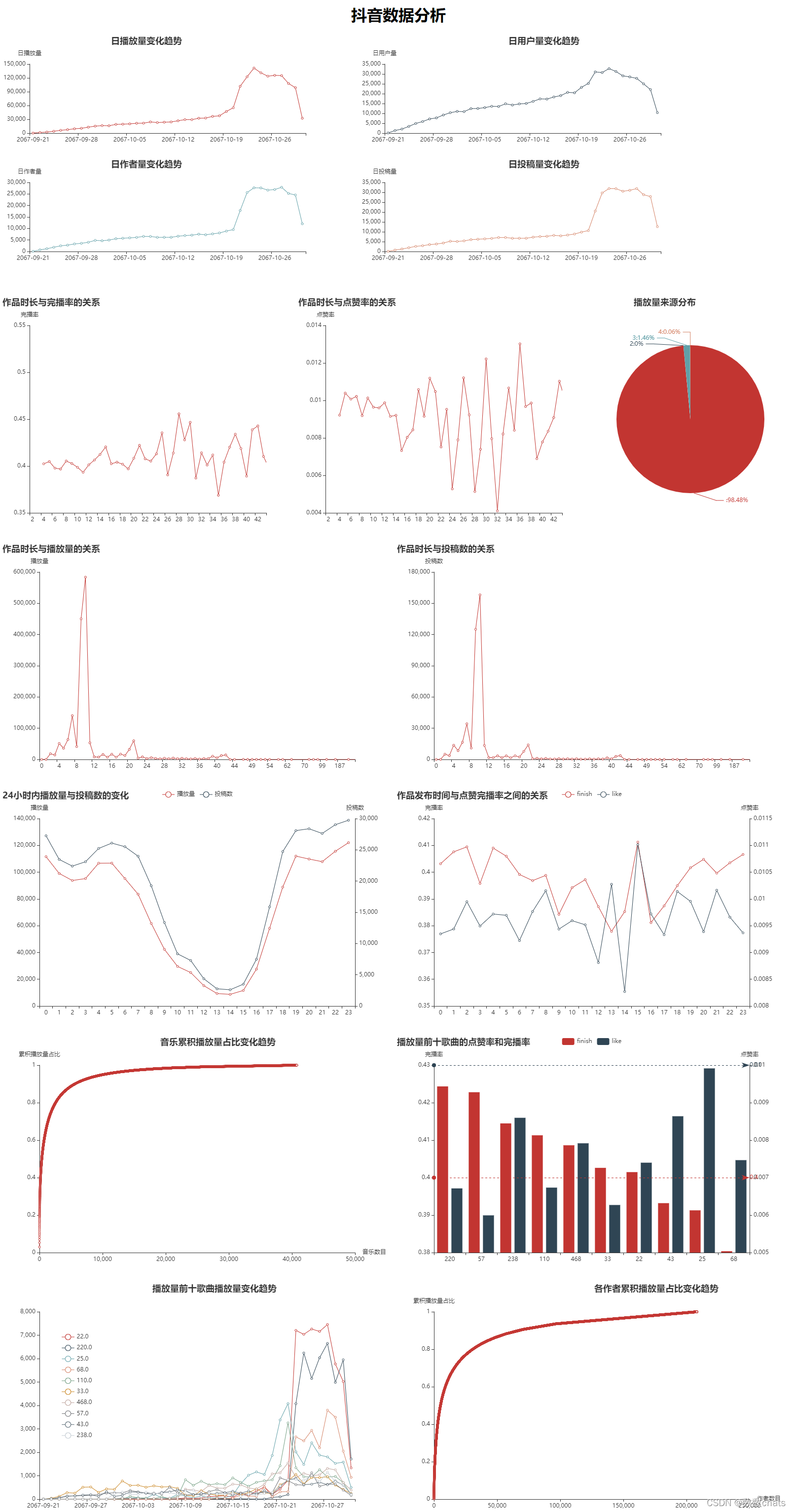
在10-21日之前日播放量,日用户量,日作者量,日投稿量随时间的变化趋势基本一致:平稳增长;
在10-21到10-30时间段内,各指标均先出现巨大增长,后趋近平稳,再回落到正常水平值,猜则该时间点平台有进行活动推广。
不过可以明显看出来用户量并没有播放量上涨的幅度夸张。且作者和投稿数量也比用户量上涨得迅速,初步猜测是有人利用平台规则漏洞,创建大量新号,并使用机器人刷单牟利。
不过遗憾由于没有之后更长时期的数据,难以评估此次活动的效果。不过可以尝试检查出其中的机器人帐号。
exception=data.groupby(['uid','date'])['uid'].count()[data.groupby(['uid','date'])['uid'].count()>1].unstack().T
exception.index=exception.index.astype('datetime64[ns]')
exception.head()
#(预测)活动开始前后每人平均观看量的变化倍数
times = exception.query('date>datetime(2067,10,21) and date<datetime(2067,10,29)').mean() / exception.query('date<datetime(2067,10,21)').mean()
times.describe([0.25,0.5,0.75,0.8,0.85,0.9,0.95,0.99])
#机器人(绝大多数人的变化倍数在0-3倍之间故选取3倍)
robot = times[times>3].index.tolist()
len(robot)
4267
new=data.query('real_time>datetime(2067,10,21) & real_time<datetime(2067,10,29)')['uid']
old=data.query('real_time<datetime(2067,10,21)')['uid']
print('10-21到10-29日活动新增用户数为:',new.nunique()-new[new.isin(old)].nunique())
10-21到10-29日活动新增用户数为: 5739
结论: 有4267是机器人的嫌疑,而此次活动新增用户也不过5739人,这进一步印证了现在的网络是以存量市场为主,如果想要吸引新的创作者和用户那么可能更需要去新的市场比如海外或者在抖音外的市场做宣传可能会效果更好。
播放量来源分布
channel = data.groupby('channel')['uid'].count()
pie1=(
Pie()
.add('播放量', [list(z) for z in zip(channel.index.tolist(), channel.values.tolist())])
.set_global_opts(title_opts=opts.TitleOpts(title='播放量来源分布',pos_left='20%'),legend_opts=opts.LegendOpts(is_show=False))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
)
pie1.render_notebook()
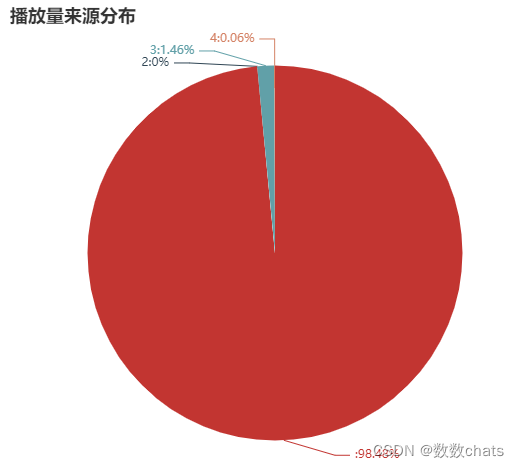
