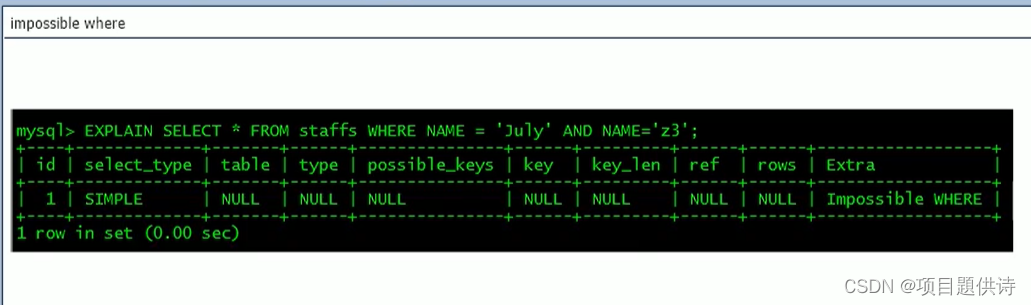
(1)explain之ref介绍
type下的ref是非唯一性索引扫描具体的一个值
ref属性

例如:ti表先加载,const是常量 t1.other_column是个t1表常量
test.t1.ID:test库t1表的ID字段
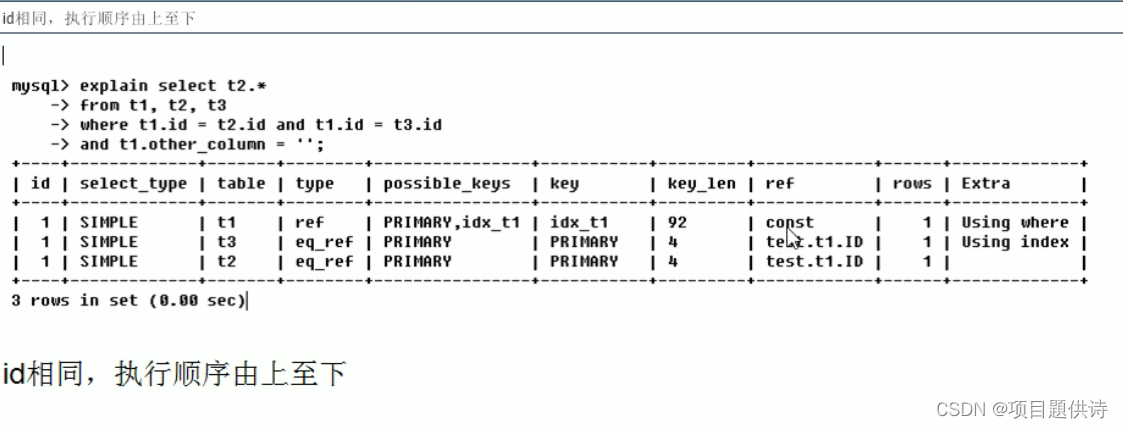

