PointCNN: Convolution On X-Transformed Points
(一)论文地址:
https://arxiv.org/abs/1801.07791
(二)核心思想:
2D 图像中 CNN 的成功之处在于,利用图像网格中密集表示的数据(指像素)来表达空间局部相关性,但是对于在空间上无序并且密度不均匀的 3D 点云数据,直接使用 3D 卷积会导致形状信息的丢失和点排序的偏差;
为了解决这个问题,有的文章使用体素化(Minecraft 风格)来使数据对齐:
有的使用对称操作(如 PointNet):

而作者提出了一种新的策略,即 X -transformation,来实现与点相关联的输入特征的加权,并且将点排列成潜在的规范顺序;
(三)3D 卷积的不足:
空间局部相关是各种类型数据的普遍特性,与数据表示无关;
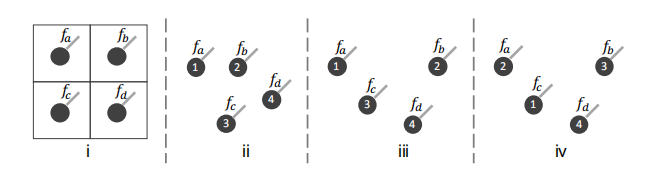
如图,对于在规范域内的数据(如图像 ),CNN 能够很好地学习到这些数据的局部相关性;
但是对于无序的、不平整的点云数据,卷积算子却不适合利用数据中的空间局部相关性;
例如图 ,假设它们都有相同的 维特征 ,使用相同的卷积核 得到的结果如下:
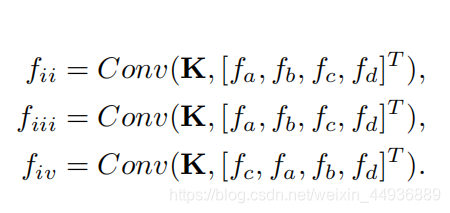
其中 两个是显然不同的点集,但是由于点集的无序性,它们得到的结果却可能相同;
同样 两个是相同的点集,得到的结果却不同;
这就说明卷积无法直接从无序的点集中,获取到点云的空间特征,也无法适应点集的排列;
