一,模块介绍
1,什么是模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。
模块让你能够有逻辑地组织你的 Python 代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
2,模块的导入方法
模块的导入方法大概有下面几种(我知道的几种)
1 import module_name #module_name为想要导入的模块名 2 import module1_name,module2_name, #导入多个模块 3 from module_name import * #导入模板下面的所有函数 4 from module_name import f1,f2 #导入模板下面的一些函数 5 from module_name import f1 as func1 #把导入的函数改一个名字
3,导入模块的本质
在模块导入就用到了import,首先讲一下import,import的本质就是搜索路径。导入模块的本质就是相当于把python文件解释一遍。导入包的本质就是执行该包下面的_init_.py文件。
4,模块的分类
模块可以分为三类:标准库,开源模块,自定义模块
二,时间模块(time,datetime)
1,time模块基本用法
在以前我们就用到过time模块,time肯定是跟时间相关的啊,下面会简单讲解一下time的一些基本用法,还是比较简单的,基本只要你记住就行了。


1 import time #导入模块 2 time.sleep(1) #睡眠好多秒 3 time.time() #时间戳(距离1970年多少秒) 4 time.localtime() #里面不加时间(秒),默认本地时间(输出的方式是元组) 5 #输出结果 6 #time.struct_time(tm_year=2018, tm_mon=6, tm_mday=18, tm_hour=21, tm_min=40, tm_sec=3, tm_wday=0, tm_yday=169, tm_isdst=0) 7 time.localtime(0) #里面输入的时间戳(距离1970好多秒),转化为元组形式 8 #输出结果 9 #time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=8, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0) 10 time.gmtime() #跟前面的time.localtime用法一样,不过默认的是世界时间,比中国少8小时 11 time.ctime() #返回当前时间,格式如下是Mon Jun 18 21:49:13 2018(星期几,月份,日期,具体时间,年份) 12 #执行结果:Mon Jun 18 21:49:13 2018 13 time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()) #把元组的时间按照自己设置的时间格式输出 14 #执行结果:2018-06-18 21:52:59 15 time.strptime('2018-06-18 21:52:59','%Y-%m-%d %H:%M:%S')#把设置的时间格式转化为元组格式 16 #执行结果:time.struct_time(tm_year=2018, tm_mon=6, tm_mday=18, tm_hour=21, tm_min=52, tm_sec=59, tm_wday=0, tm_yday=169, tm_isdst=-1)
在元组里面提到了一些tm_sec,tm_min等,下面就跟大家简单讲一下代表什么。
1 int tm_sec; /* 秒 – 取值区间为[0,59] */ 2 int tm_min; /* 分 - 取值区间为[0,59] */ 3 int tm_hour; /* 时 - 取值区间为[0,23] */ 4 int tm_mday; /* 一个月中的日期 - 取值区间为[1,31] */ 5 int tm_mon; /* 月份(从一月开始,0代表一月) - 取值区间为[0,11] */ 6 int tm_year; /* 年份,其值等于实际年份减去1900 */ 7 int tm_wday; /* 星期 – 取值区间为[0,6],其中0代表星期天,1代表星期一,以此类推 */ 8 int tm_yday; /* 从每年的1月1日开始的天数 – 取值区间为[0,365],其中0代表1月1日,1代表1月2日,以此类推 */ 9 int tm_isdst; /* 夏令时标识符,实行夏令时的时候,tm_isdst为正。不实行夏令时的时候,tm_isdst为0;不了解情况时,tm_isdst()为负。
下面是各种不同时间格式的相互转换关系,或者说是方法吧。