t1表引用了shared库的t2表的col1字段,t1.col2=‘’ac‘’是一个常量 t2表没有索引只有id主键,col1,col2没有建立索引

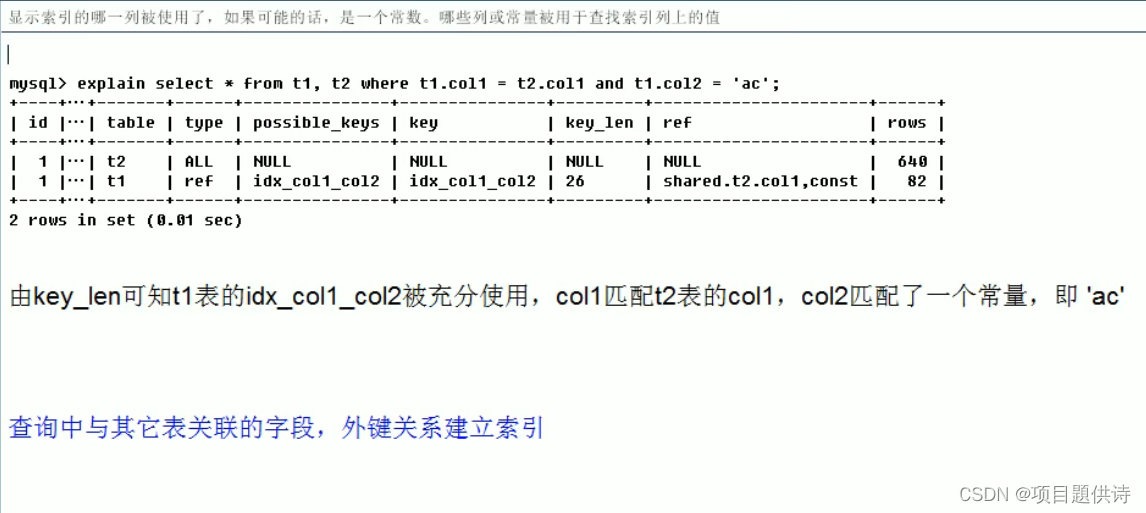
(2)explain之rows介绍


rows越少越好!
t2开始没有索引t2理论上用到主键索引,但是实际上没用到 ,rows为640+1,然后加索引后,rows变为142+1
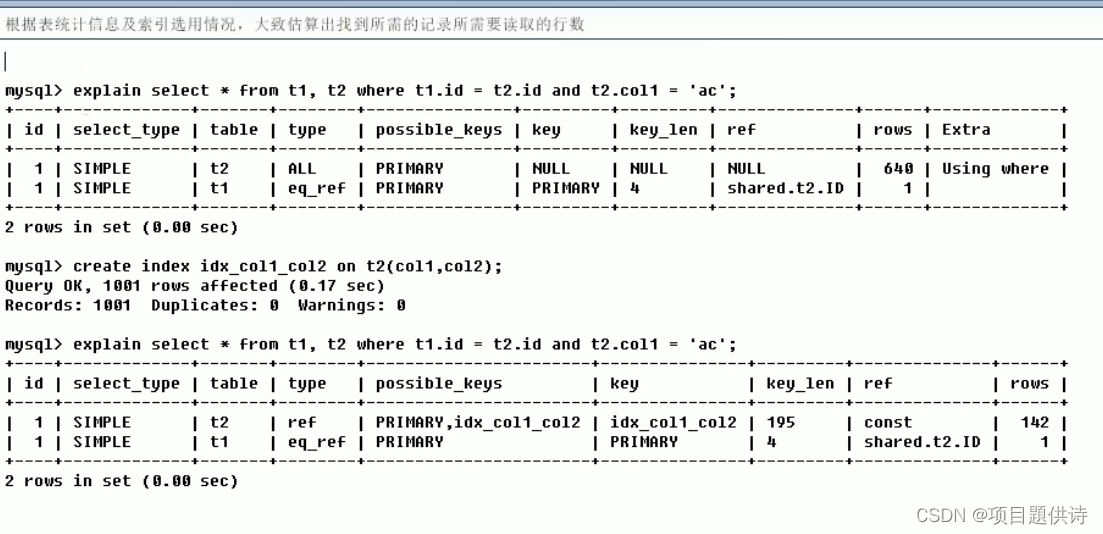
所以呢,我们需要先会看explain优化查询,需要先会看 ,最终优化的效果是把不合适的索引删除,逐渐建立索引,建立最符合我们系统的,这样我们MySql数据库跟我们系统跑起来就是最好的!
(3)explain之Extra介绍
explain中重要的几个字段:id type key rows Extra这几个是最重要的



加了\G是竖着排列
第一个sql没有按照创建的索引走,我自己在内部产生了一次排序,使用了Using filesort文件排序
第二个sql按照创建的索引走,性能更加


出现了使用Using temporary比上面Using filesort更影响效率,查询更慢
使用了临时表示非常消耗性能的,因为你创建搬数据到临时表,用完之后再把临时表回收,数据库内部要折腾一次
group by正常来讲要不别建立索引,要建立索引,grooup by一定要和索引的个数和顺序按序来,否则非常容易出现文件内排序
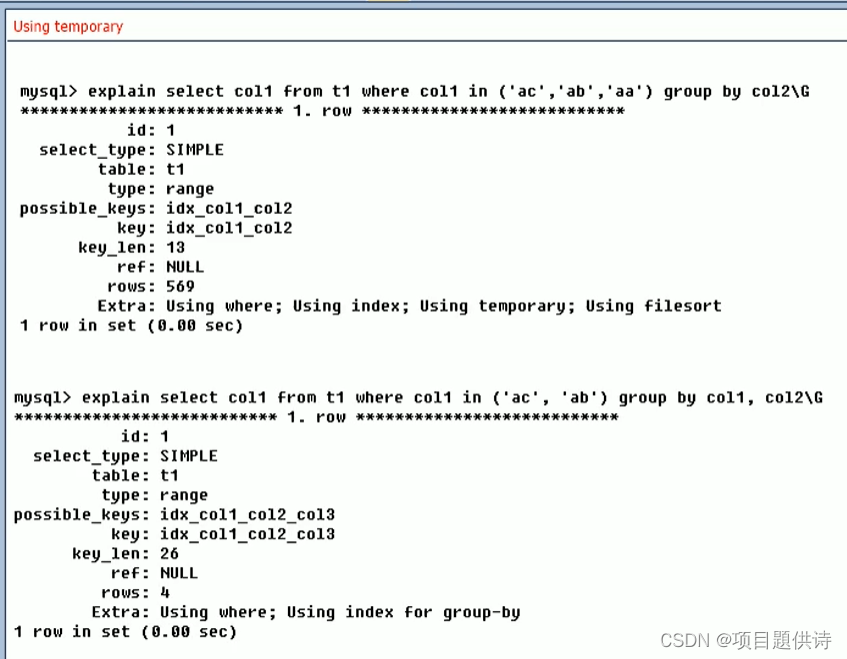