虽然没有明确说明,但作为算法驱动的短视频平台,显然可知“0”是算法推荐的视频。那么在抖音获得播放量的关键就是获得算法推荐进入更大的流量池。
作品时长
#作品时长与播放量
duration_uid = data.groupby('duration_time')['uid'].count()
#查看时长与完播率和点赞率之间的关系
time_finish = data[['duration_time','finish','like']].groupby('duration_time').mean()
#只统计各时长内播放量超过100的作品
num_100=time_finish[data[['duration_time','finish','like']].groupby('duration_time').count()>100]
num_100.dropna(inplace=True)
#作品时长与作品数量
duration_nums = data.groupby('duration_time')['item_id'].nunique()
line5=(
Line()
.add_xaxis(duration_uid.index.tolist())
.add_yaxis('播放量', duration_uid.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='作品时长与播放量的关系',pos_left="15%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='播放量'),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
line6=(
Line()
.add_xaxis(duration_nums.index.tolist())
.add_yaxis('投稿数', duration_nums.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='作品时长与投稿数的关系',pos_right="15%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='投稿数'),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
line7=(
Line()
.add_xaxis(num_100.index.tolist())
.add_yaxis('完播率', num_100.finish.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='作品时长与完播率的关系',pos_top="50%",pos_left="15%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='完播率',min_=0.35,max_=0.55),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
line8=(
Line()
.add_xaxis(num_100.index.tolist())
.add_yaxis('点赞率', num_100.like.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='作品时长与点赞率的关系',pos_top="50%", pos_right="15%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='点赞率',min_=0.004,grid_index=4),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
