Keras序列到序列学习十分钟介绍(翻译)
原文链接:A ten-minute introduction to sequence-to-sequence learning in Keras
文章目录
简单介绍如何使用Keras实现RNN之Seq2Seq学习。
本文假定,你对递归网络和Keras已经有了一定的了解。
序列到序列(sequence-to-sequenc,Seq2Seq)学习是什么?
Seq2Seq学习是训练将一个领域(如英文)的序列转换为另一种领域(如法语)的序列的模型的技术。
"the cat sat on the mat" -> [Seq2Seq model] -> "le chat etait assis sur le tapis"
这项技术可用于机器翻译或自由问答(为给定问题生成答案),甚至是需要生成文本的任何应用。
有很多方法可以完成这个任务,比如RNNs或1D convnets,这里我们只研究RNNs。
简单的情况:输入输出序列等长
当输入输出序列等长时,可以简单的使用Keras的LSTM或GRU层(或多层)实现这个模型。这个实例代码的案例展示了如何教会RNN学习加法,编码为字符串:
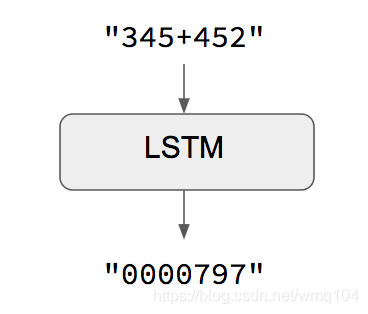
这种方法的限制是其假设了由输入input[…t]生成相同长度的输出target[…t]。它在特定情况如(数字字符串相加)可行,但在大部分情况都不可行。一般情况,开始生成目标序列时需要得到整个输入序列的信息。
一般情况:典型sequence-to-sequence
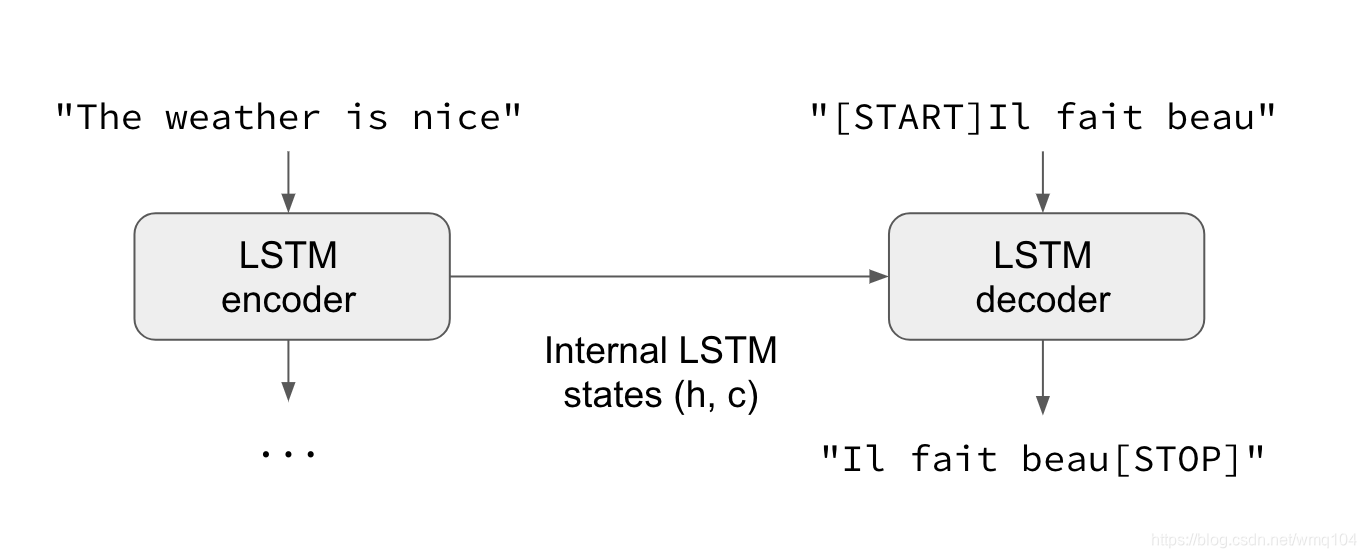
一般情况,输入序列和输出序列长度不同(如机器翻译)且开始预测目标前需要整个输入序列。这要求更先进的设置,这就是人们通常所说的“序列到序列模型”。其原理如下:
- 一个RNN层(或多层)作为编码器(encoder):其处理输入序列并返回其独有的内部状态。注意我们丢弃了解码RNN的输出,只获取其状态。这个状态将在下一步的解码器中作为“上下文”或“条件”。
- 另外一个RNN层(或多层)作为解码器(decoder):它被训练成给定目标序列的前一个字符时预测下一个字符。特别的,它被训练成将目标序列转换为偏移了一个时间步的相同序列,这里的训练过程被称为“teacher forcing”。重要的是,编码器用于输出状态向量作为初始状态,解码器从中获得它要生成什么内容的信息。最终,解码器学到在给定输入序列的条件下,由给定的targets[…t]生成targets[t+1…]。
以推理的方式,比如,当我们想解码未知的输入序列,需要略微不同的处理:
- 1)将输入序列编码为状态向量。
- 2)以大小为1的目标序列开始(仅仅是序列起始字符)。
- 3)将状态向量和1字符目标序列输入到解码器来预测下一个字符。
- 4)使用上述预测抽取下一个字符(本例简单使用argmax最大评分)。
- 5)将得到的字符插入到目标序列。
- 6)重复上述步骤,直到生成序列终止字符或达到字符上限。
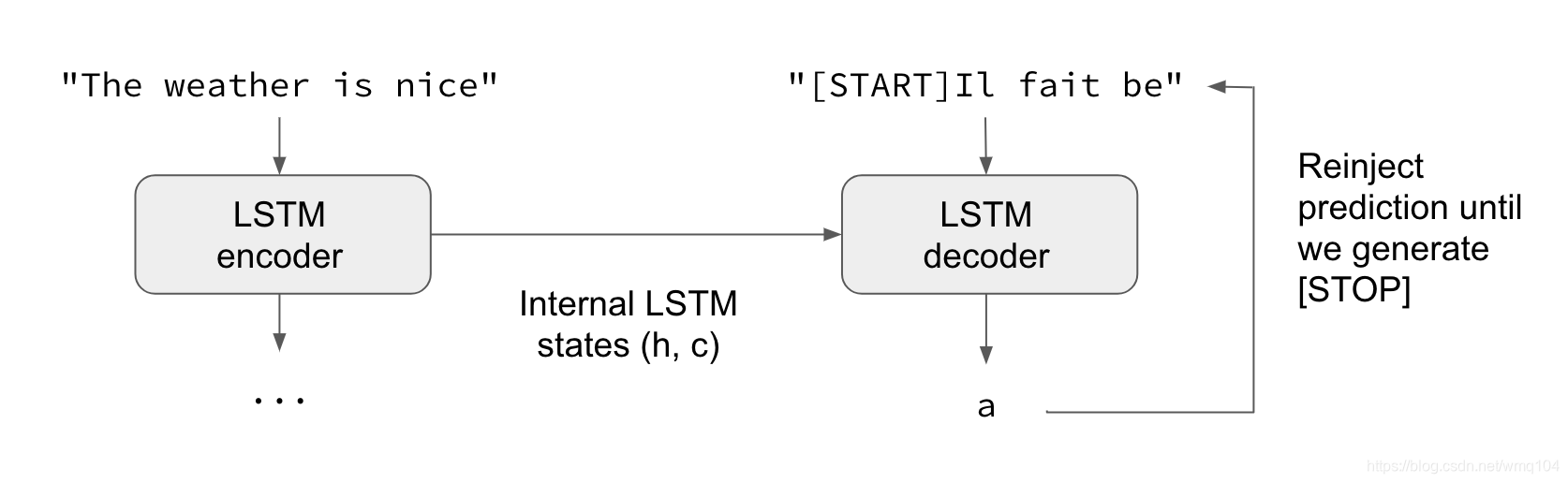
相同的处理也可以用于不使用“teacher forcing”的Seq2Seq网络,比如,将解码器预测注入解码器的方法。
Keras示例
使用实际代码举例。
本例的实现,使用了英语和法语翻译句子对的数据集,可以从 manythings.org/anki下载,文件名是 fra-eng.zip。本文将实现字符级序列到序列模型,按字符处理输入并生成输出。另一种选择是机器翻译领域应用更广泛的单词级模型。在本文最后,展示了使用嵌入层将本模型转换为单词级模型注解。
本例的完整代码可以在GitHub下载。
处理过程概述:
- 1)将句子转换为三个Numpy数组,encoder_input_data, decoder_input_data, decoder_target_data:
- encoder_input_data是大小是 (num_pairs, max_english_sentence_length, num_english_characters)的三维矩阵,包含英文句子的独热编码向量。
- decoder_input_data是大小为 (num_pairs, max_french_sentence_length, num_french_characters)的三维向量,包含法语句子的独热编码向量。
- decoder_target_data与decoder_input_data相同,但是包括一个时间步的位移, decoder_target_data[:, t, :] 与 decoder_input_data[:, t + 1, :]相同。
- 2)训练基于LSTM的基本Seq2Seq模型来使用 encoder_input_data和 decoder_input_data预测 decoder_target_data。本模型使用teacher forcing。
- 3)解码一些句子来验证模型的有效性。(如将 encoder_input_data中的样本专业为对应的 decoder_target_data样本)。
由于训练过程和推断过程(解码句子)差别很大,尽管其使用了相同的内部层,但是使用了不同的模型。
这是本文的训练模型,利用了Keras RNNs的三个关键特征:
- return_state构造函数参数,配置RNN层返回包括输出和RNN内部状态的列表,被用于获取编码器状态。
- inital_state调用参数,尤其是RNN的初始状态,用于将编码器状态传递到解码器作为初始状态。
- return_sequences构造函数参数,配置RNN返回全部输出(不止是默认的最终输出)。用于解码器。
from keras.models import Model
from keras.layers import Input, LSTM, Dense
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
用两行代码训练模型,同时使用预留的20%样本检测损失。
# Run training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
在苹果CPU上训练一个小时之后,我们进行推理。为了解码一个测试句子,要重复:
- 1)将输入句子编码并获取初始解码器状态。
- 2)使用初始状态和句子起始标志作为目标允许解码器一次。输出是下一个目标字符。
- 3)将预测的目标字符插入目标序列并重复。
推理配置如下:
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
使用如下代码实现上面描述的推理循环:
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, target_token_index['\t']] = 1.
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
if (sampled_char == '\n' or
len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
states_value = [h, c]
return decoded_sentence
由于测试集来源于训练集,所以结果比较好,并不奇怪。
Input sentence: Be nice.
Decoded sentence: Soyez gentil !
-
Input sentence: Drop it!
Decoded sentence: Laissez tomber !
-
Input sentence: Get out!
Decoded sentence: Sortez !
以上就是我们对Keras实现的seq2seq模型的十分钟简介。代码可以在GitHub下载。
参考文献:
- Sequence to Sequence Learning with Neural Networks
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
进一步问答:
如何使用GRU层替换LSTM层?
很简单,因为GRU只有一个状态,而LSTM有两个状态。如何调整模型使用GRU层如下所示:
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = GRU(latent_dim, return_state=True)
encoder_outputs, state_h = encoder(encoder_inputs)
decoder_inputs = Input(shape=(None, num_decoder_tokens))
decoder_gru = GRU(latent_dim, return_sequences=True)
decoder_outputs = decoder_gru(decoder_inputs, initial_state=state_h)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
如何对整型序列使用词级模型?
如果输入时整型序列(比如,使用词典索引编码的单词表征序列)?可以使用嵌入层对整型符号进行处理,如下所示:
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None,))
x = Embedding(num_encoder_tokens, latent_dim)(encoder_inputs)
x, state_h, state_c = LSTM(latent_dim,
return_state=True)(x)
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None,))
x = Embedding(num_decoder_tokens, latent_dim)(decoder_inputs)
x = LSTM(latent_dim, return_sequences=True)(x, initial_state=encoder_states)
decoder_outputs = Dense(num_decoder_tokens, activation='softmax')(x)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# Compile & run training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# Note that `decoder_target_data` needs to be one-hot encoded,
# rather than sequences of integers like `decoder_input_data`!
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
如果不想使用teacher forcing训练模型怎么办?
有些情况下不能使用teacher forching,因为无法得到完整的目标序列,例如,在线预测很长的以至于不能完整缓存输入-目标对的序列。这种情况下,你可能想在训练阶段就像推理阶段那样将解码器的预测值注入到解码器的输入中。
可以创建一个硬编码输出训练循环模型来实现:
from keras.layers import Lambda
from keras import backend as K
# The first part is unchanged
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
states = [state_h, state_c]
# Set up the decoder, which will only process one timestep at a time.
decoder_inputs = Input(shape=(1, num_decoder_tokens))
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
all_outputs = []
inputs = decoder_inputs
for _ in range(max_decoder_seq_length):
# Run the decoder on one timestep
outputs, state_h, state_c = decoder_lstm(inputs,
initial_state=states)
outputs = decoder_dense(outputs)
# Store the current prediction (we will concatenate all predictions later)
all_outputs.append(outputs)
# Reinject the outputs as inputs for the next loop iteration
# as well as update the states
inputs = outputs
states = [state_h, state_c]
# Concatenate all predictions
decoder_outputs = Lambda(lambda x: K.concatenate(x, axis=1))(all_outputs)
# Define and compile model as previously
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# Prepare decoder input data that just contains the start character
# Note that we could have made it a constant hard-coded in the model
decoder_input_data = np.zeros((num_samples, 1, num_decoder_tokens))
decoder_input_data[:, 0, target_token_index['\t']] = 1.
# Train model as previously
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
更多问题请见: reach out on Twitter.