导读
GPT-4在自然语言处理(NLP)任务中展现出了卓越的性能,其中包括具有挑战性的数学推理。然而,目前大部分已存在的开源模型仅仅在大规模互联网数据上进行了预训练,并且没有针对数学相关内容进行优化。本文介绍了一种名为WizardMath的方法:通过将“从Evol-Instruct反馈中强化学习(RLEIF)”的方法应用于数学领域,来增强Llama-2在数学推理方面的能力。该方法在两个数学推理基准(GSM8k和MATH)上进行了广泛实验,实验表明:WizardMath在所有其它开源LLMs上都有着显著的优势。此外,作者的模型甚至在GSM8k上超越了ChatGPT-3.5、Claude Instant-1、PaLM-2和Minerva,同时也在MATH上胜过了Text-davinci-002、PaLM-1和GPT-3。
引言
ChatGPT在大规模互联网数据上进行了广泛的预训练,并进一步通过特定指令数据和方法进行微调,因此它在各种基准测试中实现了非常优秀的zero-shot的能力。随后,Meta的一系列Llama模型引发了开源革命,并刺激了MPT8、Falcon、StarCoder、Alpaca、Vicuna 和WizardLM 等的发布。
然而,这些开源模型在需要复杂的多步定量推理的情况下仍然遇到困难,比如解决数学和科学难题。“Chain-of-thought” (CoT) 提出了设计更好的提示以生成逐步解决方案,这可以导致性能的改善。 “Self-Consistency” 在许多推理基准上也取得了显著的性能,它从模型生成多个可能的答案,并根据多数投票选择正确的答案。
最近的研究表明:对于解决具有挑战性的数学问题,使用强化学习的过程监督明显优于结果监督。
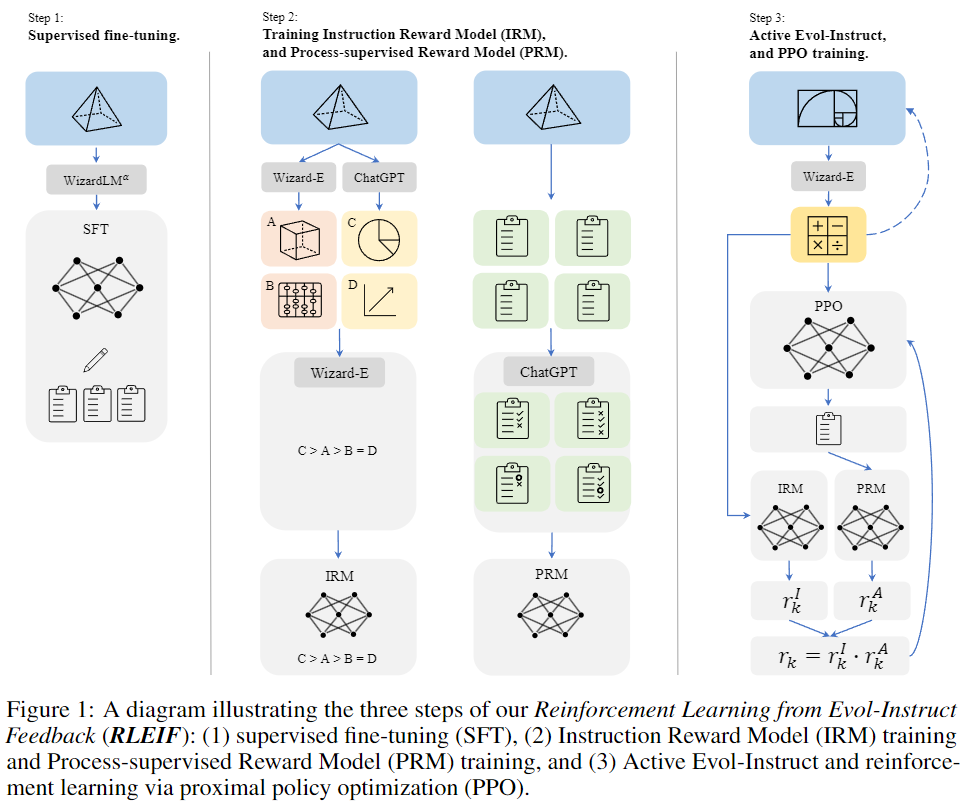
受Evol-Instruct和过程监督强化学习的启发,本文介绍一种名为RLEIF “从Evol-Instruct反馈中强化学习(RLEIF)”的新方法用于提高LLMs在数据逻辑推理方面的能力。如上图1所示:
- 该方法首先通过数学特定的Evol-Instruct生成多样的数学指令数据。
- 再训练一个指令奖励模型IRM和一个过程监督奖励模型PRM,前者表示进化指令的质量,后者为解决方案的每一步提供反馈。
- 最后通过IRM和PRM来进行PPO强化学习。
为了验证数学逻辑推理能力,作者在两个数学推理基准(GSM8k和MATH)上进行了实验,结果表明:本文的WizardMath在所有其它开源LLMs上表现出色,达到了SOTA水平。
本文主要贡献如下:
- 引入了WizardMath模型,该模型增强了开源预训练大型语言模型Llama-2在数学推理方面的能力。
- 提出了一种新方法,即从Evol-Instruct反馈中强化学习(RLEIF),结合Evol-Instruct和强化学习,提高了LLM的推理性能。
- 在GSM8k和MATH测试基准上,WizardMath在各个方面显著超越了其它所有开源的LLMs,包括Llama-2 70B 、Llama-1 65B 、Falcon-40B 、MPT-30B8、Baichuan-13B Chat9和ChatGLM2 12B。
- 在GSM8k上,WizardMath在pass@1方面显著超越了各种主要闭源LLM,如GPT-3.5、Claude Instant 、PaLM-2、PaLM-1和Minerva。
方法
本文提出了一种名为RLEIF的方法,该方法集成了Evol-Instruct和强化过程监督方法,用于进化GSM8k和MATH数据,然后通过进化的数据和奖励模型微调预训练的LLama-2模型。
如图1所示,我们的方法包括三个步骤:
Supervised fine-tuning(SFT)
继承InstructGPT的方法,我们首先使用监督的instruction-response指令对来微调基础模型,其中包含:
- 使用WizardLM 70B模型的Alpha版本重新生成了GSM8k和MATH的15k个答案,以逐过程的方式生成解决方案,然后找出正确答案,使用这些数据对基础Llama模型进行微调。
- 为了增强模型遵循多样指令的能力,本文还从WizardLM的训练数据中抽样了1.5k个开放领域对话,然后将其与上述数学语料库合并,作为最终的监督微调训练数据。
Evol-Instruct principles for math
受WizardLM提出的Evol-Instruct方法以及其在WizardCoder上的有效应用的启发,本研究试图通过制作具有不同复杂性和多样性的数学指令来增强预训练的LLMs。具体而言,我们将Evol-Instruct调整为一个新的范式,包括两条演化线:
- 向下演化:通过使问题变得更容易,增强了指令。例如:i)将高难度问题改为低难度问题,或者ii)通过其它不同的主题产生一个新的更容易的问题。
- 向上演化:从原始的Evol-Instruct方法演化而来。通过i)添加更多的约束条件,ii)具体化,iii)增加推理等方式,深化并生成更加困难的问题。
Reinforcement Learning from Evol-Instruct Feedback (RLEIF)
受到InstructGPT和PRMs的启发,作者训练了两个奖励模型来分别预测指令的质量和答案中每一步的正确性:
-
指令奖励模型(IRM):该模型旨在从三个方面判断进化指令的质量:i)定义,ii)精度,iii)完整性。为了生成IRM的排名列表训练数据,对于每个指令,作者首先使用ChatGPT和Wizard-E 4分别生成24个进化指令。然后利用Wizard-E对这48个指令的质量进行排名。
-
过程监督奖励模型(PRM):由于在这项工作之前没有强大的开源数学推理LLMs,因此没有简单的方法来支持高度精确的过程监督。因此,作者依赖于ChatGPT来提供过程监督,并要求其评估我们的模型生成的解决方案中每一步的正确性。
-
强化学习PPO训练。作者通过8轮进化原始的数学指令(GSM8k + MATH),将数据规模从15k增加到了96k。他们使用IRM和PRM生成指令奖励(rI)和答案奖励(rA)。然后将这两个奖励相乘,作为最终的奖励r = rI · rA。
实验
本文主要在两个基准测试GSM8k和MATH上评估WizardMath。GSM8k数据集包含大约7500个训练数据和1319个测试数据,主要涵盖小学阶段的数学问题,每个问题包括基本的算术运算(加法、减法、乘法和除法),通常需要2到8个步骤来解决。
MATH数据集收集了来自著名数学竞赛(如AMC 10、AMC 12和AIME)的数学问题。它包含7500个训练数据和5000个具有挑战性的测试数据,涵盖七个学术领域:初等代数、代数、数论、计数与概率、几何、中等代数和预微积分。此外,这些问题被分为五个难度级别,其中“1”表示相对较低的难度级别,“5”表示最高级别。
指标评估
::: block-1

在GSM8k基准测试中pass@1评估指标上,本文所提出的WizardMath模型目前位居前五,略微优于一些闭源模型,并在很大程度上超过了所有开源模型。
:::
::: block-1


在GSM8k和MATH上的pass@1结果对比。为了确保公平和一致性评估,本文在贪婪解码和CoT设置下报告了所有模型的分数,并报告了WizardMath与具有类似参数大小的基准模型之间的改进。可以发现:WizardMath采用更大的B数,效果提升显著,WizardMath-70B模型的准确度足以与一些SOTA的闭源LLMs相媲美。
:::
样例展示
下图展示了WizardMath在不同参数级的模型对于同一个Input的不同Response结果:
样例1



样例2