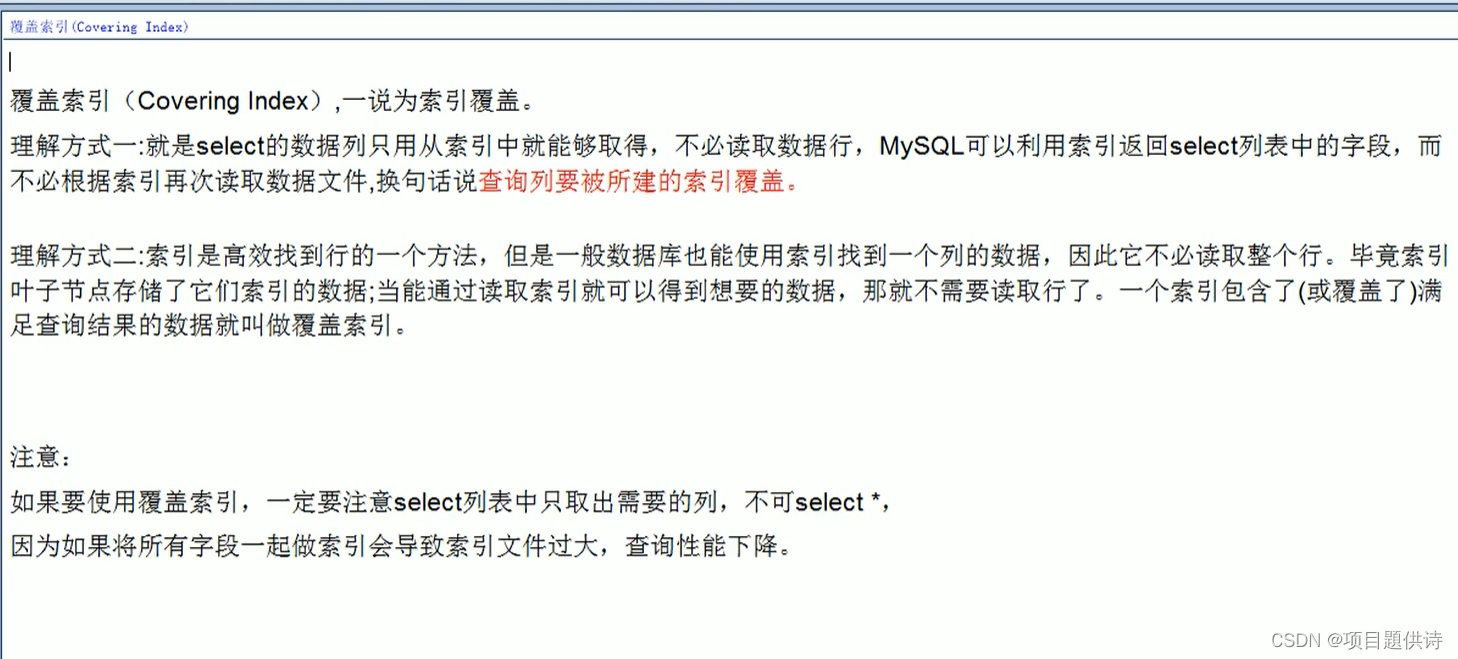
 建立的索引是一个复合索引,没有写select * ,你建立的三个字段的复合索引,正好你查询的也是这三个字段,咱们两个个数和顺序刚好匹配(或者部分满足),所以这就是覆盖索引
建立的索引是一个复合索引,没有写select * ,你建立的三个字段的复合索引,正好你查询的也是这三个字段,咱们两个个数和顺序刚好匹配(或者部分满足),所以这就是覆盖索引



比如你查询join非常多了,所以你配置文件的缓冲就可以调大一点