grid2 = (
Grid()
.add(line5, grid_opts=opts.GridOpts(pos_bottom="60%",pos_right="55%"))
.add(line6, grid_opts=opts.GridOpts(pos_bottom="60%",pos_left="55%"))
.add(line7, grid_opts=opts.GridOpts(pos_top="60%",pos_right="55%"))
.add(line8, grid_opts=opts.GridOpts(pos_top="60%",pos_left="55%"))
)
grid2.render_notebook()
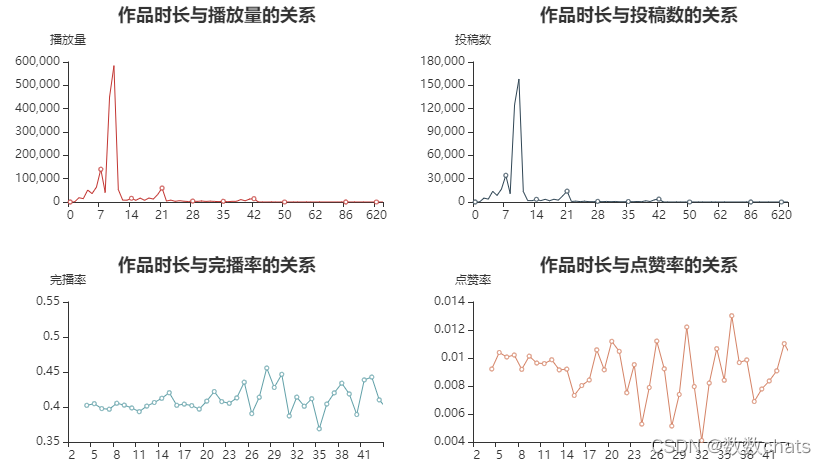
观察结果:
作品时长绝大多数在7-10s间,总体来说在0s-22s之间都有一定数量的投稿,22s以上的就很少了。
播放量的时长分布基本与作品数量的时长分布相同。
完播率在2s-27s内总体在40%以上,27s以后开始在37%-45%之间剧烈波动,
点赞率在2s-14s内基本维持在1%之内,在14s-20s之间会在0.7%-1.1%之间波动,在20s以后数据变化的波动完全没有规律。
结论: 视频时长最好在7-10s,其次是0-6s及23s以内,最长也不建议超过40s(在记录中没有一条超过50s视频播放量超过100)
各小时
#每时播放量
H_num = data.groupby('H')['uid'].count()
#每时投稿数
H_item = data.groupby('H')['item_id'].nunique()
#作品发布时间与点赞完播率之间的关系
H_f_l = data.groupby('H')[['finish','like']].mean()
line9=(
Line()
.add_xaxis(H_num.index.tolist())
.add_yaxis('播放量', H_num.values.tolist())
.extend_axis(yaxis=opts.AxisOpts(name="投稿数",position="right")) #min_=0,max_=25,
.set_global_opts(
title_opts=opts.TitleOpts(title='24小时内播放量与投稿数的变化'),
yaxis_opts=opts.AxisOpts(name="播放量"), #,min_=0.35
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
line10=(
Line()
.add_xaxis(H_item.index.tolist())
.add_yaxis('投稿数', H_item.values.tolist(),yaxis_index=1)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
overlap1=line9.overlap(line10)
overlap1.render_notebook()
line11=(
Line()
.add_xaxis(H_f_l.index.tolist())
.add_yaxis('finish', H_f_l.finish.tolist())
