分类目录:《深入理解联邦学习》总目录
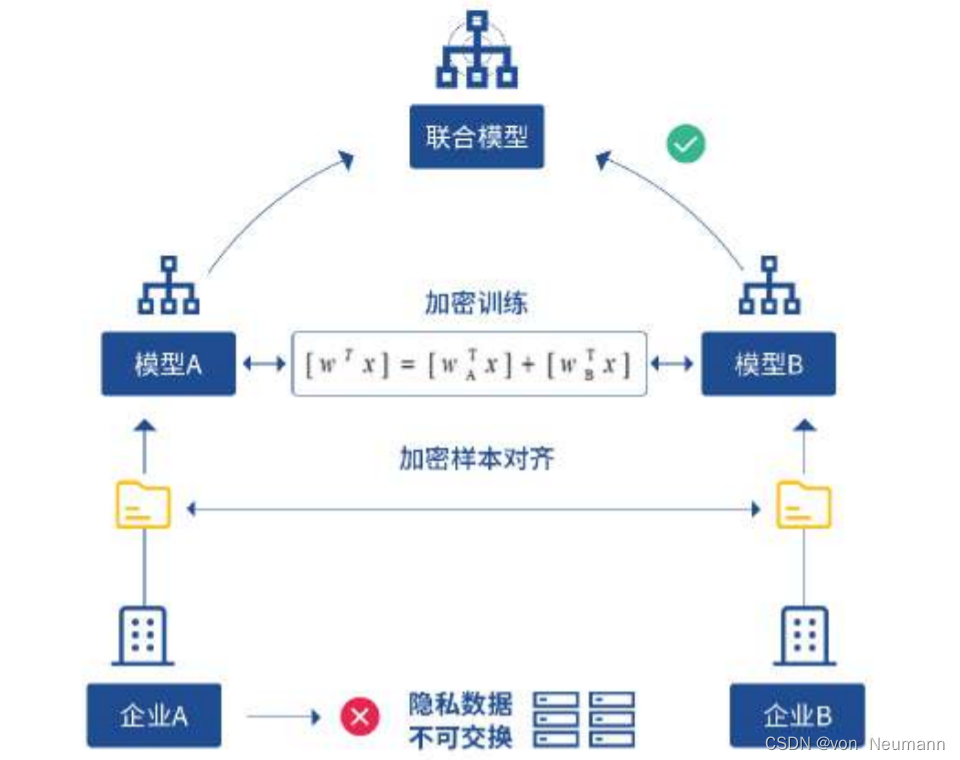
假设有两个不同的企业 A A A和 B B B,它们拥有不同的数据。比如,企业 A A A有用户特征数据,而企业 B B B有产品特征数据和标注数据。这两个企业按照GDPR准则是不能粗暴地把双方数据加以合并的,因为数据的原始提供者,即他们各自的用户并没有机会来同意这样做。假设双方各自建立一个任务模型,每个任务可以是分类或预测,而这些任务也已经在获得数据时有各自用户的认可。那现在的问题是如何在 A A A和 B B B各端建立高质量的模型。但是,由于数据不完整(例如企业 A A A缺少标签数据,企业 B B B缺少特征数据),或者数据不充分(数据量不足以建立好的模型),那么,在各端的模型有可能无法建立或效果并不理想。联邦学习是要解决这个问题:各个企业的自有数据不出本地,而联邦系统可以通过加密机制下的参数交换方式,即在不违反数据隐私法规情况下,建立一个虚拟的共有模型。这个虚拟模型就好像大家把数据聚合在一起建立的最优模型一样。但是在建立虚拟模型的时候,数据本身不移动,也不泄露隐私和影响数据合规。这样,建好的模型在各自的区域仅为本地的目标服务。在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助大家建立了“共同富裕”的策略。这就是为什么这个体系叫做“联邦学习”。
上述实例阐述了联邦学习的基本思想,下文将规范联邦学习的定义,介绍联邦学习的公共价值和商业价值,并阐明联邦学习与现有研究的关系。为了进一步准确地阐述联邦学习的思想,我们将其定义如下:在进行机器学习的过程中,各参与方可借助其他方数据进行联合建模。各方无需共享数据资源,即数据不出本地的情况下,进行数据联合训练,建立共享的机器学习模型。
联邦学习系统的约束条件为:
∣ V FED − V SUM ∣ ≤ δ |\text{V}_\text{FED}-\text{V}_\text{SUM}| \leq \delta ∣VFED−VSUM∣≤δ
其中, V FED \text{V}_\text{FED} VFED为联邦学习模型的效果, V SUM \text{V}_\text{SUM} VSUM为传统方法(数据聚合方法)模型效果, δ \delta δ为有界正数。
参考文献:
[1] 杨强, 刘洋, 程勇, 康焱, 陈天健, 于涵. 联邦学习[M]. 电子工业出版社, 2020
[2] 微众银行, FedAI. 联邦学习白皮书V2.0. 腾讯研究院等, 2021