
最近好奇二维码的原理是什么?怎么能做到一扫就能挑指定的页面或功能的呢?下面通过搜集资料整理了一些关于二维码的原理文章,希望可以帮助到你快速的了解二维码的原理
首先,二维码是什么呢?
大家平时都用惯了各种二维码了,扫码支付、扫码骑车、扫码点餐等等。对那些黑白方块大家都很熟悉了。长啥样就不贴图。
之所以叫二维码,因为它是二维的,这里的二维不是黑、白,而是有横向、纵向之分,就是初中数学里的x轴,y轴。
类比的一维码就是条形码,看上去也是有横向和纵向高度啊?但因为每个x对应的y是一样的,就是两条平行横线切过去,获取到的信息是一样的。
其次,二维码是的组成部分有哪些?
以QR Code为例,也就是我们最常见的二维码,里面存储的信息其实是分割成多个部分的。
(1)探测区(红色圈),就是三个回字型正方形框。用来定位二维码边界。为啥是三个回字型,不是两个,不是4个?两个不足以定位,已知两个顶点,至少可以向上或向下画出两个不同正方形。4个顶点可以确定唯一正方形,但没办法做图形旋转角度矫正了,没法确定左上角、右下角,因为四个顶点全对称了。三个刚好,既能确定出唯一位置,又能任何角度拍照都可以旋转恢复成只有右下角没有探测区的0旋转标准图。
(2)定位线(蓝色框),用来做分割不同区域,方便定位,定位线始终是黑白相间的,且只有一行、一列,非常明显。
(3)版本信息(红色框),版本信息存的是这个二维码是什么版本,不同版本二维码大小不一样,比如版本1,是21✖️21的正方形,版本2,是25✖️25的正方形,最大版本是版本40,是177✖️177的正方形,显然版本越大,能存的信息就越多。
(4)格式信息(黄色圈),格式信息里存储了这个二维码数据是按什么模式解析。比如数字是0001,字母数字是0010,汉字是1101。cxd1301是字母数字,所以格式信息是0010。
(5)数据区域(绿色圈),二维码的有效数据是存储在绿色区域里,这里不仅存储了有效数据,还有纠错码字,这样的话,就算二维码损坏部分都可以识别。

三、二维码里的数据怎么读
首先二维码是一个个小方块构成的,其中黑色小方块代表“1”,白色小方块代表“0”。实质上二维码是存储的0和1的二进制比特流。
这个数据是怎么存进去的呢?
小写c的ASCII码对应十进制99,转化成二进制就是01100011,对应写入二维码就是白、黑、黑、白、白、白、黑、黑。
cxd1301,在二维码里存的就是01100011 01111000 01100100 00110001 00110011 00110000 00110001。
然后这些二进制比特流,还需要加上字符个数7对应的二进制0000111,编码标识字母数字是0010,以及结束符0000,纠错级别H,对应的AC-42,对应二进制10,以及补齐符00,最后串成一大串的01比特串一起存入二维码。转化为黑、白点变化。
这些还没有完,为了让数据区域不出现大面积空白或黑块,还要进行底图叠加。这个叠加采用的是异或操作,将要写入的数据和底图异或处理后就得到最终的二维码。最完蛋的是我不知道是和8个底图中的那个进行了异或,所以要肉眼读二维码,就要读取8个,放弃了。
最后要说的是,二维码的数据读取顺序是从右下角开始的,顺序参照网上找的以下这张图片。
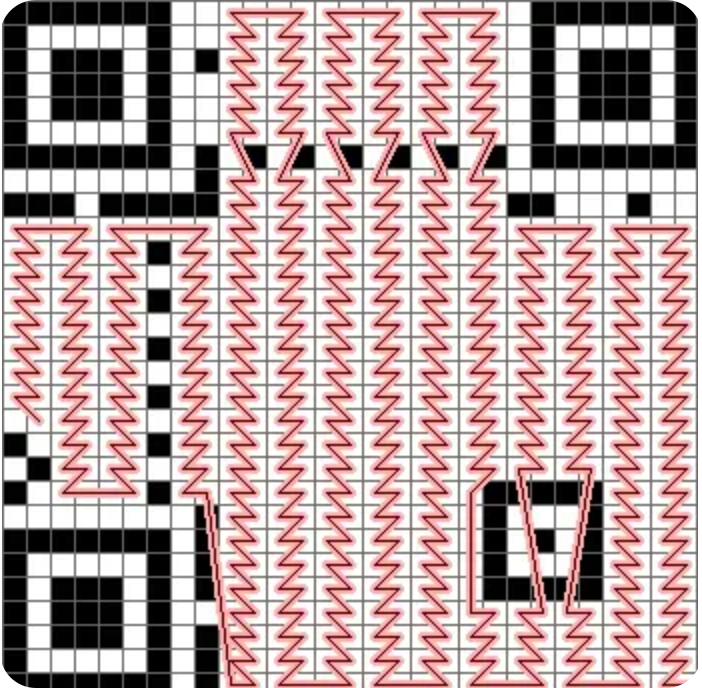
二维码缺损是否可以用 ?
对于条形码,如果有破损,只要有其中一行没有坏就问题不大,那二维码呢,如果有破损什么的是否还可以扫描成功?肯定是可以的,这个也一直是我认为二维码比较神奇的地方。
二维码的容错有7%(L)、15%(M)、25%(Q)、30%(H)四种,以H为例,表示30%的字码可以被修复,换句话说就是30%的破损不影响扫码。这就比较牛了,大大提高了二维码的使用场景。
有这么几种情况是会影响二维码识别的:
(1)探测区破损,至少一个探测区破损了,这种情况下,不能准确识别出这是否是一个二维码,就更没有后续的识别了;
(2)版本信息全没,且格式信息也不全,那就识别不出来了。但凡只要有一个版本信息及一个格式信息正常,就可以识别。
(3)数据区域破损超过30%。基本上就算大面积污损数据区域,识别率都还能有一定保障,例如下面这个数据区的破损情况,拿手机多扫一下还是可以扫出来。
注:因为存在识别率问题,可能要多扫两次。
二维码可以存储多少信息
通过查询QR码的技术文档,可以发现,如果二维码使用最大版本40,也就是177*177的的二维码,最大可存储信息是:
(1)纯数字,7089字符;
(2)纯字母,4296字符;
(3)二进制,2953字节;
(4)汉字(UTF-8),最多984汉字。
考虑到,一般情况下,没有人真往二维码里存一篇小说的或一部电影,基本上就是存小说和电影的观看或下载地址,所以最大到3K的二维码,容量基本上满足使用要求了。
这里来一个超大信息的二维码,这个二维码由于信息过多,所以密密麻麻,小图的情况下基本上是没法识别了,但放大到一定程度,还是有可以会被识别出来。这里要注意如果是单纯汉字最多984个汉字。因为一个标点和数字是1个字符,一个汉字是3个字节,所以如果有字母和数字,看上去就不止983个字了。
附一个Python识别二维码的代码,大家愿意玩的可以看下
from pyzbar.pyzbar import decode
from PIL import Image
decocdeQR = decode(Image.open("decode.png"))
print(decocdeQR[0].data.decode('ascii'))欢迎一键三连,点赞、收藏、加关注,谢谢