1、推荐系统目的
(1)帮助用户找到想要的商品(新闻/音乐/……),发掘长尾
(2)降低信息过载
(3)提高站点的点击率/转化率
(4)加深对用户的了解,为用户提供定制化服务
2、推荐算法概述
推荐算法是非常古老的,在机器学习还没有兴起的时候就有需求和应用了。概括来说,可以分为以下5种:
1)基于内容的推荐:这一类一般依赖于自然语言处理NLP的一些知识,通过挖掘文本的TF-IDF特征向量,来得到用户的偏好,进而做推荐。这类推荐算法可以找到用户独特的小众喜好,而且还有较好的解释性。这一类由于需要NLP的基础,本文就不多讲,在后面专门讲NLP的时候再讨论。
2)协调过滤推荐:本文后面要专门讲的内容。协调过滤是推荐算法中目前最主流的种类,花样繁多,在工业界已经有了很多广泛的应用。它的优点是不需要太多特定领域的知识,可以通过基于统计的机器学习算法来得到较好的推荐效果。最大的优点是工程上容易实现,可以方便应用到产品中。目前绝大多数实际应用的推荐算法都是协同过滤推荐算法。
3)混合推荐:这个类似我们机器学习中的集成学习,博才众长,通过多个推荐算法的结合,得到一个更好的推荐算法,起到三个臭皮匠顶一个诸葛亮的作用。比如通过建立多个推荐算法的模型,最后用投票法决定最终的推荐结果。混合推荐理论上不会比单一任何一种推荐算法差,但是使用混合推荐,算法复杂度就提高了,在实际应用中有使用,但是并没有单一的协调过滤推荐算法,比如逻辑回归之类的二分类推荐算法广泛。
4)基于规则的推荐:这类算法常见的比如基于最多用户点击,最多用户浏览等,属于大众型的推荐方法,在目前的大数据时代并不主流。
5)基于人口统计信息的推荐:这一类是最简单的推荐算法了,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后进行推荐,目前在大型系统中已经较少使用。
3、基于内容的推荐算法
对一个给定的用户, 推荐与他之前喜欢的项目在内容上有相似性的其他项目。这种推荐仅需要得到两类信息: 项目特征的描述和用户过去的喜好信息。
举个栗子,现在系统里有一个用户和一条新闻。通过分析用户的行为以及新闻的文本内容,我们提取出数个关键字。将这些关键字作为属性,把用户(过去的喜好)和新闻(新的内容)分解成向量。
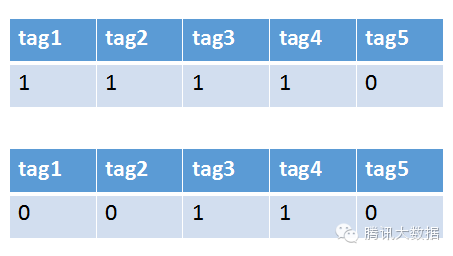
之后再计算向量距离,便可以得出该用户和新闻的相似度了,将计算相似度最大的(例如采用余弦计算)内容进行推荐。
这种方法很简单,如果在为一名热爱观看英超联赛的足球迷推荐新闻时,新闻里同时存在关键字体育、足球、英超,显然匹配前两个词都不如直接匹配英超来得准确,系统该如何体现出关键词的这种“重要性”呢?这时我们便可以引入词权的概念。在大量的语料库中通过计算(比如典型的TF-IDF算法),我们可以算出新闻中每一个关键词的权重,在计算相似度时引入这个权重的影响,就可以达到更精确的效果。sim(user, item) = 文本相似度(user, item) * 词权,将重要的词加大权重。
然而,经常接触体育新闻方面数据的同学就会要提出问题了:要是用户的兴趣是足球,而新闻的关键词是德甲、英超,按照上面的文本匹配方法显然无法将他们关联到一起。在此,我们可以引用话题聚类:利用word2vec一类工具,可以将文本的关键词聚类,然后根据topic将文本向量化,再根据topic为文本内容与用户作相似度计算。
综上,基于内容的推荐算法能够很好地解决冷启动问题,并且也不会囿于热度的限制,因为它是直接基于内容匹配的,而与浏览记录无关。然而它也会存在一些弊端,比如过度专业化(over-specialisation)的问题。这种方法会一直推荐给用户内容密切关联的item,而失去了推荐内容的多样性。