1、time模块:
与时间相关的功能,在Python分为三种
1、时间戳 timestamp 从1970年1月1日到现在的秒数。
import time
print(time.time())
start_time=time.time()
time.sleep(3)
stop_time=time.time()
print(stop_time-start_time
1533802804.4700184
3.0006344318389893
2、格式化的字符串
print(time.strftime('%Y-%m-%d %H:%M:%S %p'))
print(time.strftime('%Y-%m-%d %X %p'))
2018-08-09 16:22:29 PM
2018-08-09 16:22:29 PM
3、struct_time对象
print(time.localtime()) # 上海:东八区
print(time.localtime().tm_year)
print(time.localtime().tm_mday)
print(time.gmtime()) # UTC时区
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=9, tm_hour=16, tm_min=24, tm_sec=46, tm_wday=3, tm_yday=221, tm_isdst=0)
2018
9
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=9, tm_hour=8, tm_min=24, tm_sec=46, tm_wday=3, tm_yday=221, tm_isdst=0)
4、了解的知识
print(time.localtime(1111111111).tm_hour)
print(time.gmtime(1111111111).tm_hour)
print(time.mktime(time.localtime()))
print(time.strftime('%Y/%m/%d',time.localtime()))
print(time.strptime('2017/04/08','%Y/%m/%d'))
print(time.asctime(time.localtime()))
print(time.ctime(12312312321))
9
1
1533803206.0
2018/08/09
time.struct_time(tm_year=2017, tm_mon=4, tm_mday=8, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=5, tm_yday=98, tm_isdst=-1)
Thu Aug 9 16:26:46 2018
Mon Feb 29 22:45:21 2360
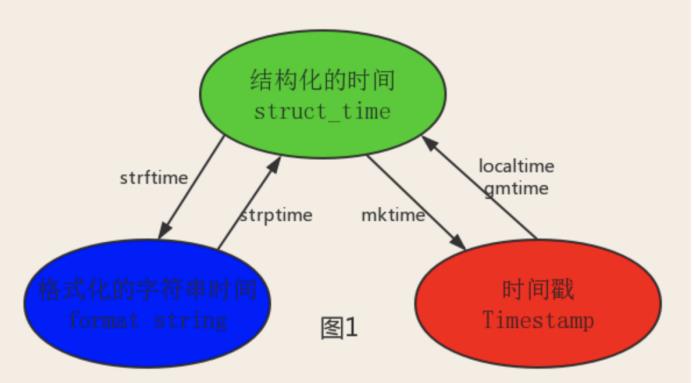
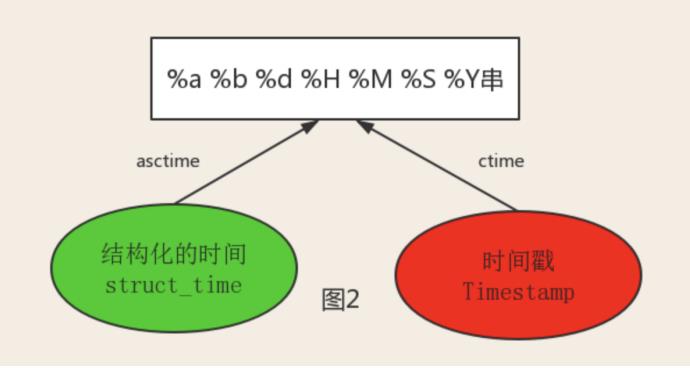
2、datetime模块
import datetime
print(datetime.datetime.now())
print(datetime.datetime.now() + datetime.timedelta(days=3))
print(datetime.datetime.now() + datetime.timedelta(days=-3))
print(datetime.datetime.now() + datetime.timedelta(hours=3))
print(datetime.datetime.now() + datetime.timedelta(seconds=111))
current_time=datetime.datetime.now()
print(current_time.replace(year=1977))
print(datetime.date.fromtimestamp(1111111111))
print(datetime.date.fromtimestamp(time.time()) )
#时间戳直接转成日期格式 2018-04-08
2018-08-09 16:31:14.425770
2018-08-12 16:31:14.425770
2018-08-06 16:31:14.425770
2018-08-09 19:31:14.425770
2018-08-09 16:33:05.425770
1977-08-09 16:31:14.425770
2005-03-18
2018-08-09
4、random模块
import random
print(random.random()) #0,1;大于0且小于1之间的小数
print(random.randint(1,3)) #大于等于1且小于等于3之间的整数
print(random.randrange(1,3)) #大于等于1且小于3之间的整数
print(random.choice([1,'a',[1,2,3]])) #从定义的列表中随机选取
print(random.sample([1,2,3,4,5],3)) #列表中元素任选(3)个数
print(random.uniform(1,3)) #大于1小于3的小数
item=[1,3,5,7,9]
random.shuffle(item) #打乱item的顺序相当于洗牌
print(item)
0.14770779668960876
1
1
a
[4, 1, 3]
2.7205065342128867
[1, 5, 3, 9, 7]
5、shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
import shutil
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
shutil.copy(src, dst)
拷贝文件和权限
import shutil
shutil.copy('f1.log', 'f2.log')
shutil.copy2(src, dst)
拷贝文件和状态信息
import shutil2 3 shutil.copy2('f1.log', 'f2.log')
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
import shutil
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc',
'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的
思是排除
拷贝软连接
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
import shutil
shutil.rmtree('folder1')
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
import shutil
shutil.move('folder1', 'folder3')
shutil.make_archive(base_name, format,...)
l 创建压缩包并返回文件路径,例如:zip、tar
l 创建压缩包并返回文件路径,例如:zip、tar
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前
录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/
format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
owner: 用户,默认当前用户
group: 组,默认当前组
logger: 用于记录日志,通常是logging.Logger对象
6、sys模块

7、什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,'状态'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
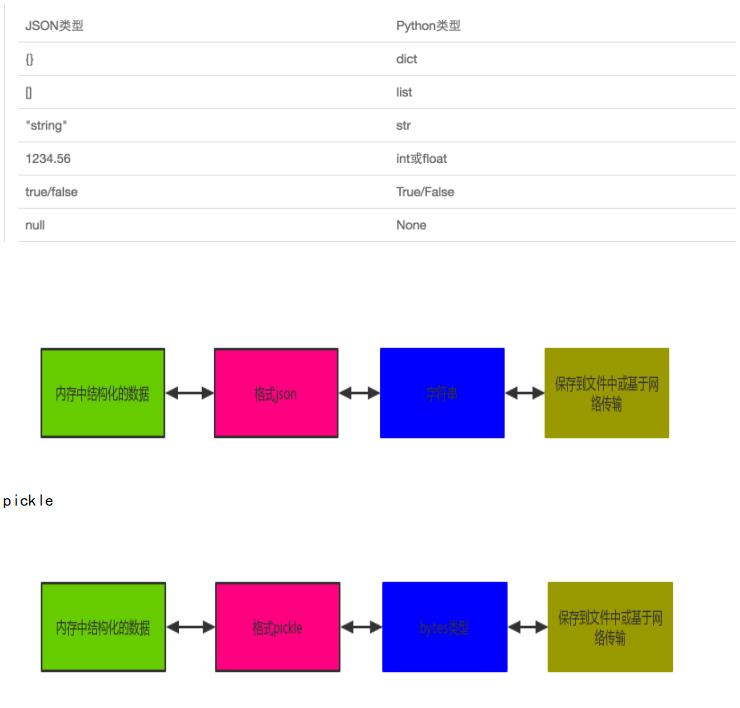
如何序列化之json和pickle:
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
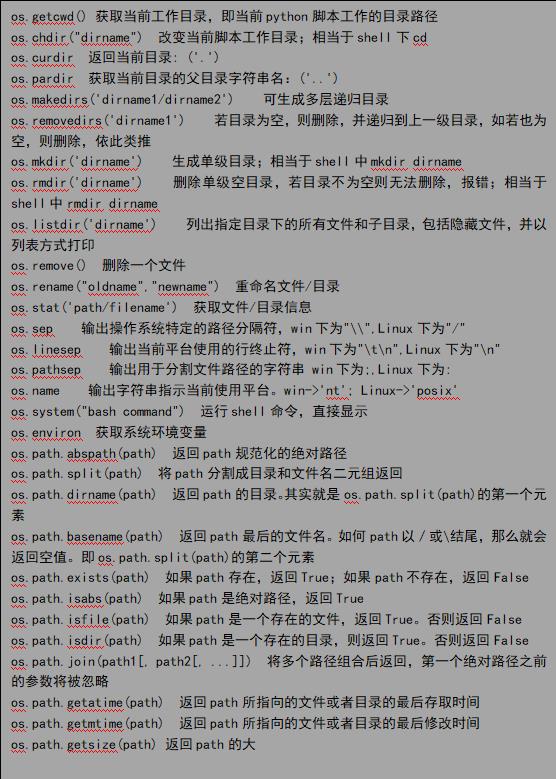
8、三 os模块
os模块是与操作系统交互的一个接口