
前几期我们介绍了常见的模糊测试工具、模糊测试的优势及异常发掘,本期我们就来聊一下模糊测试是如何准确定位问题的。我们知道模糊测试是一种通过向目标系统提供非预期的“坏数据”输入并监视异常结果来发现软件漏洞的方法,能否准确定位问题是模糊测试工具的重要考核指标,测试者必须能够知道使目标程序状态变化所对应的测试数据是什么,如果不具备重现测试结果的能力,那么整个过程就失去了意义。

准确定位问题是模糊测试的一个挑战性任务,因为模糊测试通常是基于黑盒测试的方法,无法直接查看内部源代码。然而,通过一些技巧和策略,可以在模糊测试中更准确地定位问题。
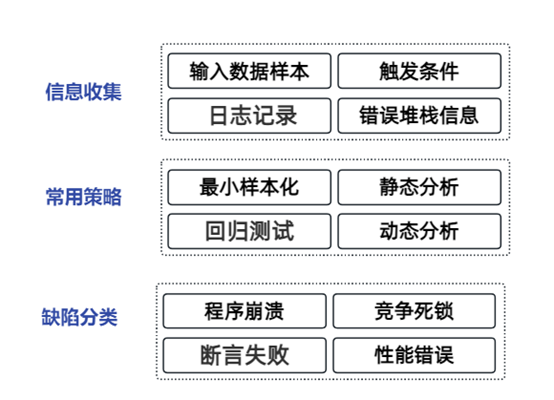
发现问题,收集信息
首先,当模糊测试运行后发现问题,关键是收集问题相关的信息。这些信息包括:
输入数据样本
收集导致问题的输入数据样本,这是重现问题的关键。尽可能保存多个触发问题的样本,因为不同的输入可能导致不同的问题。

触发条件
记录问题发生的环境和条件。这可能包括操作步骤、应用程序状态、用户角色等。触发条件有助于在后续的分析中重现问题。
错误信息和堆栈跟踪
如果应用程序崩溃或报错,就需要记录错误消息和堆栈跟踪信息。这些信息提供了关于问题所在位置的线索。
日志记录
如果应用程序生成日志文件,检查和保存与问题相关的日志。日志记录可能提供问题发生时的更多背景信息。
准确定位问题
一旦问题信息收集完毕,即可采取以下策略来准确定位问题。
最小复现样本
尝试从模糊测试中生成问题的最小复现样本,即一个能够触发问题的最简单的输入样本。有助于更快地重现问题,而不必依赖于模糊测试生成的大量输入。
静态分析
如果你有访问源代码的权限,可以使用静态代码分析工具来分析模糊测试发现的问题。这些工具可以帮助你定位问题的源代码位置,以及导致问题的潜在原因。
动态分析
使用调试器、性能分析工具和内存分析工具来观察程序的行为。这可能会揭示问题发生时的程序状态、数据流和内存情况。
输入数据分析
分析触发问题的输入数据,尤其是与问题相关的数据部分。这可能有助于确定问题的根本原因。
回归测试
修改程序以修复问题后,进行回归测试以确保修复不会引入新的问题。如果模糊测试生成了问题的输入样本,可以使用这些输入进行回归测试。
协作与共享
如果问题无法准确定位,可以将问题的信息和数据与开发团队共享,以寻求其他人的帮助。有时其他开发人员可能具有不同的视角和经验,有助于问题的定位。
需要强调的是,模糊测试可能会找到许多问题,其中一些可能是误报或低优先级的问题,定位问题需要耐心、技巧和实践。虽然模糊测试问题的准确定位具有挑战性,但结合静态分析、动态分析、输入数据分析以及协作,可以提高问题定位的准确性和效率,从而更好地解决软件中的安全问题。