深度学习(34)—— StarGAN(1)
文章目录
和之前一样还是先理论后代码,所以这一讲还是StarGAN的理论。
1. 背景
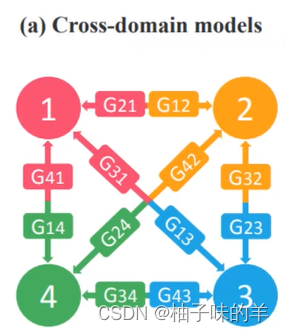
先回忆一下,之前写的cyclegan,可以实现两个域之间的相互转换。即下面这几种情况:
- 将输入人像转化为我想要的图像发色
- 将输入人像转化为我想要的性别
- 将输入人像转化为我想要的年龄
- 将输入人像转化为我想要的肤色

上面这种两个域之间的转化使用cyclegan就可以实现,但是如果想要实现在K个域的相互转化,使用cyclegan就需要训练k(k-1)个generator网络,时间成本和计算成本都太大。
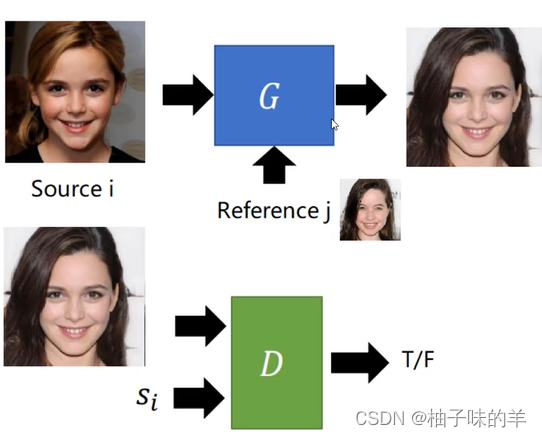
可不可以只训练一个模型,根据我的reference图片的特征将source转化为我想要的图片?
为了满足这一需求,就出现了StarGAN
2. 基本思路
- 使用StarGAN,只需要训练一个generator。相比cyclegan,StarGAN在输入时增加了类型编码(可以理解为【转化肤色,转化年龄,转化性别,转化发色】的编码)
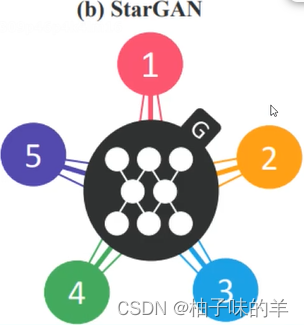
- 无论是generator还是discriminator都增加这样的编码向量
3. 整体流程
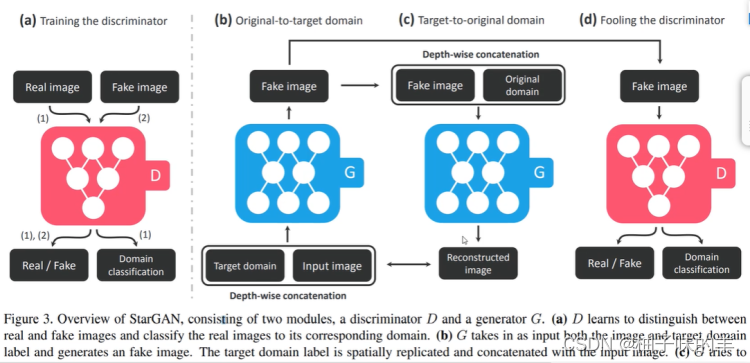
generator
- 输入一张image和目标域 target domain的编码(向量) 经过generator生成targaet domain的fake image
- 将得到的fake image 和 原图的domain输入generator生成restructed image(与input image 做loss)
- 此时将fake image输入discriminator中让他辨别fake image的真假,还要输出domain 的编码,试图骗过discriminator
discriminator
- 在训练过程中,输入real image 和 fake image,经过discriminator不但要辨别每张image的真假,还要辨别每张照片属于的domain编码
4. StarGAN v2
上面说的都是StarGANv1,他针对domain做了one-hot 编码,一个编码一个风格。
v2相对于v1的进步是用实际的特征向量作为风格的编码,在特征基础上进行提取和分析。v1中只使用one-hot编码学不到每种风格的具体知识
(1) 网络结构
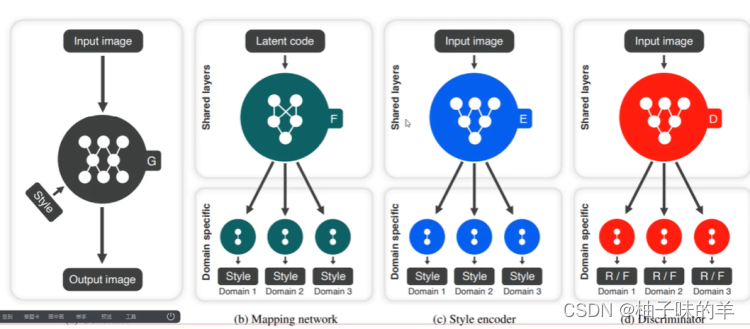
相较于v1,v2主要对每种风格进行编码,使用到 mapping network 和 style encoder
(2) mapping network
随机生成的一个向量编码latent code 和一张图片经过网络后将当前的latent coder 编码成属于该图片风格的特征,用于代表该风格domain的编码
(3) style encoder
输入一张图片经过该encoder可以得到属于这张照片的风格domain编码。
(4)Loss
在正常的GAN网络基础上增加了三个额外的loss
扫描二维码关注公众号,回复:
16480091 查看本文章

- style_loss:mapping 得到的style 编码要尽可能与style得到的style 编码相似。
- diversity_loss:同一张图变换为不同风格,变换后的两者要尽可能的存在较大差异(差异多样性)
- cycle_loss :转化的是风格,不能主体变得太离谱,真实的和rec之间的loss【和cyclegan中的一个loss 一样】
okk,今天就先这么多,代码讲解,明天吧,整个项目,老地方github上!