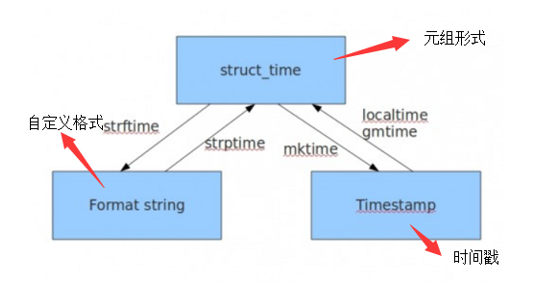
2,datetime模块基本用法
1 import datetime #导入模块 2 datetime.datetime.now() #返回当前时间 3 #执行结果:2018-06-18 22:06:11.479283 4 datetime.datetime.now()+datetime.timedelta(1) #当前时间的后面一天日期 5 datetime.datetime.now()+datetime.timedelta(-1) #当前时间的前面一天日期 6 datetime.datetime.now()+datetime.timedelta(hours=3)#当前时间后面三个小时 7 datetime.datetime.now()+datetime.timedelta(minutes=30)#当前时间后面三十
当然datetime模块还有一些其他的用法,因为我用得比较少,所以列举了这些,想要深入理解可以参考https://blog.csdn.net/cmzsteven/article/details/64906245
三,random模块
怎么说呢,random模块主要是用来做一些生成随机数啊,或者打乱一些东西啊,验证码就是用到了random模块,下面就来具体讲一下吧。
1 import random 2 random.random() #随机生成0-1的浮点数 3 #执行结果:0.3296961466292254 4 random.uniform(2,4)#生成指定范围的随机浮点数 5 #执行结果:2.1636220565899897 6 random.randint(1,5)#随机生成1-5的整数 7 #执行结果:4 8 random.randrange(1,5)#随机生成1-4的整数(顾头不顾尾) 9 #执行结果:1 10 random.choice("sadfsdfa154d")#从后面的序列中随机取一个 11 #执行结果:f 12 random.choices("sadfsdfa154d")#跟choice相同只是是列表形式 13 #执行结果:['1'] 14 random.sample('dfadfs',2) #在前面序列中随机选两个,返回列表形式 15 #执行结果:['s', 'd'] 16 17 #把序列随机打乱,改变原来的排序方式 18 a=['a','b','c','d'] 19 random.shuffle(a) 20 print(a) 21 #执行结果:['d', 'b', 'c', 'a']
在学了random模块,我们就可以写一个简单的验证码了。
1 import random 2 num='' 3 for i in range(4): 4 a=random.randint(0,3) 5 if i==a: 6 b=chr(random.randint(97,122)) #生成a-z的随机字母 7 else: 8 b=random.randint(0,9) #生成随机的数字 9 num+=str(b)#把生成的随机字符串加到num中 10 print(num)
四,os模块
Python的标准库中的os模块包含普遍的操作系统功能。如果你希望你的程序能够与平台无关的话,这个模块是尤为重要的。即它允许一个程序在编写后不需要任何改动,也不会发生任何问题,就可以在Linux和Windows下运行。下面是常见的os模块的常用操作。
1 import os 2 os.getcwd() #获取当前路径 3 os.chdir('E:\\flask_stu') #切换路径 4 os.curdir #当前目录,相当于. 5 os.pardir #上一个目录,相当于.. 6 os.makedirs('E:/zzq_python\day5/new_dir')#递归创建目录,即使不存在前面的目录 7 os.removedirs('E:/zzq_python\day5/new_dir') #删除文件,并清空空文件夹 8 os.mkdir('E:/zzq_python\day5/new_dir') #创建目录,必须前面的路径目录存在 9 os.rmdir('E:/zzq_python\day5/new_dir') #只删除最后一个目录 10 print(os.listdir('.')) #打印当前所在的所有目录 11 print(os.stat('E:\\flask_stu'))#打印文件的全部信息 12 print(os.environ) #显示环境变量 13 os.system('ipconfig/all')#在里面输入执行的命令,可以帮你运行里面的命令 14 print(os.path.dirname('E:\\flask_stu'))#获取父亲目录 15 print(os.path.basename('E:\\flask_stu'))#获取当前目录的名字 16 print(os.path.getatime('E:\\flask_stu'))#获取最后存取时间(时间戳的形式返回) 17 print(os.path.getmtime('E:\\flask_stu'))#获取最后修改时间(时间戳的形式返回) 18 print(__file__) #打印相对路径 19 print(os.path.abspath(__file__)) #打印绝对路径
讲到这里,前面讲了模块的导入方法,那如何实现同一目录下的两个文件下的模块相互调用呢。下面会简单讲到文件相互调用的方法,用到了很多os模块的东西。
1 import os,sys 2 abspath=os.path.abspath(__file__) #当前文件的绝对路径 3 father_dir=os.path.dirname(abspath)#获取父亲目录 4 grandfather_dir=os.path.dirname(father_dir)#获取祖父目录名 5 sys.path.append(grandfather_dir) #把改目录添加到环境变量中 6 from views import main #导入views目录下的main模块 7 main.test() #调用main里面的test函数
五,sys模块
由于用sys模块,我用的比较少,所以只有一些简单的操作。详细可以参考https://www.cnblogs.com/Archie-s/p/6860301.html
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称
六,hashlib模块
hashlib模块用于python中的加密操作,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法。相信有点计算机基础的都听过MD5算法吧,这些算法,其实是通过一定的计算方法把你的信息什么的通过算法然后得到一串加密的字符串,让别人就算获取到了你的信息,但是也不能知道信息的内容,增加了安全性。
1 import hashlib 2 m=hashlib.md5() #设置为md5加密方式,当然还有sha512,sha256等 3 m.update(b'I Love You') #必须是byte 4 print(m.hexdigest()) 5 m.update("高敏雪".encode())#记得encode一下 6 print(m.hexdigest()) #输出16进制加密的字符串 7 8 #这里需要注意的是你在继续update后面的内容实际是继续添加在后面,所以你分开两句加密。跟你两句合在一起加密的最后生成是相同的 9 x=hashlib.md5() 10 x.update("I Love You高敏雪".encode()) 11 print(x.hexdigest()) 12 13 #执行结果: 14 #cd2824bba5d2803793c0553c8f7c0bd1 15 #92617423012e40896671cc3416423da4 16 #92617423012e40896671cc3416423da4
七,json,pickle的序列化和反序列化
1.在讲就松跟pickle之前,我们可以先了解一下,什么是序列化和反序列化。
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
我们在python中的数据类型在python中能用,但是在java,c,c++等中都不能用了,但是想用都必须把对象先转化为标准格式,达到能过在各种语言中通用的效果。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。XML也是跟json差不多的,也是用来做标准格式的,但是没有json简单,好用,所以现在逐渐被json取代了。json跟pickle相比来说,json能够在各种语言中通用,但是pickle只能用于python。但是json只能对一些简单的数据类型等进行序列化,pickle能够对函数啊,类等等进行序列化。
Json模块提供了四个功能:dumps、dump、loads、load
json的序列化:
1 import json 2 info={ 3 'name':'zzq', 4 'age':21, 5 'sex':'man' 6 } 7 data=json.dumps(info)#把字典转化成字符串 8 with open('test.txt','w') as f: 9 f.write(data)
执行结果:

json的反序列化:
1 import json 2 with open('test.txt','r') as f: 3 data=json.loads(f.read()) #把序列化的字符串转化为原来的字典 4 print(data['name'])
执行结果:

3,pickle的基本用法
pickle的用法跟json的用法是一样的,只是唯一一点有区别的就是使用的范围不同。
1 import pickle 2 #序列化 3 def info(): 4 print('this is info') 5 with open('test.txt','wb') as f: 6 #pickle.dump(info(),f)=f.write(pickle.dumps(info())) 7 data=f.write(pickle.dumps(info())) 8 #反序列化 9 with open('test.txt','rb') as f: 10 pickle.loads(f.read())
八,re模块
在学到re模块的时候,基础知识比较简单,但是可扩展性很强,如果想学爬虫的小伙伴可以认真的研究一些这个re模块,因为爬虫的一个匹配会用到正则匹配相关的知识。下面就开始re模块的基本介绍吧。
1 '^' #匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) 2 '$' #匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以 3 '\A' #只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的 4 '\Z' #匹配字符结尾,同$ 5 '.' #默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 6 '*' #匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a'] 7 '+' #匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] 8 '?' #匹配前一个字符1次或0次 9 '{n}' #匹配前一个字符n次 10 '{n,}' #匹配前一个字符n次或者更多次 11 '{n,m}' #匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] 12 '|' #匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' 13 '(...)' #分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c 14 '\w' #匹配[A-Za-z0-9] 15 '\W' #匹配非[A-Za-z0-9] 16 's' #匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' 17 '(?P<name>...)' #分组匹配,name相当于key,后面的约束就是匹配的内容
下面是我当时练习,用自己的话解释的,因为懒,所以直接放的图片。。。
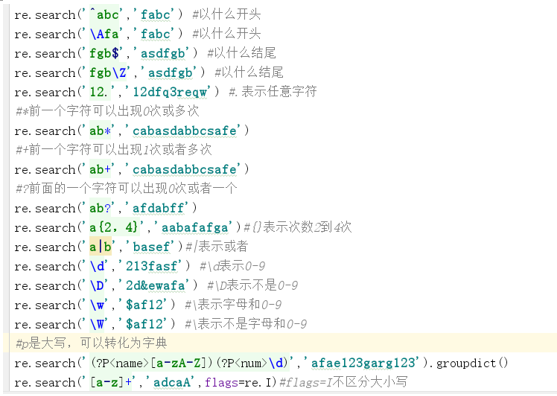
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
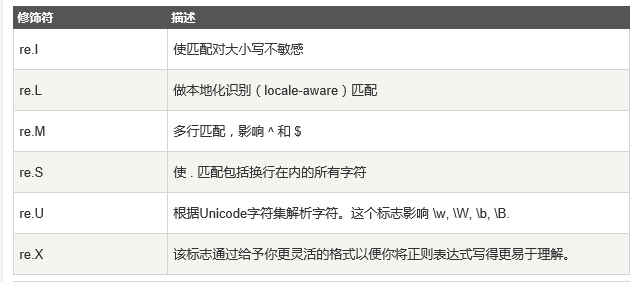
当然是在里面加flages=re.I等
当然有时候你遇到了比如我里面有一个\d但是我要的就是\d不是表示的数字,因为\是被当做转义字符了。下面就有两种解决方式。一个是在前面再加一个\比如\\d,还有一种方法就是r"\d"。
前面基本介绍完了正则里面的一些规则等,下面re还有五中方法。
1 re.match #头开始匹配 2 3 re.search #匹配包含 4 5 re.findall #把所有匹配到的字符放到以列表中的元素返回 6 7 re.splitall #以匹配到的字符当做列表分隔符 8 9 re.sub #匹配字符并替换
下面是我自己语言总结的使用跟理解方法

最后一个re.sub可能大家没懂我的意思,其实就是最前面的[0-9]+就是在字符串中查找的要求,然后匹配的结果换成后面那个A,第三个就是字符串,如果加count=1表示只替换一个,不加全部替换。
后面还有一些补充的就是,re中的?具有惰性匹配的性质。什么叫惰性匹配呢,惰性匹配模式是尽可能少的匹配字符,但是必须要满足正则表达式的匹配规则。还有就是如果没有匹配的字符,默认返回是None。
惰性限定符列表

如果你想深入理解,可以参考http://www.runoob.com/python/python-reg-expressions.html
当然,re模块是比较好玩,我们学完re模块还能自己写一个简单的计算器,比如别人输入一个类似下面这种式子(5+7*4(4+8)-7*2+(51+12*4(4*4-5)))叫你计算,你能写一个程序来达到这个效果嘛,哈哈,我也写写看,写出来就会在后面的博客分享给大家。