前言
思索了很久到底要不要出深度学习内容,毕竟在数学建模专栏里边的机器学习内容还有一大半算法没有更新,很多坑都没有填满,而且现在深度学习的文章和学习课程都十分的多,我考虑了很久决定还是得出神经网络系列文章,不然如果以后数学建模竞赛或者是其他更优化模型如果用上了神经网络(比如利用LSTM进行时间序列模型预测),那么就更好向大家解释并且阐述原理了。但是深度学习的内容不是那么好掌握的,包含大量的数学理论知识以及大量的计算公式原理需要推理。且如果不进行实际操作很难够理解我们写的代码究极在神经网络计算框架中代表什么作用。不过我会尽可能将知识简化,转换为我们比较熟悉的内容,我将尽力让大家了解并熟悉神经网络框架,保证能够理解通畅以及推演顺利的条件之下,尽量不使用过多的数学公式和专业理论知识。以一篇文章快速了解并实现该算法,以效率最高的方式熟练这些知识。
现在很多竞赛虽然没有限定使用算法框架,但是更多获奖的队伍都使用到了深度学习算法,传统机器学习算法日渐式微。比如2022美国大学生数学建模C题,参数队伍使用到了深度学习网络的队伍,获奖比例都非常高,现在人工智能比赛和数据挖掘比赛都相继增多,对神经网络知识需求也日渐增多,因此十分有必要掌握各类神经网络算法。
博主专注建模四年,参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。此专栏的目的就是为了让零基础快速使用各类数学模型、机器学习和深度学习以及代码,每一篇文章都包含实战项目以及可运行代码。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全代码。希望有需求的小伙伴不要错过笔者精心打造的专栏。
这里损失函数并没有新开一篇文章细讲,是因为之前已经有一篇文章详细讲述了所有的损失函数形式以及实现代码和功能,推荐大家细读:损失函数(Loss Function)一文详解-分类问题常见损失函数Python代码实现+计算原理解析_fanstuck的博客-CSDN博客
还是简单的提一嘴让大家印象深刻一下,损失函数就是用以衡量实际值和预测值在当前位置的差值或误差,这提高了一些模型的有效性,通过向模型提供反馈,使其可以调整参数以最大程度减少误差。
当我们训练神经网络时,我们使用损失函数来度量模型预测值与真实值之间的差距。这个差距通常被称为误差或损失。我们的目标是通过调整模型的权重和参数,使损失函数的值最小化。换句话说,我们试图找到一组权重和参数,使得模型的预测结果尽可能接近真实值。
损失函数的值越小,意味着模型的预测与实际数据之间的差异越小,模型的性能越好。优化的过程就是通过反向传播和梯度下降等方法,逐步调整模型的权重和参数,以降低损失函数的值。
一、随机初始化
随机初始化的方式大家应该很好理解,我们可以一开始随机尝试很多不同的权重试一下,然后看看哪个权重集合的效果最好,听起来虽然很笨但确实很笨,这里仅作引入,实际不要采用此方法:
accuracy_cnt=0
batch_size=100
x = test_dataset.test_data.numpy().reshape(-1,28*28)
labels = test_dataset.test_labels
finallabels = labels.reshape(labels.shape[0],1)
bestloss = float('inf')
for i in range(0,int(len(x)),batch_size):
network = init_network()
x_batch = x[i:i+batch_size]
y_batch = forward(network,x_batch)
one_hot_labels = torch.zeros(batch_size,10).scatter_(1,finallabels[i:i+batch_size],1)
loss = cross_entropy_error(one_hot_labels.numpy(),y_batch)
if loss < bestloss:
bestloss = loss
bestw1,bestw2,bestw3 = network['W1'],network['W2'],network['W3']
print("best loss: is %f" %(bestloss))那么我们再来看看准确率的效果如何:

a1=x.dot(bestw1)
z1=_relu(a1)
a2=z1.dot(bestw2)
z2=_relu(a2)
a3=z2.dot(bestw3)
y=_softmax(a3)
print(y)
#找到在每列中评分最大的索引
Yte_predict=np.argmax(y,axis=1)
one_hot_labels=torch.zeros(x.shape[0],10).scatter_(1,finallabels,1)
true_labels=np.argmax(one_hot_labels.numpy(),axis=1)
#计算准确率
print(np.mean(Yte_predict==true_labels))最后的输出结果为:
0.0948
差不多也正常和猜的概率一样。
二、梯度下降法
梯度下降法之前我有一篇文章专门写了此最优化算法,之前在写逻辑回归的算法时也用到过,想要详细了解的推荐细读,此篇文章仅详细讲述在反向传播中梯度下降算法的功能功能:
一文速学数模-最优化算法(二)梯度下降算法一文详解+Python代码
神经网络的学习也要求梯度,这里的梯度说表示的是损失函数中关于权重以及偏移量(bias)的梯度。比如一个形状为2*2的权重为W的神经网络,损失函数用L表示:
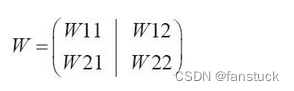
其梯度表示为:

的元素由各个元素关于W的偏导数构成。对于每一个偏导数,其表示的意义是,当每个W稍微变化的时候,损失函数L会发生多大的变化。
#基于数值微分的梯度下降法
def numerical_gradient(f,x):
h = 1e-4 #0.0001
grad = np.zeros_like(x)
it = np.nditer(x,flags=['multi_index'],op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val)+h
fxh1 = f(x) #f(x+h)
x[idx] = tmp_val-h
fxh2 = f(x) #f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val #还原值
it.iternext()
return grad之后经过初始重置权重数据集后,使用梯度下降算法的权重集合为:

损失函数值:

了解到了梯度下降算法以及工作原理,那么我们就可以开始反向传播的研究了。