算法模型极大的提升了对各类结果的预测效率。
【算法模型的本质】
算法模型的本质,是基于输入的各类变量因子,通过计算规则(模型or公式),得出预测结果。
典型的预测结果比如:
1.(通过历史行为&偏好预测)用户对某条信息点击的可能性
2.(通过历史行为&偏好预测)用户的自然人口属性如性别等
【如何判定模型的好坏】
准确率和召回率的评估,是验证算法模型好坏最常用的手段之一。
现在假设你和模型在玩问答游戏,每次拿一个样本,告诉他一些这个人的信息,让ta找出所有男生。
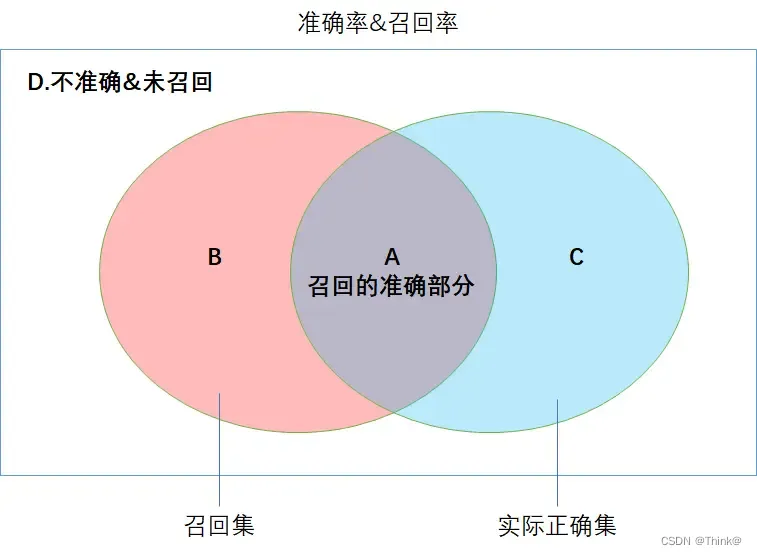
准确率=预测的准确量/召回量(找出量)。
比如:在所有样本中,模型预找出50人说他们都是男性,而找出的这波人里实际只有40人为男性,准确率=40/50=80%,用来衡量找出部分的准确度。
召回率=召回中的准确量/客观正确的量。
是拿真实的结果,和预测结果比对。比如:总共实际有60个男性,模型只找出了50个,那召回率=50/60=83.3%,用来衡量找出部分对实际真实部分的覆盖情况。
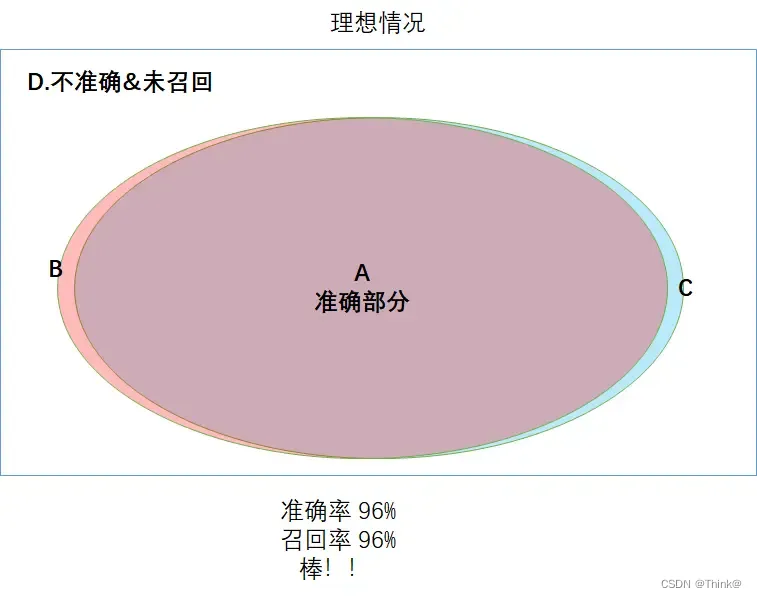
【准召判定,会有哪些情况?】
对预测结果的评估,于是就构成了以下四种集合。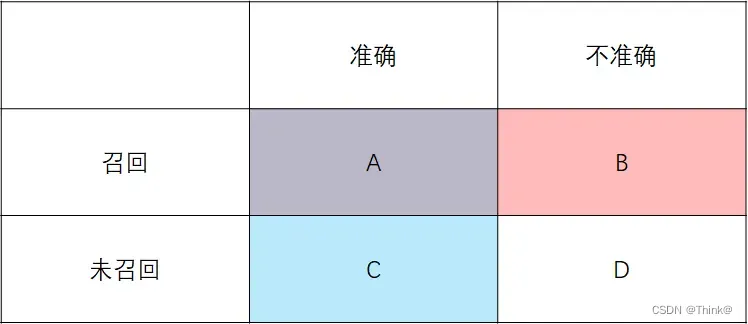
如下图所示,刚才4种集合,图形摊开的话,就是这个样子的。
下图展示了模型过度保守的情况。
模型可以很保守,准确率达到了100%,但由于过度追求准确,漏掉了大量正确的结果。

下图表示过度召回。
召回率100%,确保了正确的集合都被召回,但由于召回了大量错误集合,所以准确率很低。
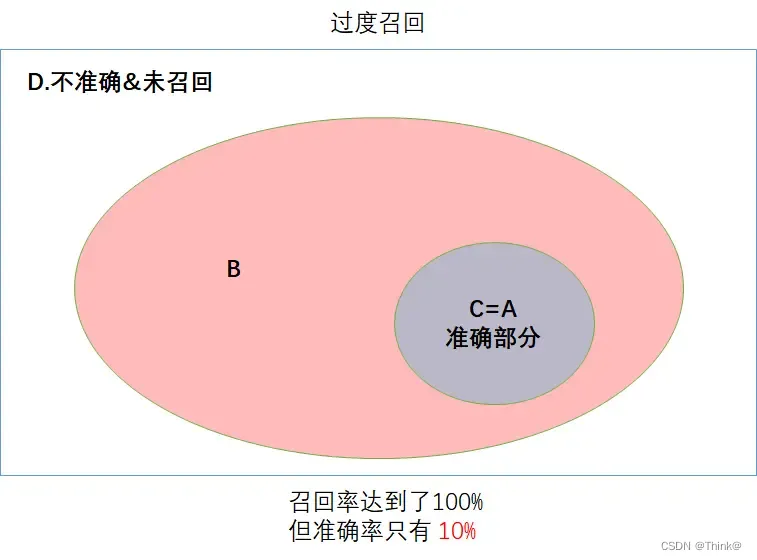
下图则表示理想情况——又多又准确!