(四)X-transformation:
为了解决卷积存在的不足,作者提出了可以使用一个 大小的 X-transformation 空间变换矩阵,目的是利用它同时对输入特征进行加权和排序,然后对变换后的特征进行典型卷积,作者称这个过程为 X-Conv;
使用 X-Conv 再处理上述点云特征得到的结果为:
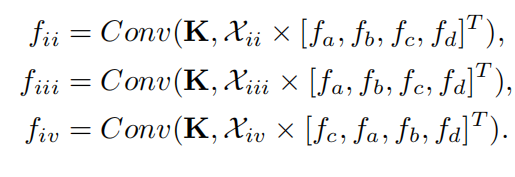
作者解释说:
- 因为 和 是从不同形状的不同点中学习得到的,所以对输入的不同特征有不同权重,因此使得 ;
- 因为
和
训练时是要求它们满足
,其中
是将
转换成 的置换矩阵,所以可以大致实现 ;
由上述分析可以得知,在理想情况下,变换矩阵 是能够把点云的形状考虑在内的,并且具有排序不变性;但是实际情况是作者发现, 变换矩阵和预想差的很远,尤其是在排序方面,但依然能够大幅改善卷积在处理点云方面的不足;
(五)PointCNN 的网络结构:
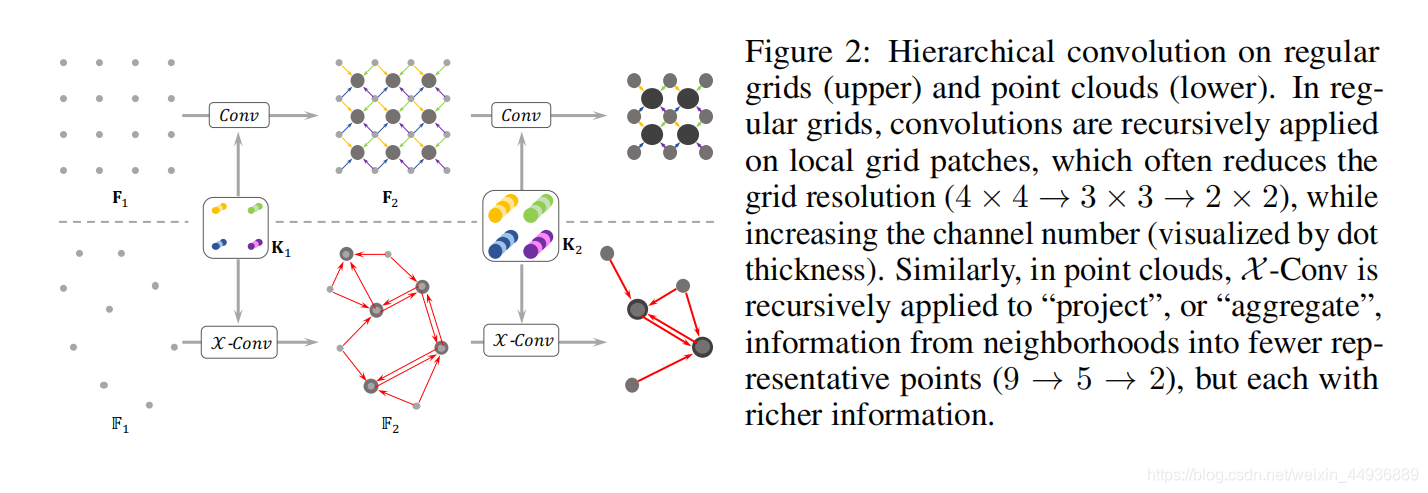
5.1 Hierarchical Convolution:
层级卷积是 CNN 提取特征的关键,因此作者在 PointCNN 中也采用了这种层级结构:
假设 X-Conv 的输入为:
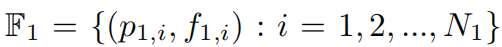
其中
是点集,
是点集对应的特征;
那么 X-Conv 的目标映射就是得到:
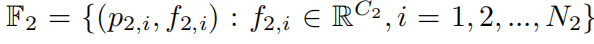
其中
是代表点的点集,
是代表点对应的特征;
通常要满足:
来得到聚合的高维特征;
而选取的代表点应该能够有效地表达信息“投影”或“聚合”,在分类任务中作者使用了随机下采样,而在分割任务中作者使用了最远点采样;
5.2 X-Conv 操作:
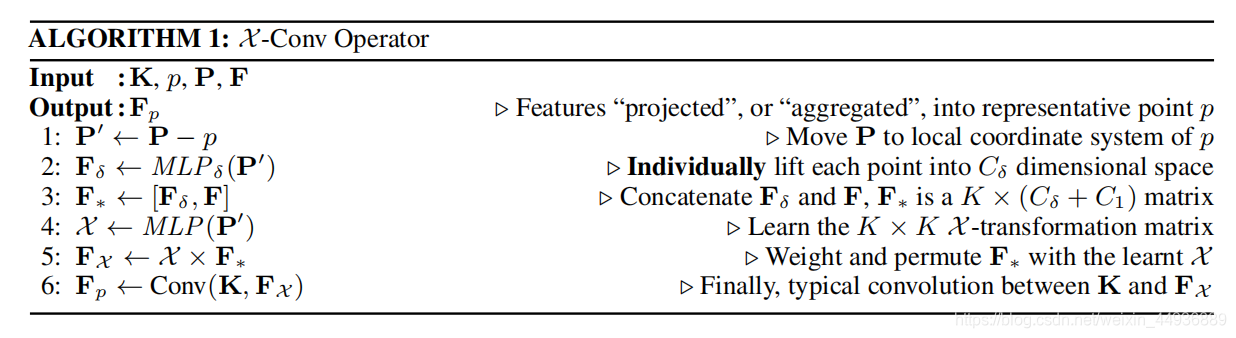
(也是中国人写的,,,为啥这么别扭呢)
这里再写一遍:
1:
得到点
相对于
的相对坐标;
2:使用多层感知机(MLP)将每个点分别提升到
维空间;
3:将
和
拼接起来得到一个
大小的
;
4:将
作为输入,使用多层感知机(MLP)训练或预测变换矩阵
;
5:应用
变换矩阵加权并置换
;
6:将
做卷积操作;
也可以简单地写作:
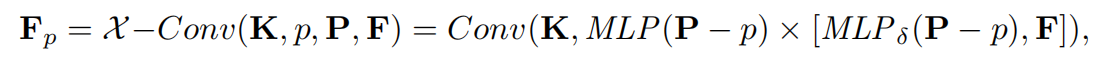
其中:
- 是选取的代表点集;
- 是 中每个点的 个邻近点;
5.3 网络结构:
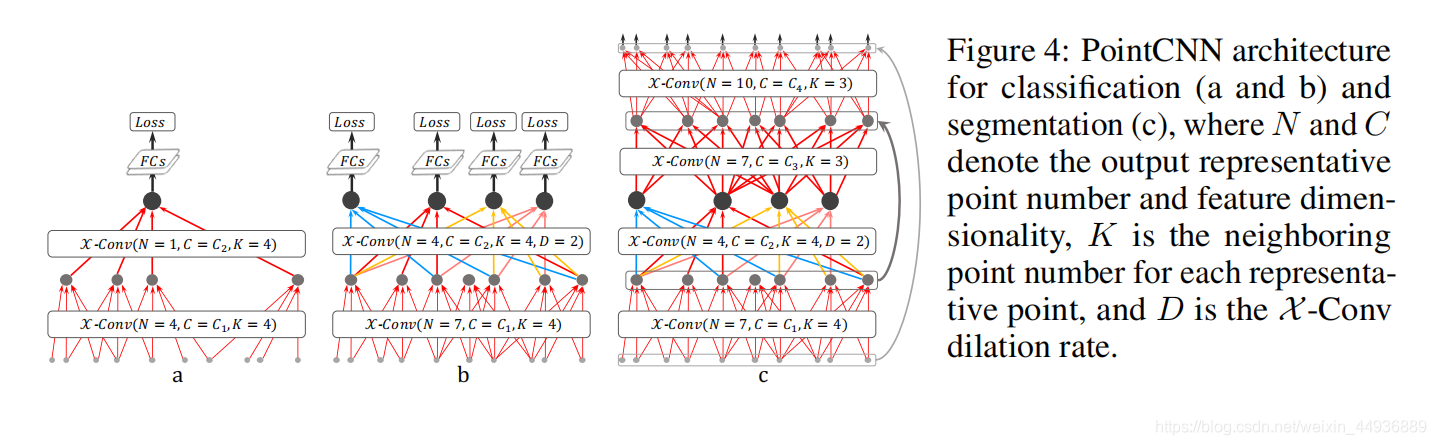
a 是一个简单的 X-Conv 搭建的两层网络,最后只剩下一个特征点用于分类的预测;
b 是改进的结构,由于 a 中选取特征点时会随即丢弃一些点,因此作者提出了一个更紧密的网络;
c 是用于分割任务的网络;
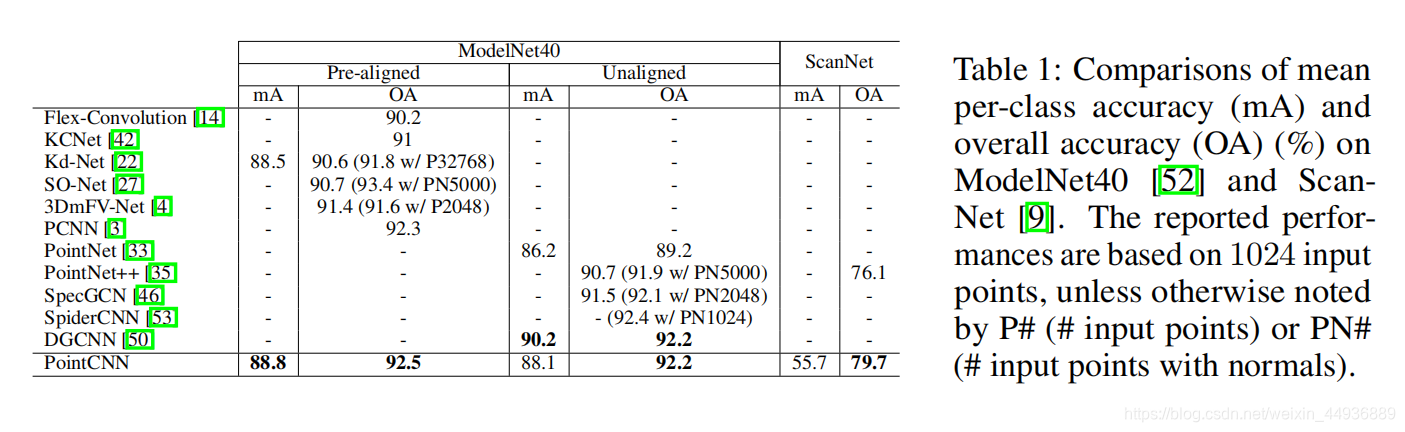
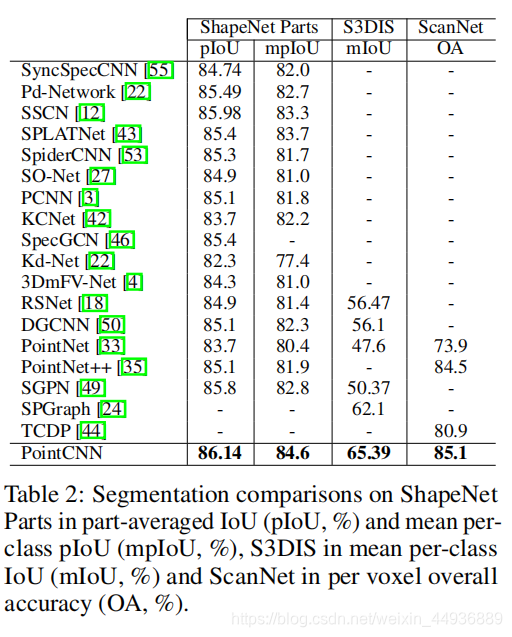
(六)实验结果: