先看看Oracle SQL优化中关于COUNT的几条谣言:
1. COUNT(*)比COUNT(列)更慢!项目组必须用COUNT(列),不准用COUNT(*);
2. COUNT(*)用不到索引,COUNT(列)才能用到;
3. COUNT是统计出全表的记录,是吞吐量的操作,肯定用不到索引;
COUNT(*)和COUNT(列)哪个更快
这里测试一下:
连接数据库:
![]()
创建测试表:
drop table t purge;
create table t as select * from dba_objects;
--alter table T modify object_id null;
update t set object_id =rownum ;
set timing on
set linesize 1000
set autotrace on 先测试COUNT(*):

先只看这么两个指标:Cost是代价的意思,代价越高,性能也就越慢。还有就是consistent gets,逻辑读,越大性能也就越差。
再来测试COUNT(列)的情况(目前测试的这个列object_id并未建索引):
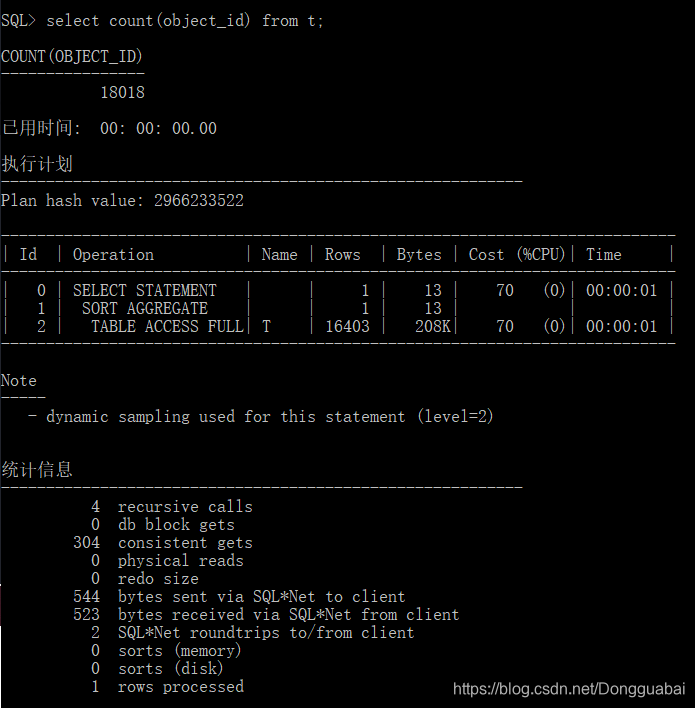
发现两个指标都跟上面COUNT(*)一样。看来COUNT(列)和COUNT(*)在这个列未建索引的情况下是一样的。
接下来跟object_id建立索引:

再COUNT(*)看看:

发现没什么变化,再COUNT(object_id)看看:

发现性能大幅度提升,也就是说在当前列有索引的情况下,COUNT(列)比COUNT(*)效率更高。
接下来指定object_id为非空:

再来执行COUNT(*):

COUN(*)的效率提高了!再来看看COUNT(列):
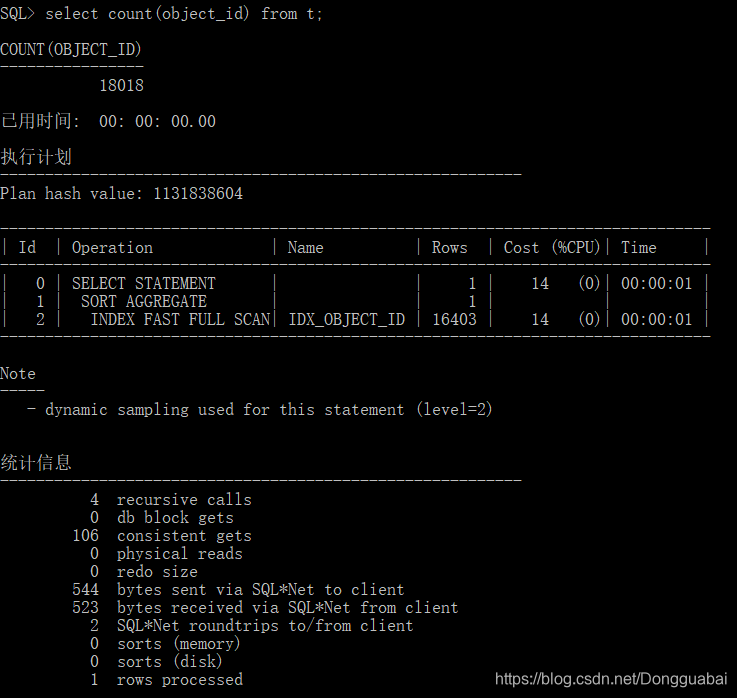
速度和COUNT(*)差不多,都很快。
这里是不是有点蒙蔽了。总得来说。COUNT(*)和COUNT(列)之前没有什么必然的联系,这两者都不是等价的,更谈不上比较了。COUNT(列)是当这一列所有数据不为空的时候,结果才和COUNT(*)是一样的,所以没有必要强制去比较两者的效率。
但是两者使用还是有要注意的地方的,参看《阿里巴巴Java开发手册》:
【强制】不要使用 count( 列名 ) 或 count( 常量 ) 来替代 count( * ) , count( * ) 就是 SQL 92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明: count( * ) 会统计值为 NULL 的行,而 count( 列名 ) 不会统计此列为 NULL 值的行。
使用COUNT(*)还有一个好处是不需要管列名是否存在。
COUNT每列的速度都一样吗
其实COUNT(列)每列的速度还是有差别的。
先执行测试脚本:
验证脚本1 (先构造出表和数据)
SET SERVEROUTPUT ON
SET ECHO ON
---构造出有25个字段的表T
DROP TABLE t;
DECLARE
l_sql VARCHAR2(32767);
BEGIN
l_sql := 'CREATE TABLE t (';
FOR i IN 1..25
LOOP
l_sql := l_sql || 'n' || i || ' NUMBER,';
END LOOP;
l_sql := l_sql || 'pad VARCHAR2(1000)) PCTFREE 10';
EXECUTE IMMEDIATE l_sql;
END;
/
----将记录还有这个表T中填充
DECLARE
l_sql VARCHAR2(32767);
BEGIN
l_sql := 'INSERT INTO t SELECT ';
FOR i IN 1..25
LOOP
l_sql := l_sql || '0,';
END LOOP;
l_sql := l_sql || 'NULL FROM dual CONNECT BY level <= 10000';
EXECUTE IMMEDIATE l_sql;
COMMIT;
END;
/
--验证脚本2(一次访问该表各字段验证)
execute dbms_stats.gather_table_stats(ownname=>user, tabname=>'t')
SELECT num_rows, blocks FROM user_tables WHERE table_name = 'T';
--以下动作观察执行速度,比较发现COUNT(*)最快,COUNT(最大列)最慢
DECLARE
l_dummy PLS_INTEGER;
l_start PLS_INTEGER;
l_stop PLS_INTEGER;
l_sql VARCHAR2(100);
BEGIN
l_start := dbms_utility.get_time;
FOR j IN 1..1000
LOOP
EXECUTE IMMEDIATE 'SELECT count(*) FROM t' INTO l_dummy;
END LOOP;
l_stop := dbms_utility.get_time;
dbms_output.put_line((l_stop-l_start)/100);
FOR i IN 1..25
LOOP
l_sql := 'SELECT count(n' || i || ') FROM t';
l_start := dbms_utility.get_time;
FOR j IN 1..1000
LOOP
EXECUTE IMMEDIATE l_sql INTO l_dummy;
END LOOP;
l_stop := dbms_utility.get_time;
dbms_output.put_line((l_stop-l_start)/100);
END LOOP;
END;
/t表为:

执行结果(第一个结果是COUNT(*),第二个结果是依次COUNT(列)):

制作成折线图如下:

大致来看COUNT(*)是效率最高的,越靠后的列时间越长。
结论:原来优化器里的算法是这么玩的,列的偏移量决定性能,列越靠后,访问的开销越大。由于count(*)的算法与列偏移量无关,所以count(*)最快,count(最后列)最慢。
所以在设计数据库表的时候不常访问的列可以放在靠后的位置。
参考资料: