对count查询进行优化
select count(*) from employees where id > 40000;
将其优化为下列语句
select (select count(*) from employees) - count(*) from employees where id <= 40000;
进行测试
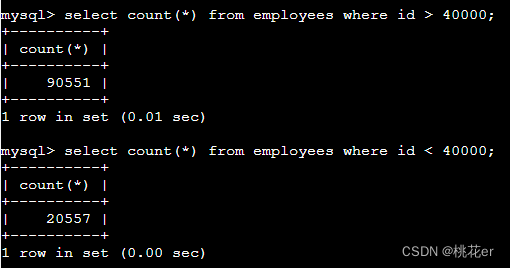
由于id>40000的数据有90551条,id<40000的数据有20557条,所以说如果进行一个相减的操作是否可以优化它呢?
InnoDB引擎
设计该employees表为InnoDB引擎,查看它的执行时间。
上面两条语句(15,16)是InnoDB引擎的执行

可以发现在将原语句修改后,执行时间由0.038s变为了0.050s,变慢了。这没优化到啊?
利用explain语句查看执行计划,发现原语句扫描了55493行数据,并且type类型为range,使用到了id_index索引。修改后的语句SUBQUERY的rows显示扫描了全表110986条数据,PRIMARY的rows扫描了19623行数据,意思也就是说在减号的左边count(*)也是做了全表扫描的,这样子根本不能优化。
原语句:

修改后的语句:

MyISAM引擎
将employees表修改为MyISAM引擎后,查看执行时间
上面两条语句(17,18)是MyISAM引擎的执行
可以发现在将原语句修改后,执行时间由0.034s变为了0.004s,变快了好多。
去查看执行计划
原语句:
MyISAM引擎默认是保存有一份count(*)的结果的,但是如果有where条件的话,MyISAM对其的操作是全表扫描。
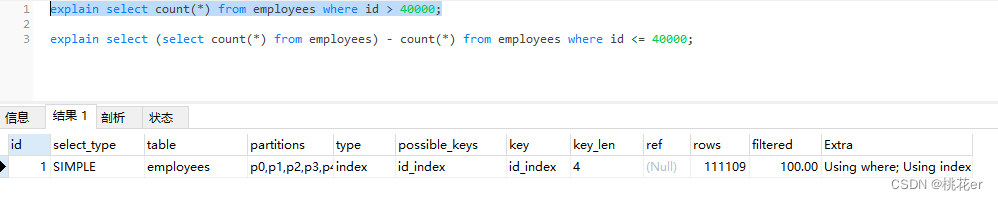
修改后的语句:

可以发现,扫描到的rows居然为1,这是因为MyISAM默认存有一份count(*),所以说,在MyISAM引擎下如果这样子去优化count(),可以大大的提高查询速度。