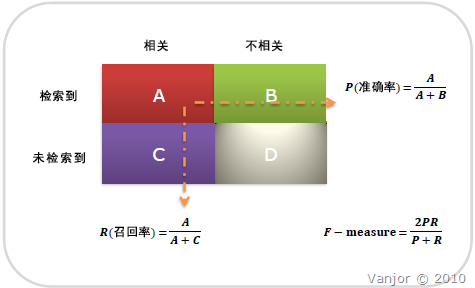
在信息检索、统计分类、识别、预测、翻译等领域,两个最基本指标是准确率和召回率,用来评价结果的质量。
准确率(Precision),又称“精度”、“正确率”、“查准率”,表示在检索到的所有文档中,检索到的相关文档所占的比例。
召回率(Recall),又称“查全率”,表示在所有相关文档中,检索到的相关文档所占的比率。
两者的公式为:
准确率 = 检索到的相关文档数量 / 检索到的所有文档总数
召回率 = 检索到的相关文档数量 / 系统中所有相关文档的总数
图示如下:
举例来说:一个数据库中有500个文档,其中有50个文档符合定义的问题。系统检索到75个文档,其中只有45个文档符合定义的问题。
准确率 = 45 / 75 = 60%
召回率 = 45 / 50 = 90%
若将所有文档都检索到,这些指标有何变化:
准确率 = 50 / 500 = 10%
召回率 = 50 / 50 = 100%
可见,准确率和召回率是相互影响的,理想情况下肯定是两者都高,但是一般情况下准确率高,召回率就低;召回率高,准确率就低;如果两者都低,那肯定是什么环节有问题了。
比如,在检索系统中,如果希望提高召回率,即希望更多的相关文档被检索到,就要放宽“检索策略”,便会在检索中伴随出现一些不相关的结果,从而影响到准确率。如果希望提高准确率,即希望去除检索结果中的不相关文档时,就需要严格“检索策略”,便会使一些相关文档不能被检索到,从而影响到召回率。
针对不同目的,如果是做搜索,那就是优先提高召回率,在保证召回率的情况下,提升准确率;如果做疾病监测、反垃圾,则是优先提高准确率,保准确率的条件下,提升召回率。
那么,在两者都要求高的情况下,如何综合衡量准确率和召回率呢?一般使用F值。
F-Measure是准确率(P)和召回率(R)的加权调和平均。公式为:
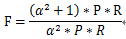
当参数α=1时,就是最常见的F1,即
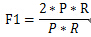
可见F1综合了P和R的结果,可用于综合评价实验结果的质量。
转自:https://blog.csdn.net/zyf89531/article/details/45922251
参考:https://www.cnblogs.com/li-daphne/p/6928681.html?utm_source=itdadao&utm_medium=referral