
org.apache.spark.storage.DiskStore
if(length<minMemoryMapBytes){
valbuf=ByteBuffer.allocate(length.toInt)
channel.position(offset)
while(buf.remaining()!=0){
if(channel.read(buf)==-1){
thrownewIOException("ReachedEOFbeforefillingbuffer\n"+
s"offset=$offset\nfile=${file.getAbsolutePath}\nbuf.remaining=${buf.remaining}")
}
}
buf.flip()
Some(buf)
}else{
Some(channel.map(MapMode.READ_ONLY,offset,length))
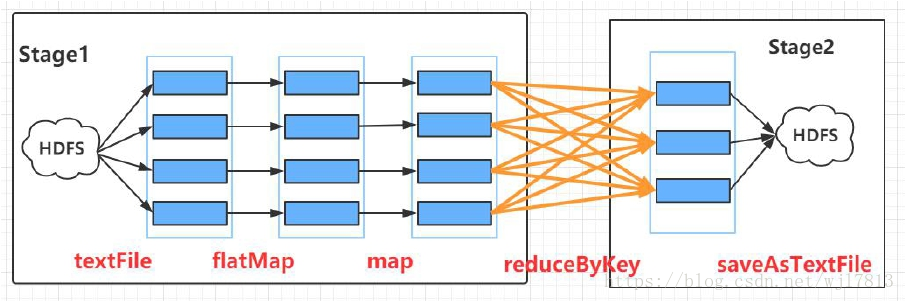
Spark SQL在执行聚合(即shuffle)时,默认有200个分区。
通过参数spark.sql.shuffle.partitions控制
分区数越小,ShuffleBlock的大小越大
非常大的数据量,默认的200分区数可能不够用
数据倾斜,导致少数分区的Block大小过大
=====基于SparkShuffleBlock的优化====
解决方案
在SparkSQL中,增加分区数,从而减少SparkSQL在shuffle时的Block大小
在SparkSQL中增加spark.sql.shuffle.partitions值
避免数据倾斜
在SparkRDD,设置repartiton、coalesce
rdd.repartiton()或rdd.coalesce()
如何确定分区数
经验法则:每个分区大小为128M左右
在shuffle时,当分区数大于2000和小于2000两种场景,Spark使用不同的数据结构保
存数据。
org.apache.spark.scheduler.MapStatus
defapply(loc:BlockManagerId,uncompressedSizes:Array[Long]):MapStatus={
if(uncompressedSizes.length>2000){
HighlyCompressedMapStatus(loc,uncompressedSizes)
}else{
newCompressedMapStatus(loc,uncompressedSizes)
}
}
分区数> 2000 VS 分区数<= 2000
建议:当Spark应用的分区数小于2000,但是很接近2000,将分
区数调整到比2000稍微大一点