一、事件背景
集群服务器崩溃导致众多大数据组件异常强制关闭,重启服务器器和集群后,所有组件状态正常,但是flink任务不能正常运行。
二、问题现象
重启服务器后看似一切正常,组件状态良好
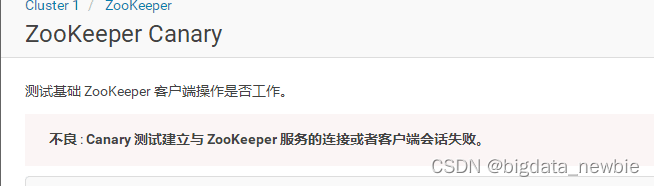
但是在提交flink任务时发现一个问题,zookeeper时不时报canary的测试失败
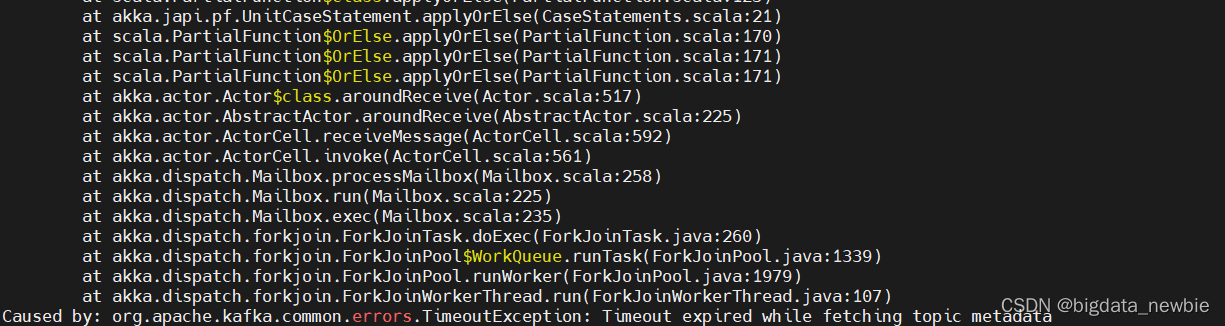
随后查看flink运行日志,发现报错:获取topic元数据超时,并且是所有任务都报这个
三、定位问题
要解决问题就要找到产生问题的根源
结合zookeeper时不时报canary测试失败,怀疑是网络问题(服务器拉跨),但是没有办法证明,只能继续想其他办法。
在服务器端用命令行启动一个消费者,同样还是报错

这下明白了,不是网络问题,应该是kafka元数据出问题了
于是使用命令查看各个topic的信息
kafka-topics --describe --zookeeper node3:2181
结果显示所有topic都是正常的
于是新建一个topic试试看能不能被消费,结果也是不行,还是报上图的错
于是想到可能是zookeeper上保存的kafka集群信息有问题,最后定位到是zookeeper上的 /controller 文件记录的信息和实际的不匹配
四、解决问题
定位问题后就好解决了
1、关闭kafka集群服务。
2、删除/controller文件
3、重启zookeeper集群
4、开启kafka集群服务
5、重新提交flink任务
6、问题解决
五、拓展
/controller文件作用
在一个 Kafka 集群中,只有一个 Broker 被选举为Controller,每个Broker都有机会成为Controller,负责管理集群中的分区、副本、故障检测和恢复等任务。为了确保在Broker故障时能够快速重新选举新的Controller,Kafka使用Zookeeper来存储和管理Controller的信息。因此,/controller 文件的内容是非常关键的,它可以让 Kafka Broker 和其他客户端知道当前的控制器是哪个 Broker,并与控制器进行通信以便及时处理各种任务。
具体来说,Kafka在Zookeeper上的/controller节点中存储了当前Controller的ID和地址信息。这些信息可以被其他Broker和客户端访问,以便它们可以与Controller进行通信并执行必要的管理任务,例如创建或删除分区和副本。
此外,Kafka还使用Zookeeper来存储其他与集群管理相关的元数据,例如分区和副本的分配信息,以及消费者组的偏移量信息。