一、CK失败
Flink任务的checkpoint操作失败大致分为两种情况,ck decline和ck expire:
(1)ck decline
发生ck decline情况时,我们可以通过查看JobManager.log或TaskManager.log查明具体原因。其中有一种特殊情况为ck cancel,当前 Flink 中如果较小的ck还没有对齐的情况下,收到了更大的ck,则会把较小的ck给取消掉。
(2)ck expire
如果ck做的非常慢,超过了timeout还没有完成,则整个ck也会失败。这种情况也可以通过查看JobManager.log或TaskManager.log查明具体原因。
由查看JobManager和TaskManager(下文简称TM)当时的日志可知,是因为TM重启,导致做ck超时,发生了ck Expire。
而TM重启的原因,主要有两个原因,一个可能是网络传输波动,另一个是TM资源不足,通过进一步排查,本次TM重启的原因是当时处理数据量增加,导致TM资源不足,发生了TM重启,进而导致了那次ck失败。
二、TaskManager内存分析
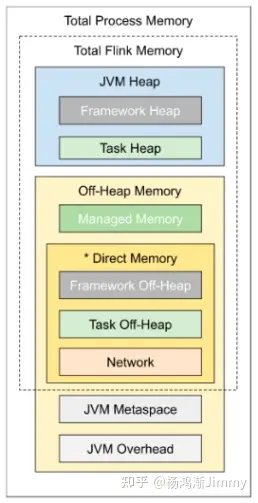
TaskManager内存示意图
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| 框架堆内存(Framework Heap Memory) | taskmanager.memory.framework.heap.size | 用于 Flink 框架的 JVM 堆内存 |
| 任务堆内存(Task Heap Memory) | taskmanager.memory.task.heap.size | 用于 Flink 应用的算子及用户代码的 JVM 堆内存 |
| 托管内存(Managed memory) | taskmanager.memory.managed.size | 由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存 |
| 框架堆外内存(Framework Off-heap Memory) | taskmanager.memory.framework.off-heap.size | 用于 Flink 框架的堆外内存(直接内存或本地内存) |
| 任务堆外内存(Task Off-heap Memory) | taskmanager.memory.task.off-heap.size | 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存) |
| 网络内存(Network Memory) | taskmanager.memory.network.min | 用于任务之间数据传输的直接内存(例如网络传输缓冲)。该内存部分为基于 Flink 总内存的受限的等比内存部分 |
| JVM Metaspace | taskmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace |
| JVM 开销 | taskmanager.memory.jvm-overhead.min | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分 |
Flink并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上,这个内存块叫做MemorySegment,它代表了一段固定长度的内存(默认大小为32KB),也是Flink中最小的内存分配单元,并且提供了非常高效的读写方法。如果因为内存空间不足,无法申请到更多的内存区域来存储对象时,Flink会将MemorySegment中的数据溢写到本地文件系统(SSD/HDD)中。当再次需要操作数据时,会直接从磁盘中读取数据。
三、调整说明及建议
从以上内容的分析和介绍,在某些情况下,我们可以调整或优化TM的内存,来规避TM重启的问题,最终尽可能避免ck失败的情况。
对于没有硬性资源限制的环境,我们可以使用taskmanager.memory.flink.size参数来配置 Flink总内存的大小,然后Flink自己也会自动根据参数,计算得到各个子区域的配额。如果作业运行正常,则无需单独调整。
如果要更精细化的调整,可以调大JVM Heap中的Task Heap,Task Heap Memory是专门用于执行Flink任务的堆内存空间,是用户代码,自定义数据结构真正占用的内存,通过参数taskmanager.memory.task.heap.size指定。
再其次可以调大Direct Memory中的Task Off-heap Memory,Task Off-heap Memory是Flink执行task所使用的堆外内存。如果在Flink应用的代码中调用了Native的方法,需要用到off-head内存,这些内存会分配到Off-heap堆外内存中,通过参数taskmanage.memory.task.off-heap.size 指定,默认为0。
再其次可以调大Direct Memory中的Network Memory,Flink的Task之间的shuffle,广播等操作以及与外部组件的数据传输需要用到Network Memory,该值通过3个参数确定:
--taskmanager.memory.network.min,Network Memory最小值
--taskmanager.memory.network.max,Network Memory最大值
--taskmanager.memory.network.fraction,Network Memory占Total Flink Memory的比例,默认0.1。如果通过该比例值计算出的结果超出前两个MIN-MAX参数的范围,则以MIN-MAX为准。如果MIN-MAX参数使用同样的值,则表示NetWork是固定的内存大小。
四、可参考的TaskManager内存计算公式
1、每个任务TaskManager分到的总共内存(tm_total_memory)=taskmanager.memory.flink.size - taskmanager.memory.jvm-metaspace.size(JVM元空间,JVM Metaspace)-JVM Overhead Memory (JVM 运行时开销)
其中JVM Overhead Memory用来存放线程栈、编译的代码缓存、JNI 调用的库所分配的内存等等。
--taskmanager.memory.jvm-overhead.fraction,默认 0.1
--taskmanager.memory.jvm-overhead.min,默认 192mb
--taskmanager.memory.jvm-overhead.max,默认 1gb
总进程内存*fraction,如果小于配置的 min(或大于配置的 max)大小,则使用 min/max大小。
2、每个任务TaskManager真正使用的堆内内存(tm_heap_memory)= tm_total_memory- taskmanager.memory.framework.heap.size(堆内框架内存,默认128M - taskmanager.memory.framework.off-heap.size(堆外框架内存,默认128M)- Network Memory(网络内存)- Managed memory(托管内存)
其中Managed Memory托管内存,是有Flink直接管理的堆外内存,用于排序,哈希表,中间结果缓存,以及RocksDB的状态后端。通过参数taskmanage.memory.managed.size指定,默认情况下不配置,通过参数taskmanager.memory.managed.fraction因子(默认0.4) * Total Flink Memory来指定大小。
最后具体情况需要根据业务的复杂度、数据量和集群情况合理分配slot ytm tjm p,其实并行度的设置可以根据算子里面的不同情况各自设置并行度,但是最大的并行度是由 [(slot * jobmanager的数据 ) * nodemanager数量 ]决定的,jobmanager的数量=(可申请的最大内存 - yjm ) / ytm 。其实有的时候slot越大并不会性能越高,集群的资源需要留一部分给hbase hive等数据仓库来做缓存使用,在代码层无法优化后,还是需要根据实际情况测试调整集群资源和运行资源。