.extend_axis(yaxis=opts.AxisOpts(name="点赞率",position="right",min_=0.008))
.set_global_opts(
title_opts=opts.TitleOpts(title='作品发布时间与点赞完播率之间的关系'),
yaxis_opts=opts.AxisOpts(name="完播率",min_=0.35),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
line12=(
Line()
.add_xaxis(H_f_l.index.tolist())
.add_yaxis('like', H_f_l.like.tolist(),yaxis_index=1)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
overlap2=line11.overlap(line12)
overlap2.render_notebook()

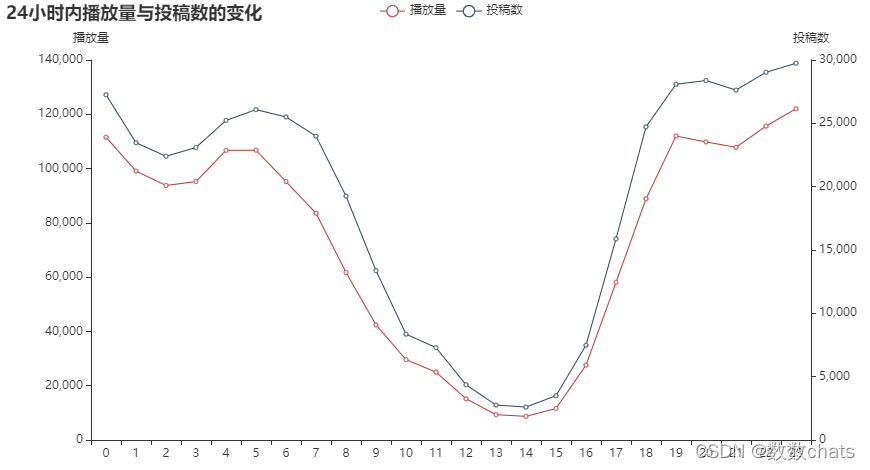
结论: 整体播放量和投稿数基本相同,晚上19点到第二天5点这段时间的播放量会略高。不同时间段内发布的作品点赞率和完播率不会有太大变化。
如果投稿最佳时间是在晚上19点到第二天5点这段时间,但完播率和点赞率并无特殊优势。
背景音乐
#前100名热门歌曲播放量差异
music_100=data.groupby('music_id')['uid'].count().sort_values(ascending=False).iloc[:100,].sort_values(ascending=False)
#背景音乐总播放量累积累积占比分布图
music_cum=data['music_id'].value_counts().sort_values(ascending=False).cumsum()/len(data['uid'])
x=range(len(music_cum)+1)
line13 = (
Line()
.add_xaxis(x)
.add_yaxis('累积播放量占比', music_cum.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='音乐累积播放量占比变化趋势',pos_left="40%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='累积播放量占比'),
xaxis_opts=opts.AxisOpts(name='音乐数目'),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
line13.render_notebook()
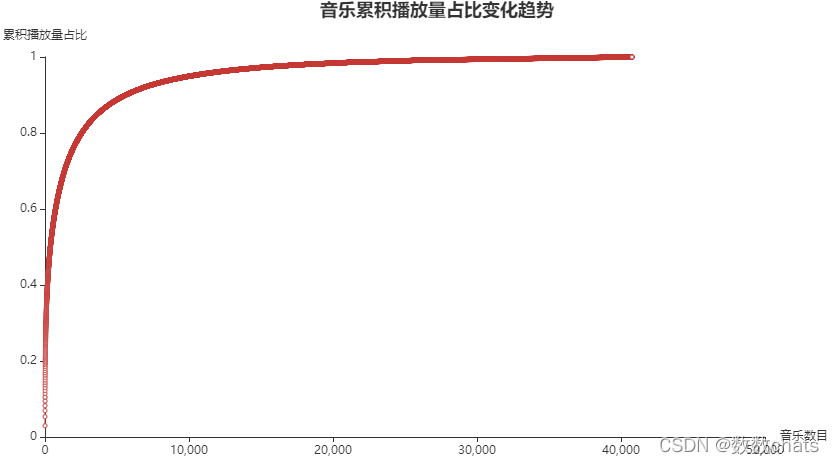
结论: 对于视频配乐更推荐当时最火的歌曲,会比其他歌曲更容易获得高播放量。
#播放量前十的歌曲点赞率和完播率
top_10=data.groupby('music_id')[['finish','like']].mean()\
.loc[data.groupby('music_id')['uid'].count().sort_values(ascending=False).iloc[:10,].index.tolist()]\
.sort_values('finish',ascending=False)
#播放量大于10的歌曲的平均完播率和点赞率
avg_10=data.groupby('music_id')[['finish','like']].mean()[data.groupby('music_id')['uid'].count()>10].mean()
bar1=(
Bar()
.add_xaxis(top_10.index.tolist())
.add_yaxis('finish', top_10.finish.tolist())
.extend_axis(yaxis=opts.AxisOpts(name="点赞率",position="right",min_=0.005))
.add_yaxis('like', top_10.like.tolist(),yaxis_index=1)
.set_global_opts(
title_opts=opts.TitleOpts(title='播放量前十歌曲的点赞率和完播率'),
yaxis_opts=opts.AxisOpts(name="完播率",min_=0.38),
)
.set_series_opts (
label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(name="平均完播率",y = avg_10.finish),
opts.MarkLineItem(name="平均点赞率",y = avg_10.like)
],
label_opts=opts.LabelOpts(), #不显示数据标签
),
)
)
bar1.render_notebook()

可以看出最热门的歌曲点赞率和完播率也并没有超过平均,可见采用热门歌曲并不能提高自己的完播率和点赞率。
#热门歌曲每日播放量变化图
top_date=data.groupby(['music_id','date'])['uid'].count()\
.loc[data.groupby('music_id')['uid'].count().sort_values(ascending=False).iloc[:10,].index.tolist()]\
.unstack().T
line14=(
Line()
.add_xaxis(top_date.index.tolist())
.add_yaxis(str(top_date.columns[0]), top_date.iloc[:,:1].values.tolist())
.add_yaxis(str(top_date.columns[1]), top_date.iloc[:,1:2].values.tolist())
.add_yaxis(str(top_date.columns[2]), top_date.iloc[:,2:3].values.tolist())
.add_yaxis(str(top_date.columns[3]), top_date.iloc[:,3:4].values.tolist())
.add_yaxis(str(top_date.columns[4]), top_date.iloc[:,4:5].values.tolist())
.add_yaxis(str(top_date.columns[5]), top_date.iloc[:,5:6].values.tolist())
.add_yaxis(str(top_date.columns[6]),top_date.iloc[:,6:7].values.tolist())
.add_yaxis(str(top_date.columns[7]), top_date.iloc[:,7:8].values.tolist())
.add_yaxis(str(top_date.columns[8]), top_date.iloc[:,8:9].values.tolist())
.add_yaxis(str(top_date.columns[9]), top_date.iloc[:,9:10].values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='播放量前十歌曲播放量变化趋势',pos_left="38%"),
legend_opts=opts.LegendOpts(pos_top='20%',pos_left='15%',orient='vertical'),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
line14.render_notebook()
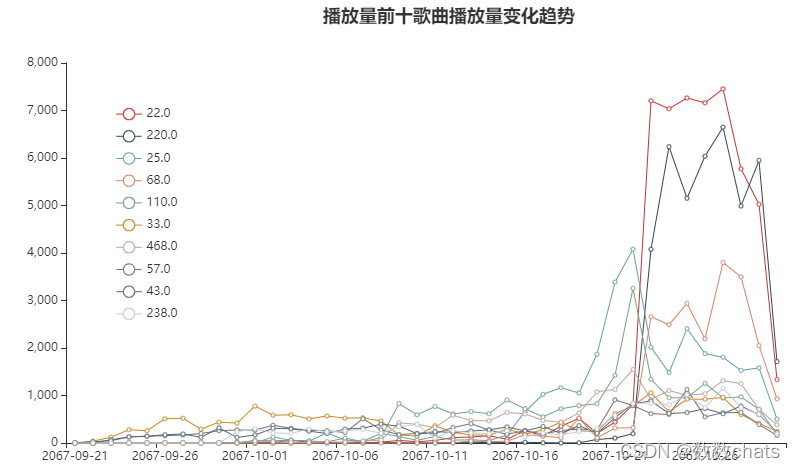
10-21到10-29日内,各歌曲作品的播放量都有增高,其中ID为22,220,68,25的歌曲有暴涨趋势。
作品和作者
#各作者id总播放量累积数量分布图
item_cum=data['author_id'].value_counts().sort_values(ascending=False).cumsum()/len(data['uid'])
x=range(len(item_cum)+1)
line15 = (
Line()
.add_xaxis(x)
.add_yaxis('累积播放量占比', item_cum.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='各作者累积播放量占比变化趋势',pos_left="50%"),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name='累积播放量占比'),
xaxis_opts=opts.AxisOpts(name='作者数目'),
)
.set_series_opts (label_opts=opts.LabelOpts(is_show=False))
)
line15.render_notebook()
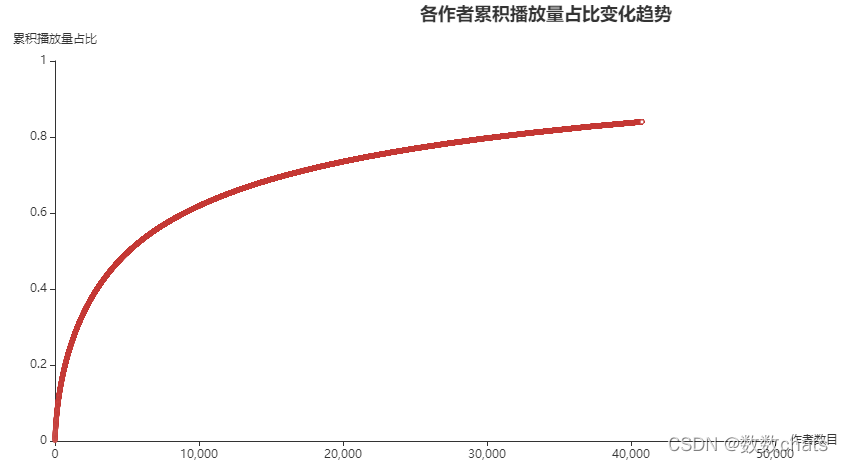
结论: 可以看出目前抖音整体用户播放十分符合帕累托分布,极少数的制作者吸引了全平台绝大部分流量。如果还想在此基础上再次提升,培养头部制作者,或者挖掘其他平台的头部制作者是比单纯给制作奖励更加有效的方法。具体的效果如何还需要更多数据支撑才能得出结论。
总结
抖音网红建议
1.抖音98%以上的流量都会流向算法推荐视频,获得算法推荐是获得更多播放的关键所在。
2.视频时长最好在7-10s,其次是0-6s及23s以内,最长也不建议超过40s。
3.获得播放量的最佳投稿时间在晚上9点到第二天早上5点这段时间,但完播率和点赞率并无明显的时段偏好。
4.背景音乐最好选择当下最流行的歌曲,从而吸引点播,但最重要的始终是题材的选择。
平台运营建议
1.抖音活动时有大量机器人存在,需要决定是否清除(疑似机器人的[uid]保存在“robot”列表中)。
2.站内活动初见不错,但在去除机器人后并没有大量实质增长,收益很低,再次举办需要慎重。
3.平台用户始终稳步增长中,但如果想要大量增长,考虑其他渠道,或者开辟新市场是更好的选择。
4.排名前20%的视频制作者占据了整个平台80%以上的流量,培养或者挖掘已存在的好视频制作者是未来保持流量的关键。
BI简易看板